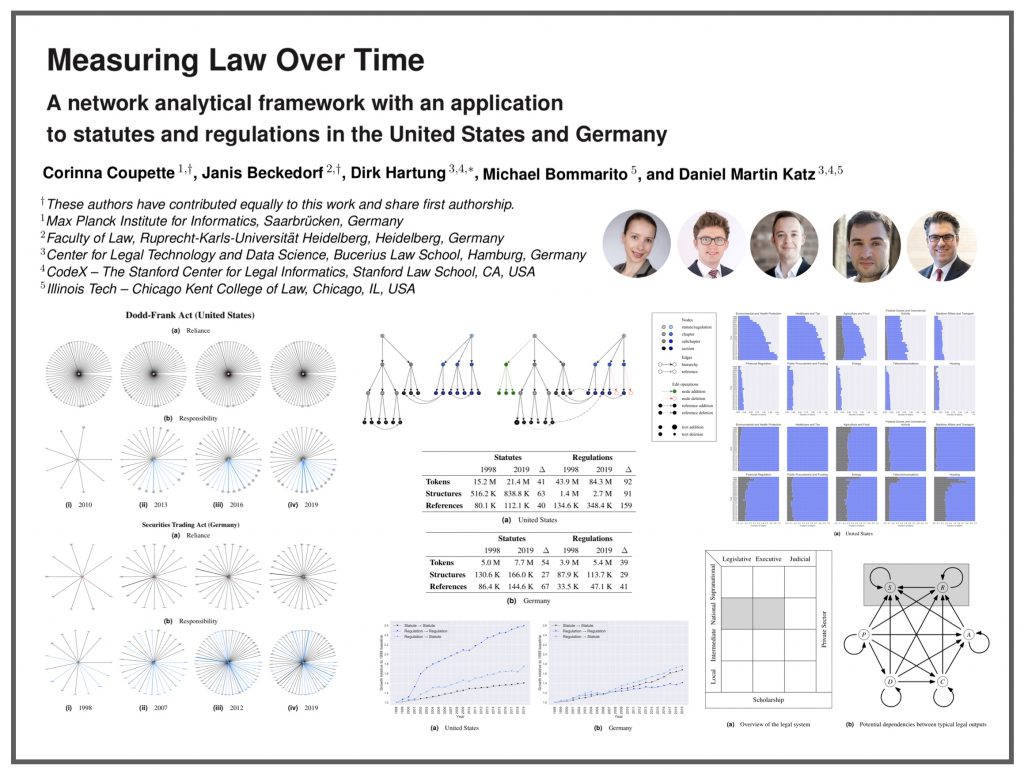
We have just posted our NEW PAPER featuring a combined dataset of network and text data which is roughly 120 MILLION words (tokens) in Size. “Measuring Law Over Time: A Network Analytical Framework with an Application to Statutes and Regulations in the United States and Germany.” Access paper draft via SSRN.
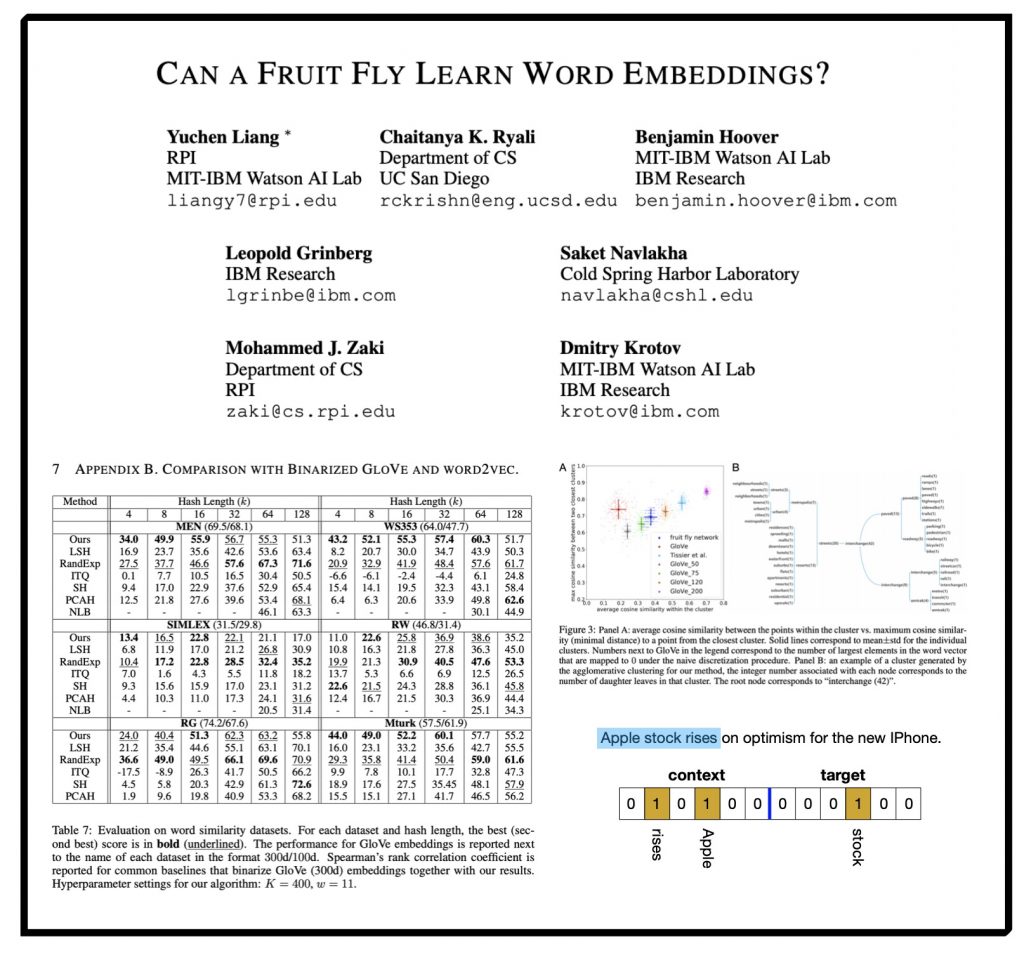
ABSTRACT: How do complex social systems evolve in the modern world? This question lies at the heart of social physics, and network analysis has proven critical in providing answers to it. In recent years, network analysis has also been used to gain a quantitative understanding of law as a complex adaptive system, but most research has focused on legal documents of a single type, and there exists no unified framework for quantitative legal document analysis using network analytical tools. Against this background, we present a comprehensive framework for analyzing legal documents as multi-dimensional, dynamic document networks. We demonstrate the utility of this framework by applying it to an original dataset of statutes and regulations from two different countries, the United States and Germany, spanning more than twenty years (1998–2019). Our framework provides tools for assessing the size and connectivity of the legal system as viewed through the lens of specific document collections as well as for tracking the evolution of individual legal documents over time. Implementing the framework for our dataset, we find that at the federal level, the American legal system is increasingly dominated by regulations, whereas the German legal system remains governed by statutes. This holds regardless of whether we measure the systems at the macro, the meso, or the micro level.
#LegalComplexity #LegalDataScience #NetworkScience #LegalAI #SocialPhysics #LegalNLP #ComplexSystems