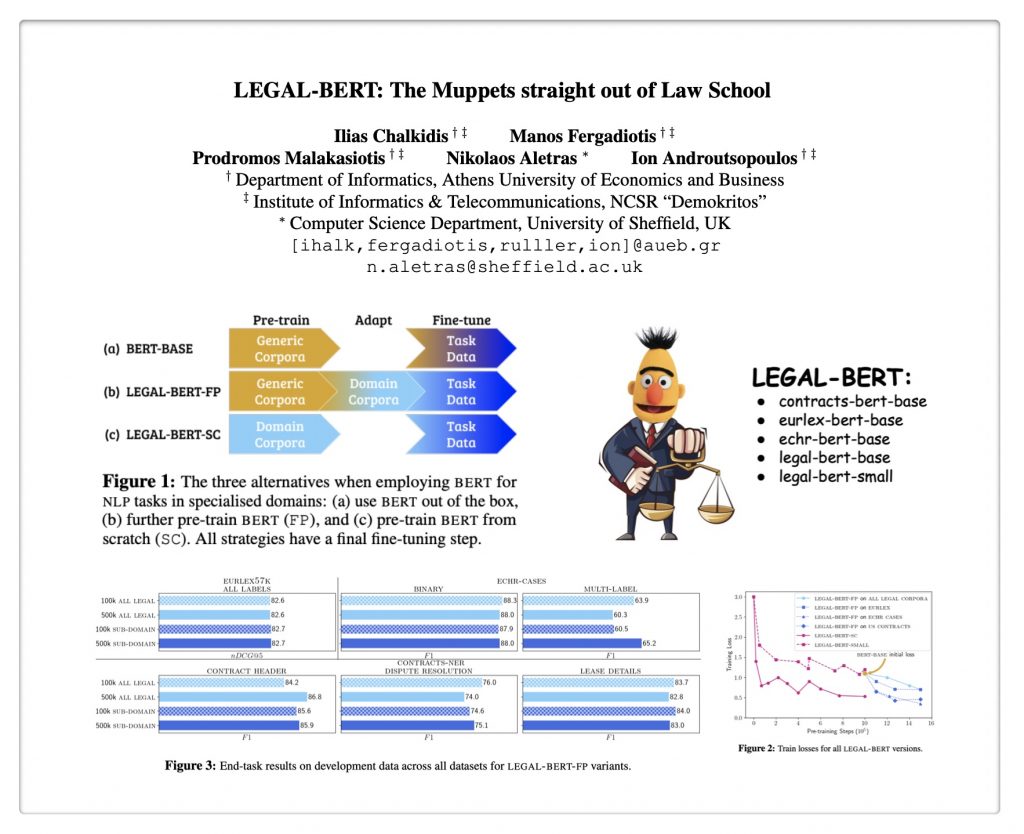
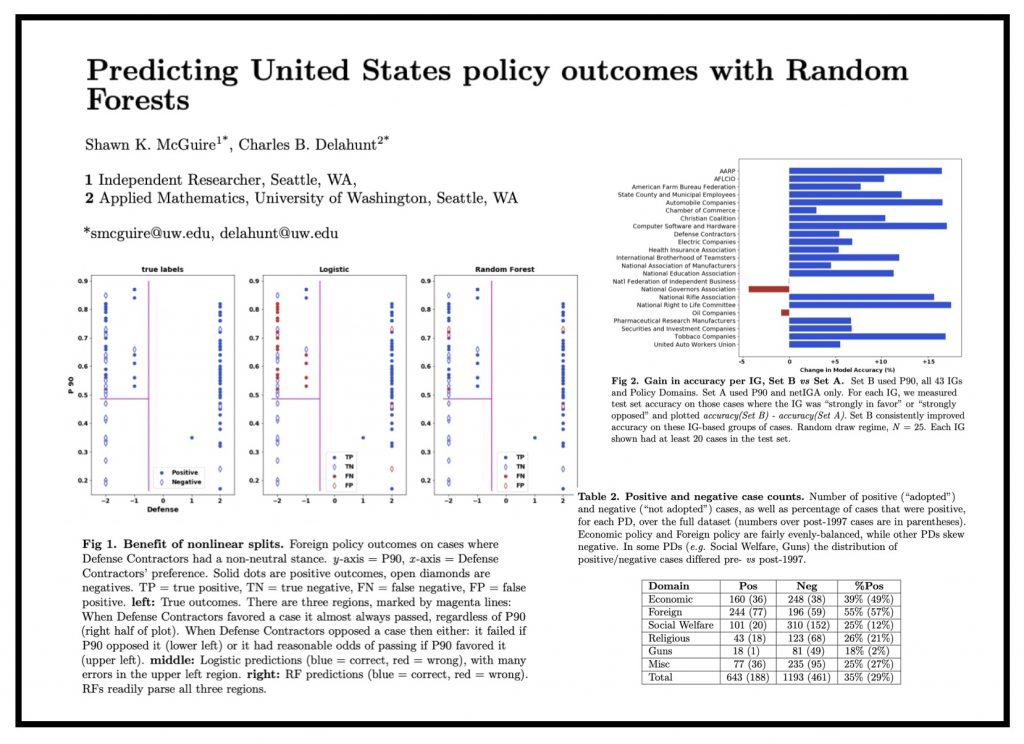
Access the Full Article via Scientific Reports (Nature Research). This article is part of a special compilation for Scientific Reports devoted to Social Physics.
ABSTRACT: While many informal factors influence how people interact, modern societies rely upon law as a primary mechanism to formally control human behaviour. How legal rules impact societal development depends on the interplay between two types of actors: the people who create the rules and the people to which the rules potentially apply. We hypothesise that an increasingly diverse and interconnected society might create increasingly diverse and interconnected rules, and assert that legal networks provide a useful lens through which to observe the interaction between law and society. To evaluate these propositions, we present a novel and generalizable model of statutory materials as multidimensional, time-evolving document networks. Applying this model to the federal legislation of the United States and Germany, we find impressive expansion in the size and complexity of laws over the past two and a half decades. We investigate the sources of this development using methods from network science and natural language processing. To allow for cross-country comparisons over time, based on the explicit cross-references between legal rules, we algorithmically reorganise the legislative materials of the United States and Germany into cluster families that reflect legal topics. This reorganisation reveals that the main driver behind the growth of the law in both jurisdictions is the expansion of the welfare state, backed by an expansion of the tax state. Hence, our findings highlight the power of document network analysis for understanding the evolution of law and its relationship with society.
It has been a real pleasure to work with my transatlantic colleagues Corinna Coupette (Max Planck Institute for Informatics), Janis Beckedorf (Heidelberg University) and Dirk Hartung (Bucerius Law School). We have other projects also in the works — so stay tuned!