
See coverage of our paper in MIT Technology Review and access paper on arXiv or SSRN

See coverage of our paper in MIT Technology Review and access paper on arXiv or SSRN

Regarding the quote above — we agree. However, it should be noted that the ‘simple substitution story’ works at the aggregate level over a period of time with the simple assumption that the tasks which comprise current jobs can be decomposed and recombined into new jobs. Certainly, institutions (both firms and public sector) will take some period of time to be able to repackage certain existing jobs. Thus, lags are to be expected. < Click Here to Access the Article >
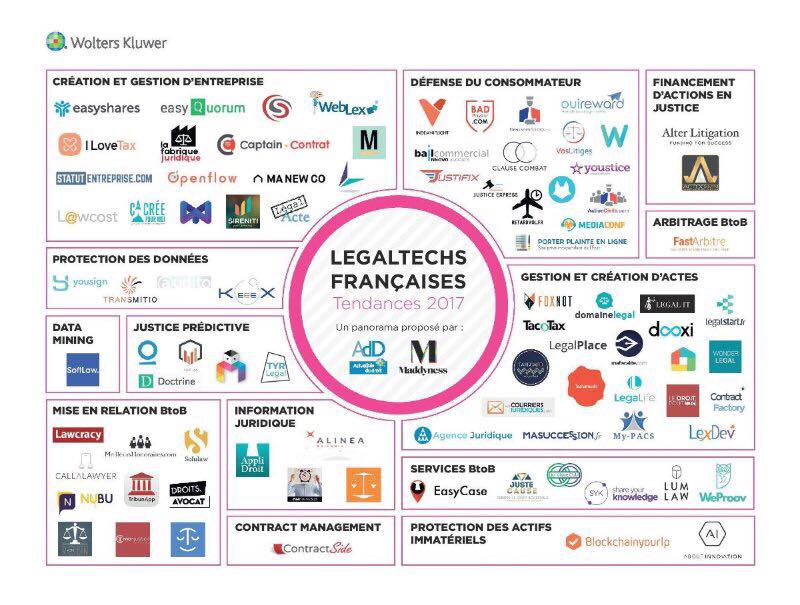 LegalTech is a global phenomena – here is the company map from France above … and below is one from Germany
LegalTech is a global phenomena – here is the company map from France above … and below is one from Germany
Here is an updated slidedeck from the presentation at the UChicago Judicial Behavior Workshop.
WENDY RUBAS (VILLAGEMD)
FROM ANECDOTE TO ANALYTICS: WAYFINDING AS A MODERN GENERAL COUNSEL
JILLIAN BOMMARITO (LEXPREDICT)
IT’S 10 PM – DO YOU KNOW WHERE YOUR LEGAL RESERVES ARE?
DENNIS KENNEDY (MASTERCARD)
AGILE LAWYERING IN THE PLATFORM ERA
EDDIE HARTMAN (LEGALZOOM)
THE PRICE IS THE PROOF
NICOLE SHANAHAN (STANFORD CODEX)
TRANSACTION COSTS AND LEGAL AI: FROM COASE’S THEOREM TO IBM WATSON, AND EVERYTHING IN BETWEEN
ED WALTERS (FASTCASE)
LAW’S FUTURE FROM FINANCE’S PAST: WHAT COULD POSSIBLY GO WRONG?

