
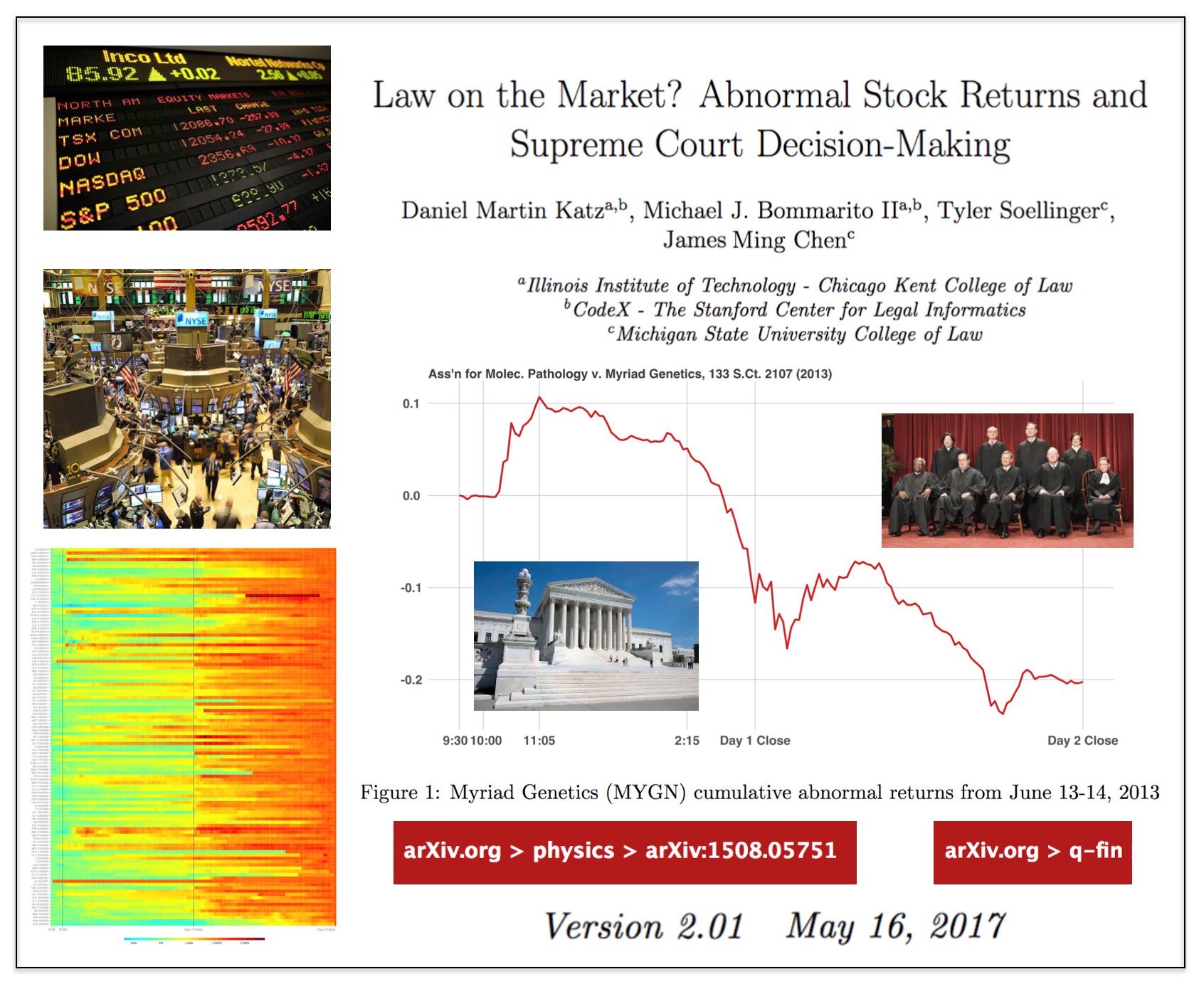
Here is Version 2.01 of the Law on the Market Paper —
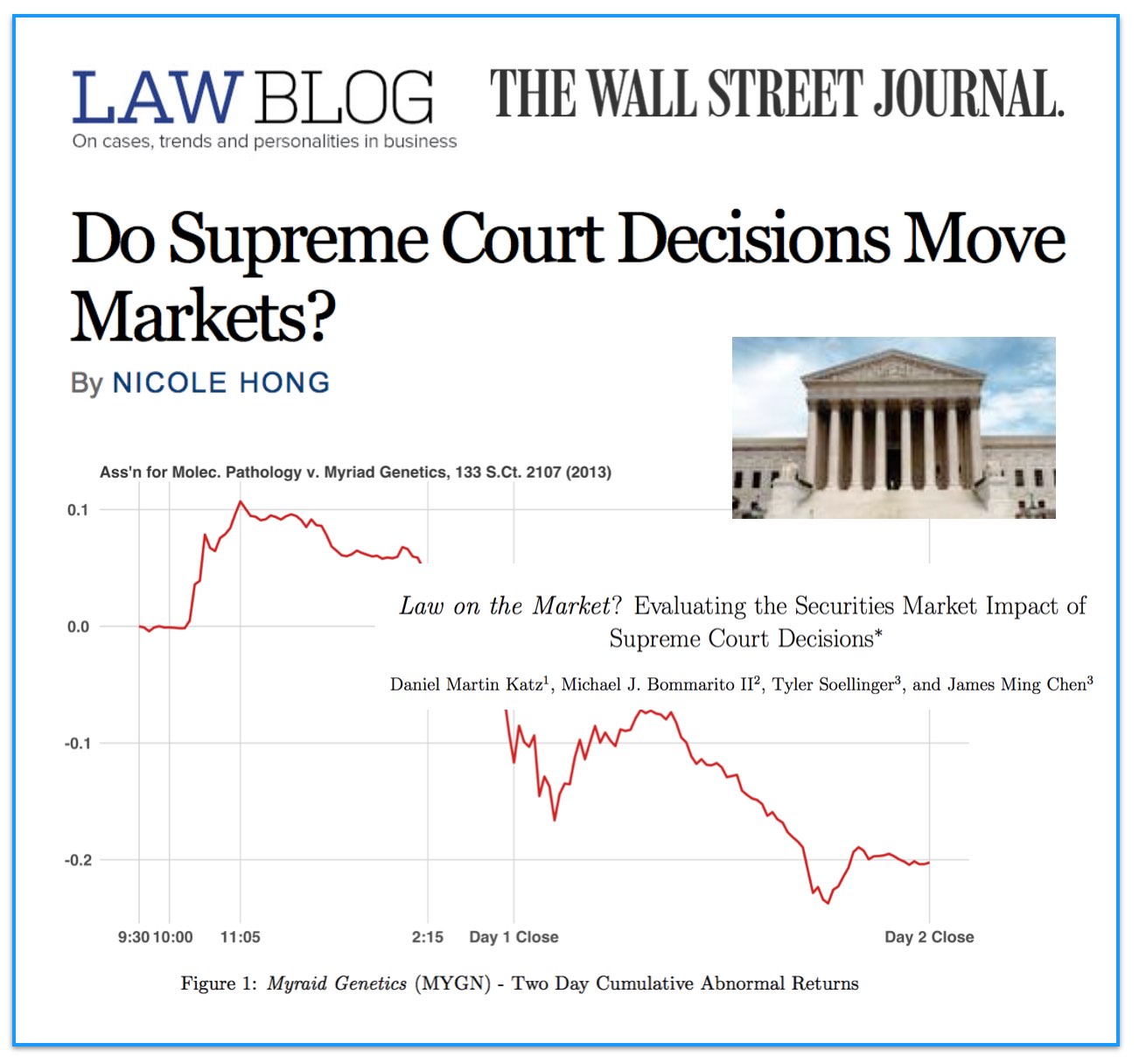
From the Abstract: What happens when the Supreme Court of the United States decides a case impacting one or more publicly-traded firms? While many have observed anecdotal evidence linking decisions or oral arguments to abnormal stock returns, few have rigorously or systematically investigated the behavior of equities around Supreme Court actions. In this research, we present the first comprehensive, longitudinal study on the topic, spanning over 15 years and hundreds of cases and firms. Using both intra- and interday data around decisions and oral arguments, we evaluate the frequency and magnitude of statistically-significant abnormal return events after Supreme Court action. On a per-term basis, we find 5.3 cases and 7.8 stocks that exhibit abnormal returns after decision. In total, across the cases we examined, we find 79 out of the 211 cases (37%) exhibit an average abnormal return of 4.4% over a two-session window with an average |t|-statistic of 2.9. Finally, we observe that abnormal returns following Supreme Court decisions materialize over the span of hours and days, not minutes, yielding strong implications for market efficiency in this context. While we cannot causally separate substantive legal impact from mere revision of beliefs, we do find strong evidence that there is indeed a “law on the market” effect as measured by the frequency of abnormal return events, and that these abnormal returns are not immediately incorporated into prices.
