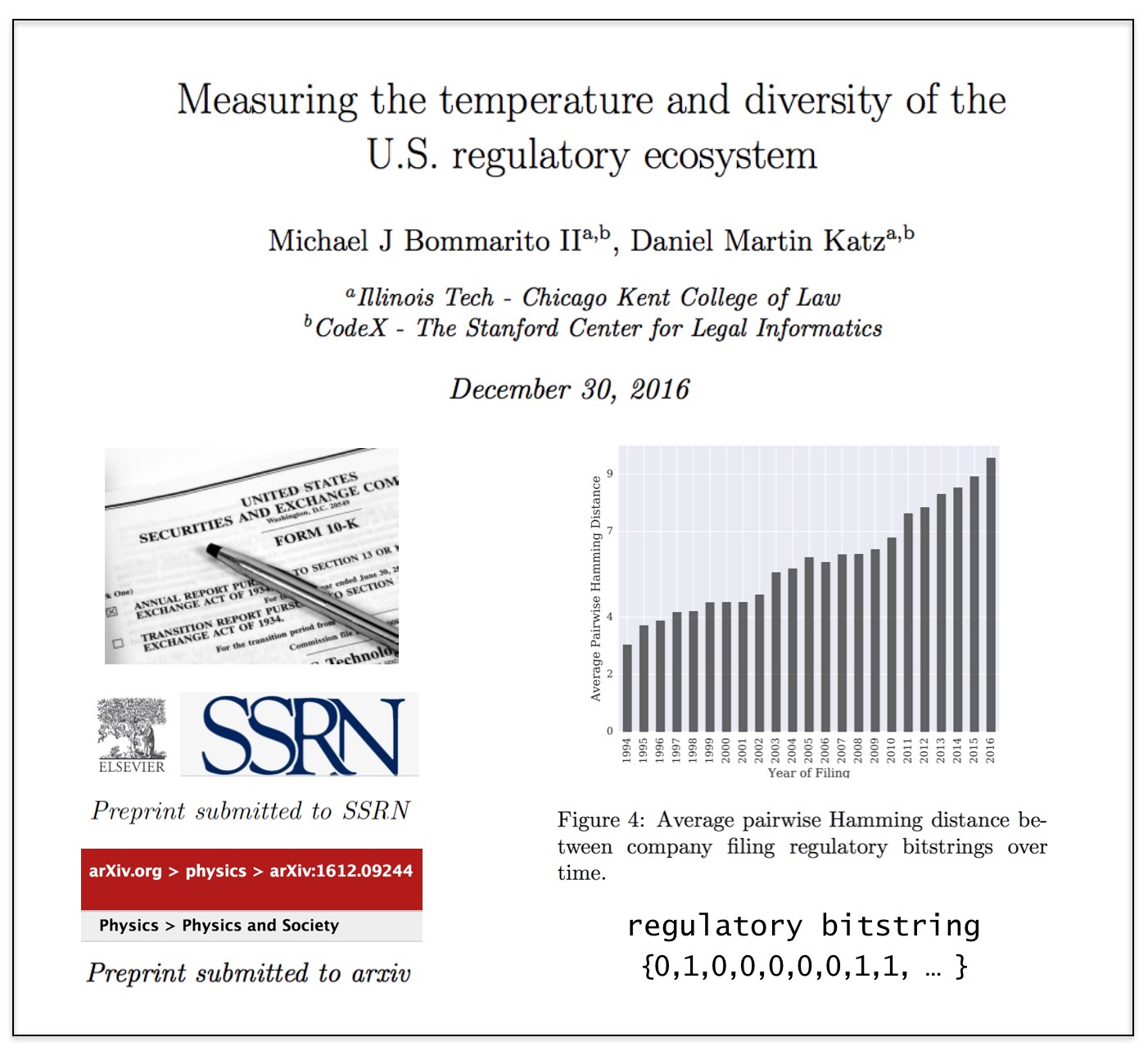
From the Abstract: Over the last 23 years, the U.S. Securities and Exchange Commission has required over 34,000 companies to file over 165,000 annual reports. These reports, the so-called “Form 10-Ks,” contain a characterization of a company’s financial performance and its risks, including the regulatory environment in which a company operates. In this paper, we analyze over 4.5 million references to U.S. Federal Acts and Agencies contained within these reports to build a mean-field measurement of temperature and diversity in this regulatory ecosystem. While individuals across the political, economic, and academic world frequently refer to trends in this regulatory ecosystem, there has been far less attention paid to supporting such claims with large-scale, longitudinal data. In this paper, we document an increase in the regulatory energy per filing, i.e., a warming “temperature.” We also find that the diversity of the regulatory ecosystem has been increasing over the past two decades, as measured by the dimensionality of the regulatory space and distance between the “regulatory bitstrings” of companies. This measurement framework and its ongoing application contribute an important step towards improving academic and policy discussions around legal complexity and the regulation of large-scale human techno-social systems.
Available in PrePrint on SSRN and on the Physics arXiv.