Over the past few years, we have hosted a number of conferences devoted to various sub-topics in legal innovation including The Make Law Better Conference, Fin Legal Tech Conference and the Block Legal Tech Conference. We have aggregated videos from these events on TheLawLabChannel.comfor you to enjoy at your convenience.
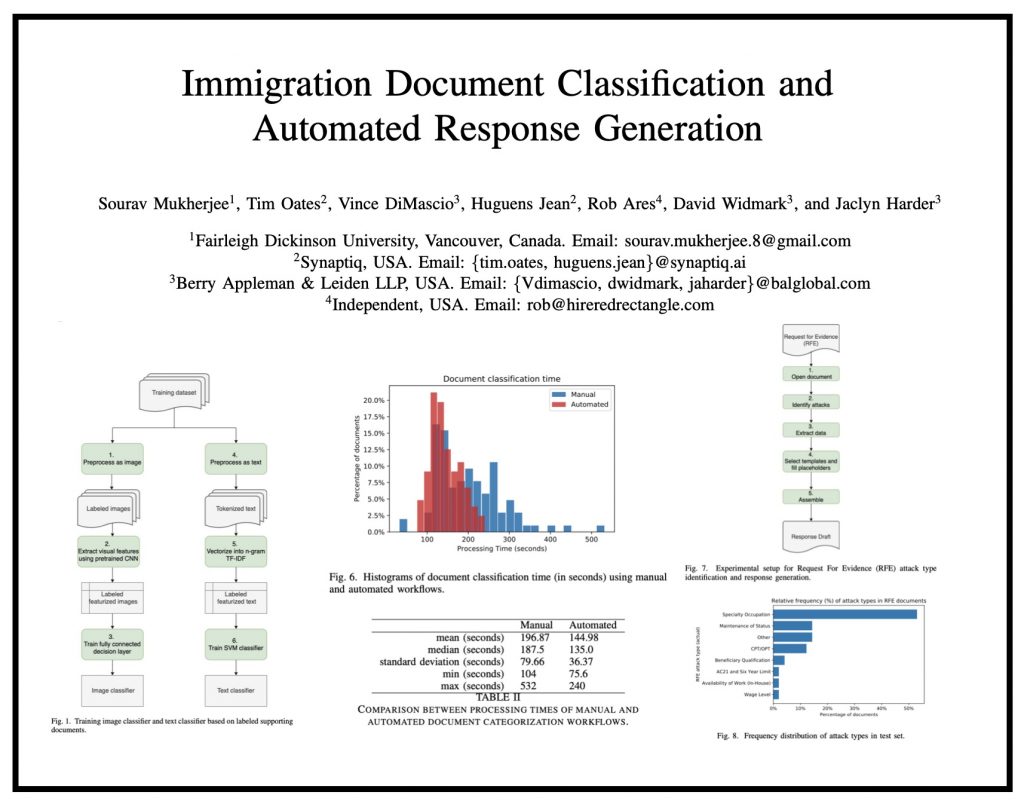
ABSTRACT: “In this paper, we consider the problem of organizing supporting documents vital to U.S. work visa petitions, as well as responding to Requests For Evidence (RFE) issued by the U.S.~Citizenship and Immigration Services (USCIS). Typically, both processes require a significant amount of repetitive manual effort. To reduce the burden of mechanical work, we apply machine learning methods to automate these processes, with humans in the loop to review and edit output for submission. In particular, we use an ensemble of image and text classifiers to categorize supporting documents. We also use a text classifier to automatically identify the types of evidence being requested in an RFE, and used the identified types in conjunction with response templates and extracted fields to assemble draft responses. Empirical results suggest that our approach achieves considerable accuracy while significantly reducing processing time.” Access Via arXiv — To Appear in ICDM 2020 workshop: MLLD-2020
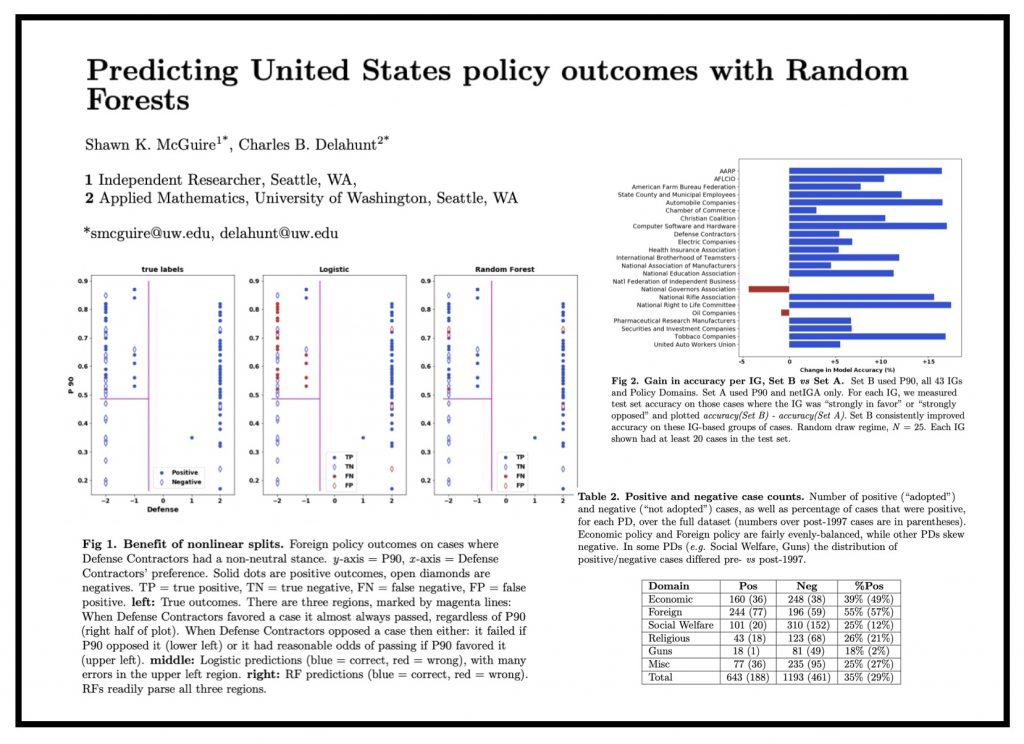
Interesting paper which follows on to a number of Machine Learning / NLP driven Legislative Prediction or Government Prediction papers. Access the draft of paper from arXiv.
For more examples, see e.g. the follow papers —
Gerrish SM, Blei DM. “Predicting legislative roll calls from text”. ICML, 2011.
Yano T, Smith NA, Wilkerson JD. “Textual Predictors of Bill Survival in Congressional Committees”. Proc 2012 Conf N Amer Chapter Assoc Comp Linguistics, Human Language Technologies, 2012.
Katz DM, Bommarito MJ, Blackman J. “A general approach for predicting the behavior of the Supreme Court of the United States”. PLOS One, 2017.
Nay, J. “Predicting and Understanding Law Making with Word Vectors and an Ensemble Model.” PLOS One, 2017.
Waltl, Bernhard Ernst. “Semantic Analysis and Computational Modeling of Legal Documents.” PhD diss., Technische Universität München, 2018.