Tag: supreme court
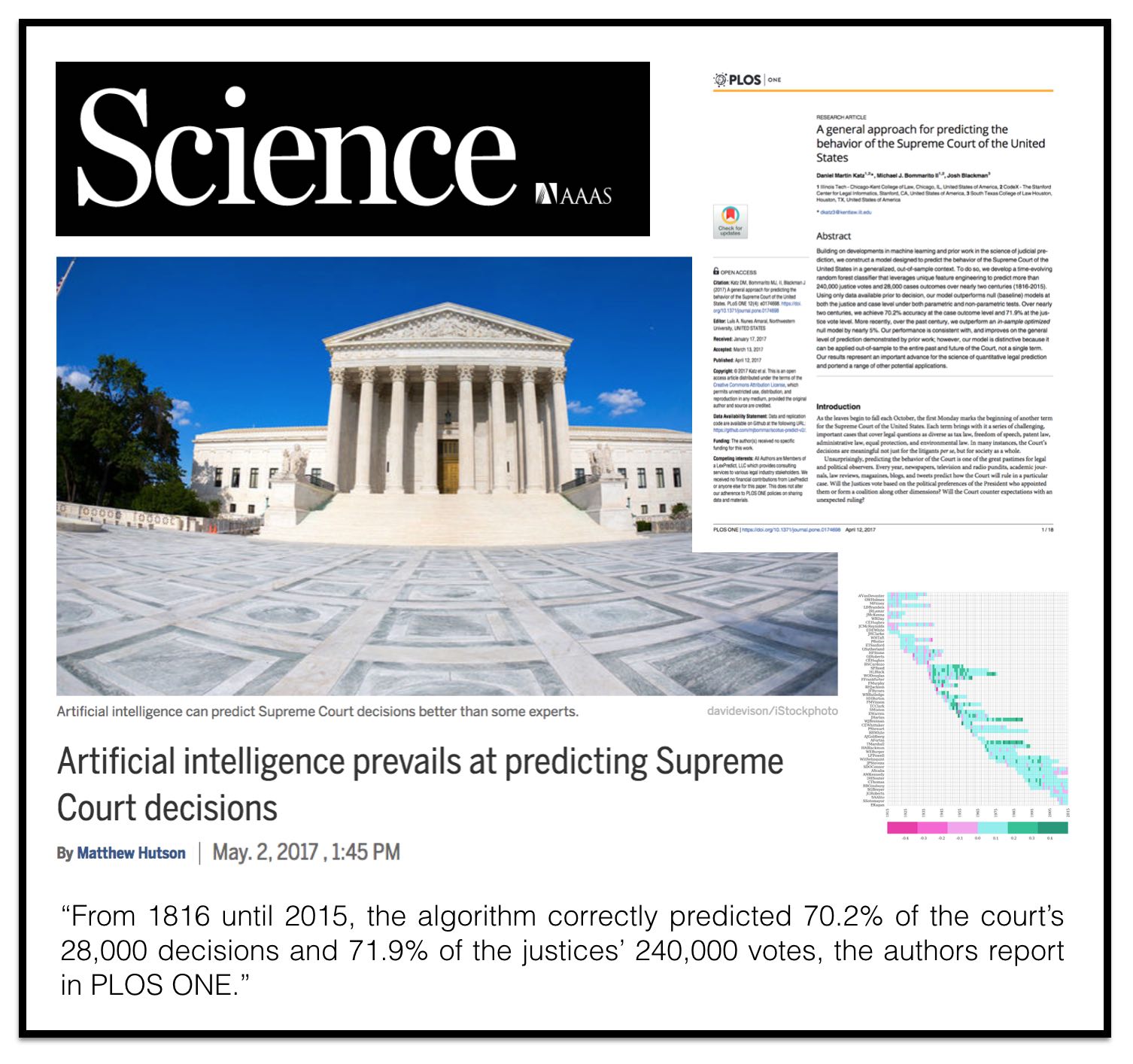
A General Approach for Predicting the Behavior of the Supreme Court of the United States (PLOS One) – Final Version April 2017
 Our SCOTUS Prediction Paper is now live in Plos One (one of my favorite journals) — very happy about this (thanks to Luís A. Nunes Amaral of Northwestern University for serving as our Editor). #OpenSourceScience #SCOTUS #LegalAnalytics #LegalData #QuantitativeLegalPrediction
Our SCOTUS Prediction Paper is now live in Plos One (one of my favorite journals) — very happy about this (thanks to Luís A. Nunes Amaral of Northwestern University for serving as our Editor). #OpenSourceScience #SCOTUS #LegalAnalytics #LegalData #QuantitativeLegalPrediction
