
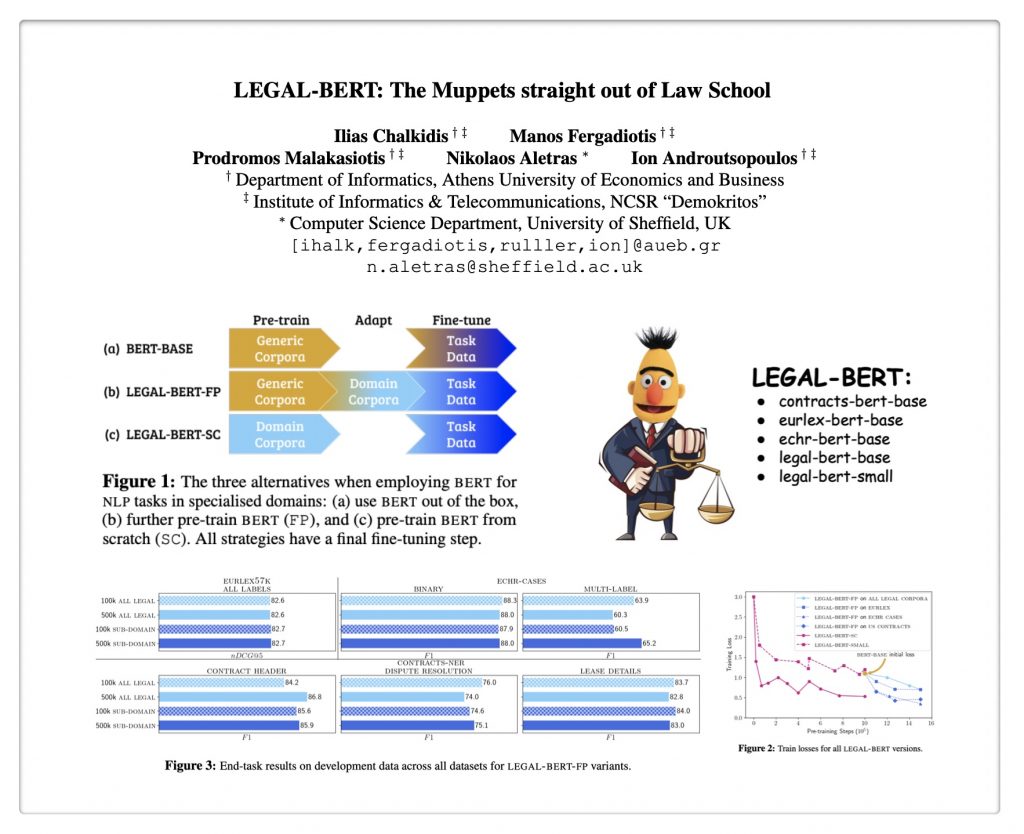
ABSTRACT: “BERT has achieved impressive performance in several NLP tasks. However, there has been limited investigation on its adaptation guidelines in specialised domains. Here we focus on the legal domain, where we explore several approaches for applying BERT models to downstream legal tasks, evaluating on multiple datasets. Our findings indicate that the previous guidelines for pre-training and fine-tuning, often blindly followed, do not always generalize well in the legal domain. Thus we propose a systematic investigation of the available strategies when applying BERT in specialised domains. These are: (a) use the original BERT out of the box, (b) adapt BERT by additional pre-training on domain-specific corpora, and (c) pre-train BERT from scratch on domain-specific corpora. We also propose a broader hyper-parameter search space when fine-tuning for downstream tasks and we release LEGAL-BERT, a family of BERT models intended to assist legal NLP research, computational law, and legal technology applications.”
Congrats to all of the authors on their acceptance in the Empirical Methods in Natural Language Processing Conference in November.
In the legal scientific community, we are witnessing increasing efforts to connect general purpose NLP Advances to domain specific applications within law. First, we saw Word Embeddings (i.e. word2Vec, etc.) now Transformers (i.e BERT, etc.). (And dont forget about GPT-3, etc.) Indeed, the development of LexNLP is centered around the idea that in order to have better performing Legal AI – we will need to connect broader NLP developments to the domain specific needs within law. Stay tuned!