Davoodi, Maryam, Eric Waltenburg, and Dan Goldwasser. “Understanding the Language of Political Agreement and Disagreement in Legislative Texts.” In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 5358-5368. 2020.
Lots has happened since Mike and I launched this site back in 2009 including a much larger community of folks interested in Computational Law. See the picture above from the Second Post on this blog.
We are rebooting Computational Legal Studies after a ~16 month break and back filling it with content that we have posted on other platforms such as LinkedIn, Facebook, etc.
It is good to be back pursuing the Computational Legal Agenda through this site.
We have a bunch of things in the works including our book “Legal Informatics” which is being released by Cambridge University Press in February 2021!
Spent the past few days here in Hamburg working with our multi-institutional scientific research team (Bucerius Law, Max Planck Institute, Chicago Kent Law, Heidelberg Law) … culminating in our presentation to the Bucerius Law Faculty today ! cc: Dirk HartungCorinna CoupetteJanis Beckedorf #legalinnovation #makelawbetter #legaltech #methods #legaldata #science #datascience #networkscience
Fighting off Stormtroopers so that I can moderate the AI and Law Track here at International Legal Technology Association Conference in Orlando #ILTACON19 #ILTACON2019 #legaltech #legaleducation #legalinnovation #makelawbetter
Full House for Session 1 of the AI Track at #ILTACON19 – I am Moderating each of the Four Sessions this year (see you tomorrow for Session 2) … #LegalTech #LegalAI #legaleducation #legalinnovation
Yesterday I ran the anchor leg (i.e. gave the closing Keynote) at the Artificial Intelligence and Law Summit — Hosted by the Law Society of England and Wales here in London! #LegalAI#LegalTech#LegalInnovation
Today – I gave the Opening Keynote at LawTech San Francisco Forum – co-organized by the International Finance Corporation (World Bank Group) and Hogan Lovells.
Today I am UConn Law speaking at a Conference entitled – Evaluating Litigation Risk in the 21st Century. Thanks to Alexandra Lahav and the UConn Insurance Law Center for hosting me today!