Law on the Market? Evaluating the Securities Market Impact Of Supreme Court Decisions (Katz, Bommarito, Soellinger & Chen)
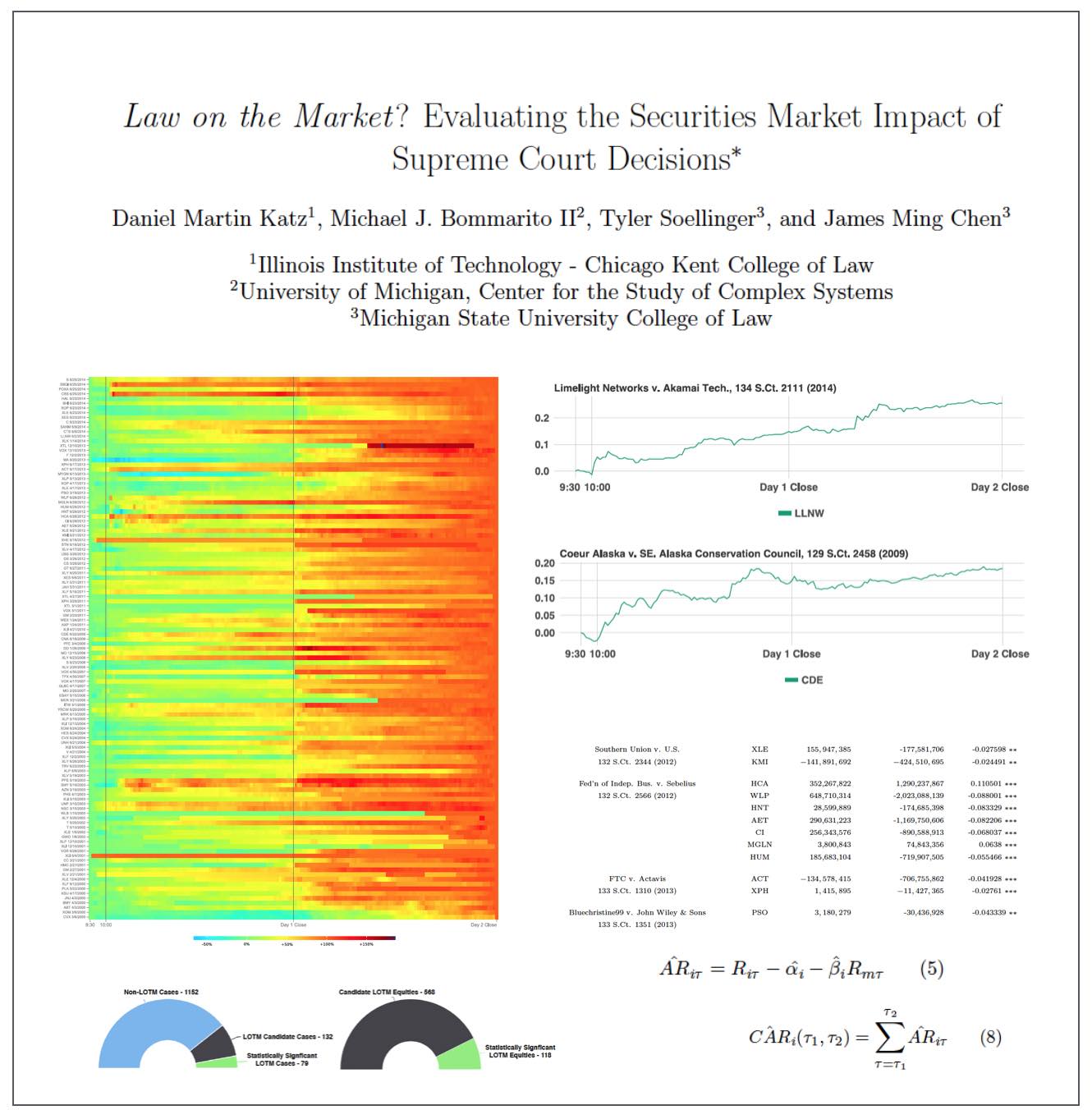
ABSTRACT: Do judicial decisions affect the securities markets in discernible and perhaps predictable ways? In other words, is there “law on the market” (LOTM)? This is a question that has been raised by commentators, but answered by very few in a systematic and financially rigorous manner. Using intraday data and a multiday event window, this large scale event study seeks to determine the existence, frequency and magnitude of equity market impacts flowing from Supreme Court decisions.