Next semester – I am looking forward to teaching Blockchain, Cryptocurrency + Law with CK alum Nelson Rosario – there is real demand for this class among our students – the class was full before registration was even complete — we have 50 students taking the class and had to turn away a number of students … #LegalTech #Blockchain #LegalInnovation #Hashtag
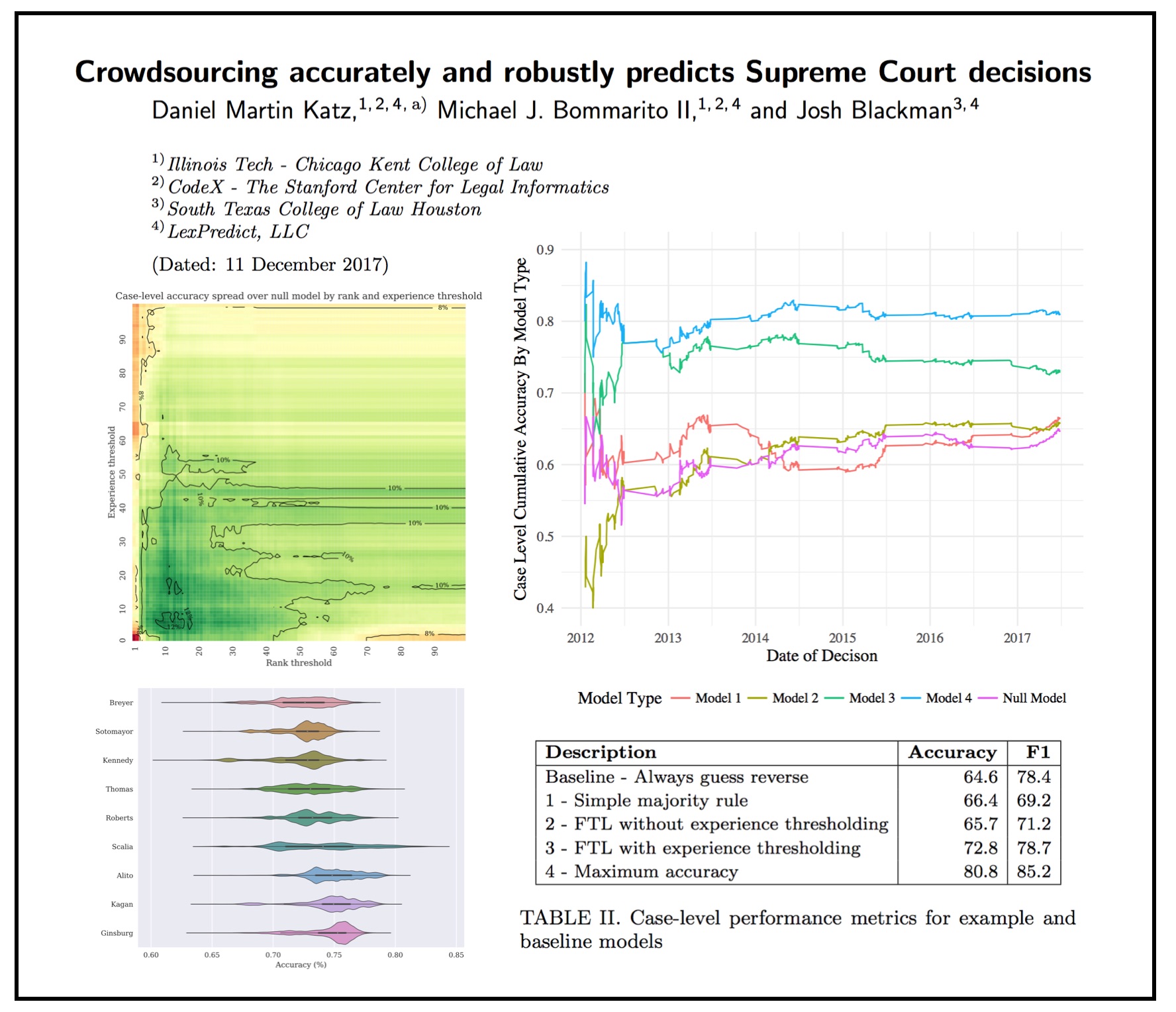
ABSTRACT: Scholars have increasingly investigated “crowdsourcing” as an alternative to expert-based judgment or purely data-driven approaches to predicting the future. Under certain conditions, scholars have found that crowd-sourcing can outperform these other approaches. However, despite interest in the topic and a series of successful use cases, relatively few studies have applied empirical model thinking to evaluate the accuracy and robustness of crowdsourcing in real-world contexts. In this paper, we offer three novel contributions. First, we explore a dataset of over 600,000 predictions from over 7,000 participants in a multi-year tournament to predict the decisions of the Supreme Court of the United States. Second, we develop a comprehensive crowd construction framework that allows for the formal description and application of crowdsourcing to real-world data. Third, we apply this framework to our data to construct more than 275,000 crowd models. We find that in out-of-sample historical simulations, crowdsourcing robustly outperforms the commonly-accepted null model, yielding the highest-known performance for this context at 80.8% case level accuracy. To our knowledge, this dataset and analysis represent one of the largest explorations of recurring human prediction to date, and our results provide additional empirical support for the use of crowdsourcing as a prediction method. (via SSRN)
 We have a paper on Abnormal Returns and Supreme Court decision making – this looks like a prime candidate for casino stocks, etc. (not a guarantee but a real possibility) — if only we had the technology to predict Supreme Court cases using methods such as crowds and algorithms 🙂
We have a paper on Abnormal Returns and Supreme Court decision making – this looks like a prime candidate for casino stocks, etc. (not a guarantee but a real possibility) — if only we had the technology to predict Supreme Court cases using methods such as crowds and algorithms 🙂