We demonstrate that, while certainly not present in every case, “law on the market” events are fairly common. Across all cases decided by the Supreme Court of the United States between the 1999-2013 terms, we identify 79 cases where the share price of one or more publicly traded company moved in direct response to a Supreme Court decision. In the aggregate, over fifteen years, Supreme Court decisions were responsible for more than 140 billion dollars in absolute changes in wealth. Our analysis not only contributes to our understanding of the political economy of judicial decision making, but also links to the broader set of research exploring the performance in financial markets using event study methods.
We conclude by exploring the informational efficiency of law as a market by highlighting the speed at which information from Supreme Court decisions is assimilated by the market. Relatively speaking, LOTM events have historically exhibited slow rates of information incorporation for affected securities. This implies a market ripe for arbitrage where an event-based trading strategy could be successful.
Available on SSRN and arXiv
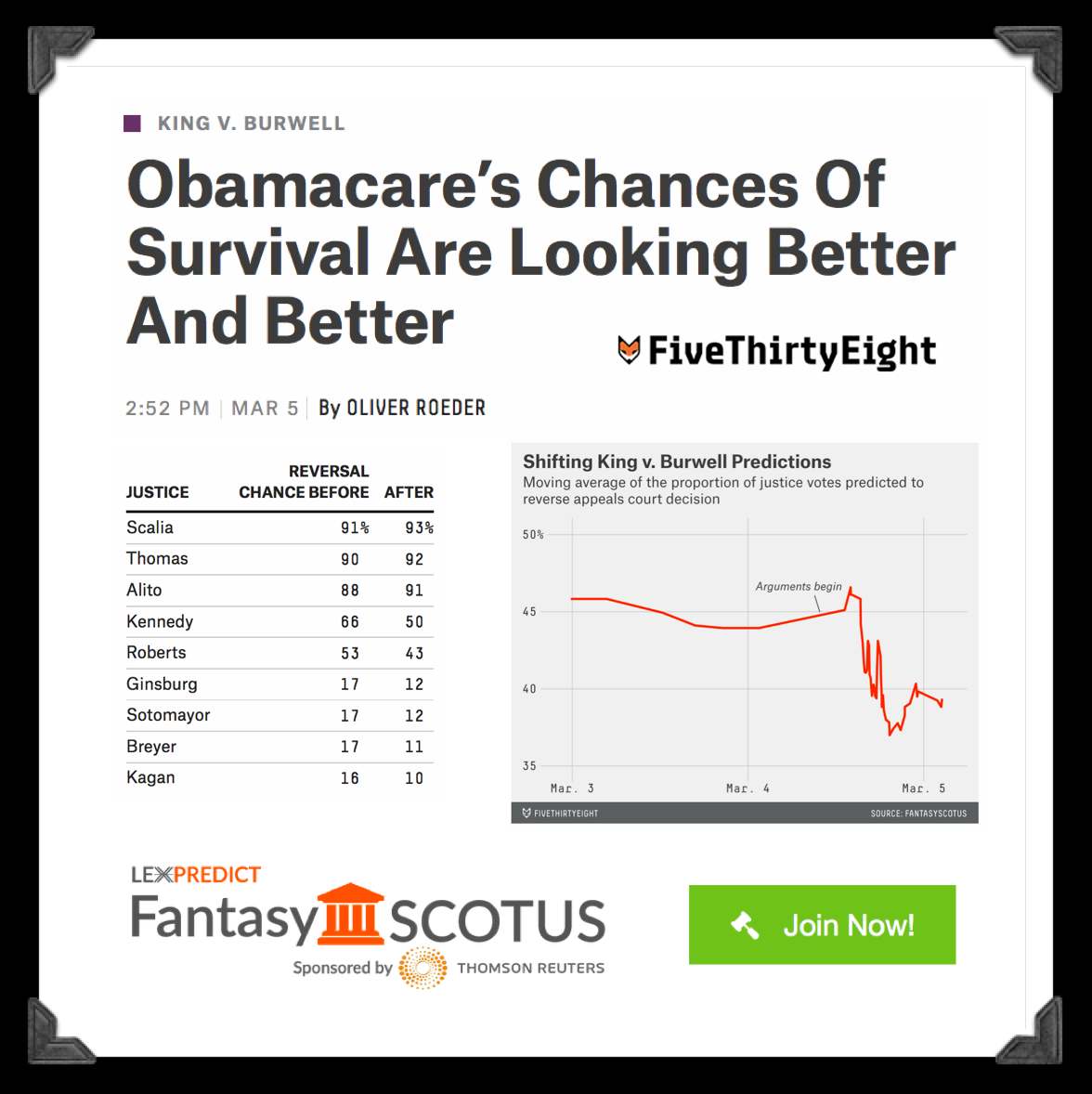
Why The Best Supreme Court Predictor In The World Is Some Random Guy In Queens (via 538.com)
 Nice coverage of the research in this area and our multi year research agenda attached to forecasting using the three known streams of intelligence (experts, crowds & algorithms).
Nice coverage of the research in this area and our multi year research agenda attached to forecasting using the three known streams of intelligence (experts, crowds & algorithms).
Computer Scientists Ask Supreme Court to Rule APIs Can’t Be Copyrighted (via EFF)
 I have filed an Amicus Brief (of sorts) via Facebook …
I have filed an Amicus Brief (of sorts) via Facebook …
Announcing the All New LexPredict FantasySCOTUS – (Sponsored By Thomson Reuters)
 Today I am excited to announce that LexPredict has now launched the all new FantasySCOTUS under the direction of Michael J. Bommarito II, Daniel Martin Katz and Josh Blackman.
Today I am excited to announce that LexPredict has now launched the all new FantasySCOTUS under the direction of Michael J. Bommarito II, Daniel Martin Katz and Josh Blackman.
FantasySCOTUS is the leading Supreme Court Fantasy League. Thousands of attorneys, law students, and other avid Supreme Court followers make predictions about cases before the Supreme Court. Participation is FREE and Supreme Court geeks can win cash prizes up to $10,000 (many other prizes as well — thanks to the generous support of Thomson Reuters).
We hope to launch additional functionality soon but we are now live and ready to accept your predictions for the 2014-2015 Supreme Court Term!
10 Predictions About How IBM’s Watson Will Impact the Legal Profession

I enjoyed collaborating with Paul Lippe for this short article in the ABA Journal New Normal column. We make 10 predictions about Watson’s application into the legal industry (some short term and some longer term) and preview some of our specific collaboration applying IBM Watson in the legal industry. Suffice to say there is much more to come …
Predicting the Behavior of the Supreme Court of the United States: A General Approach (Katz, Bommarito & Blackman)

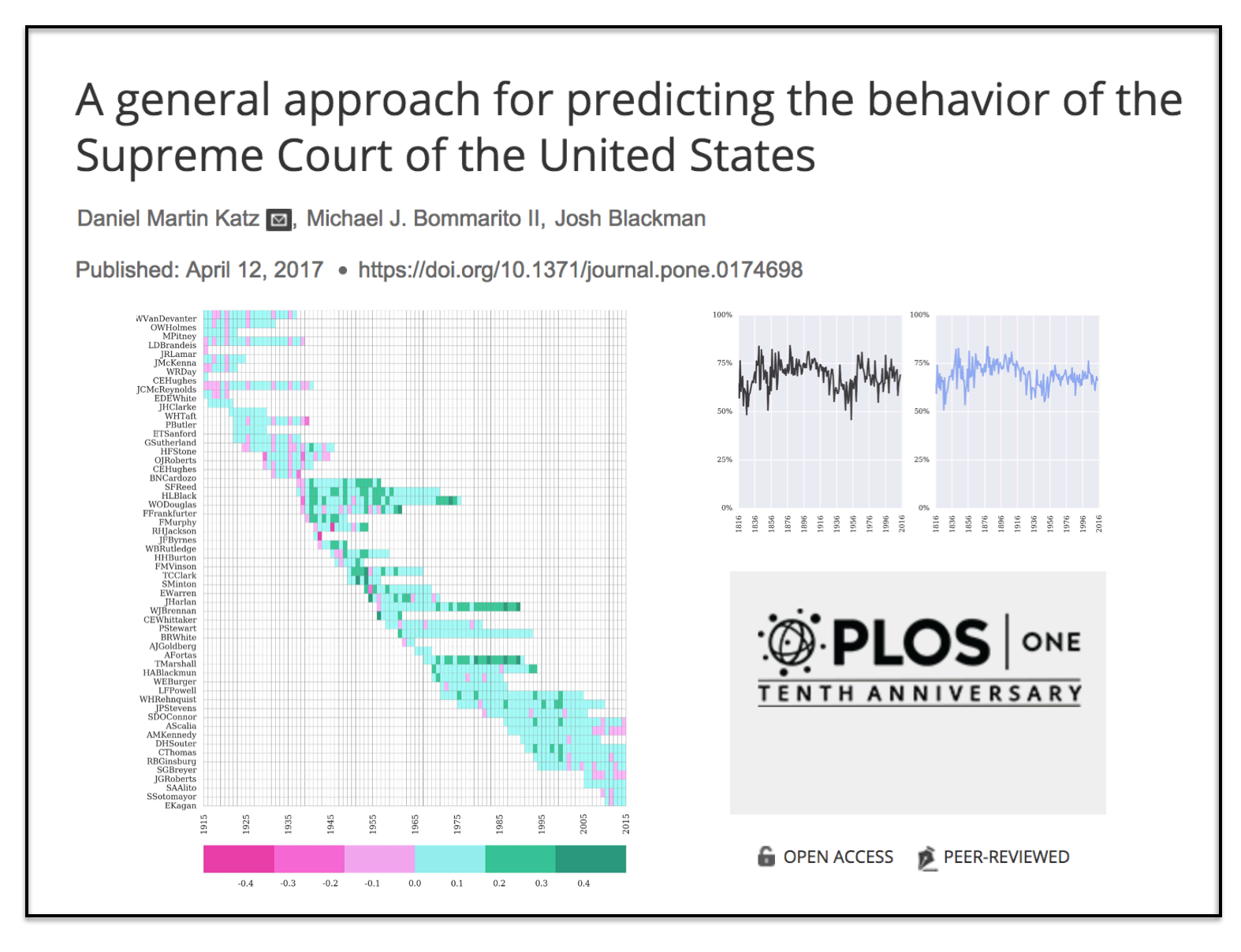
Abstract: “Building upon developments in theoretical and applied machine learning, as well as the efforts of various scholars including Guimera and Sales-Pardo (2011), Ruger et al. (2004), and Martin et al. (2004), we construct a model designed to predict the voting behavior of the Supreme Court of the United States. Using the extremely randomized tree method first proposed in Geurts, et al. (2006), a method similar to the random forest approach developed in Breiman (2001), as well as novel feature engineering, we predict more than sixty years of decisions by the Supreme Court of the United States (1953-2013). Using only data available prior to the date of decision, our model correctly identifies 69.7% of the Court’s overall affirm and reverse decisions and correctly forecasts 70.9% of the votes of individual justices across 7,700 cases and more than 68,000 justice votes. Our performance is consistent with the general level of prediction offered by prior scholars. However, our model is distinctive as it is the first robust, generalized, and fully predictive model of Supreme Court voting behavior offered to date. Our model predicts six decades of behavior of thirty Justices appointed by thirteen Presidents. With a more sound methodological foundation, our results represent a major advance for the science of quantitative legal prediction and portend a range of other potential applications, such as those described in Katz (2013).”
You can access the current draft of the paper via SSRN or via the physics arXiv. Full code is publicly available on Github. See also the LexPredict site. More on this to come soon …