
Month: November 2017

Applied Introduction to Machine Learning (via International Legal Technology Association Blog)

Fish & Richardson is one of the largest IP firms in the US so it is cool to see them exploring these ideas. If you look at this intro using Microsoft Azure – this is very on point with lots of we have been saying about the mix of semistructured data and #MLaaS (machine learning as a service) … and why we teach both an introduction to quant methods and a machine learning for lawyers course.
International Bar Association – President’s Task Force on the Future of Legal Services (Phase I)

I am very happy to be included among most cited scholars in the network of the INTERNATIONAL BAR ASSOCIATION – PRESIDENT’S TASK FORCE ON THE FUTURE OF LEGAL SERVICES along with John Flood, the late Larry Ribstein, Richard Susskind, Paul Lippe, Tanina Rostain, William Henderson among many others …
Revisiting Distance Measures for Dynamic Citation Networks – Published in Physica A
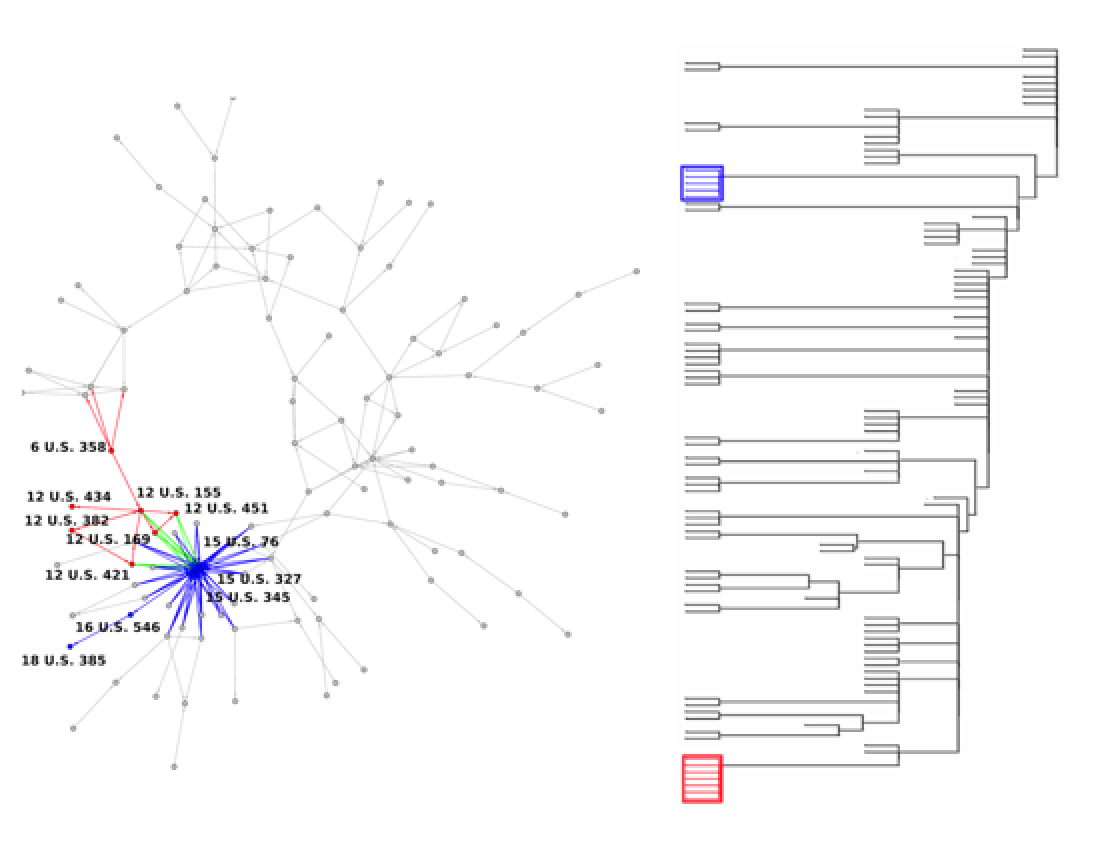
I was revisiting some of our old stuff for this Oslo event -early on for us on our #LegalPhysics #LegalAnalytics path – published in Physica A – “By applying our sink clustering method, we obtain a dendrogram of the network’s largest weakly connected component shown in Fig. 4. However, despite their general topical relatedness, these two clusters of cases engage substantively different sub-questions, and are thus appropriately divided into separate clusters. While not a major focus of the docket of the modern court, the early court elaborated a number of important legal concepts through the lens of these admiralty decisions. For example, the red group of cases engages questions of presidential power and the laws of war, as well as general interpretations of the Prize Acts of 1812. Meanwhile, the blue cluster engages questions surrounding tort liability, jurisdiction, and the burden of proof.”
Research Methods in Constitutional Law Conference – Oslo 2017
 I do not speak at many (any) con law themed events but I am happy to be part of this conversation as it is related to making con law a more scientifically inclined field of human endeavor. #Science #LegalScience #Hashtag
I do not speak at many (any) con law themed events but I am happy to be part of this conversation as it is related to making con law a more scientifically inclined field of human endeavor. #Science #LegalScience #Hashtag
Exploring the Use of Text Classication in the Legal Domain (via arXiv)
 ABSTRACT: In this paper, we investigate the application of text classication methods to support law professionals. We present several experiments applying machine learning techniques to predict with high accuracy the ruling of the French Supreme Court and the law area to which a case belongs to. We also investigate the inuence of the time period in which a ruling was made on the form of the case description and the extent to which we need to mask information in a full case ruling to automatically obtain training and test data that resembles case descriptions. We developed a mean probability ensemble system combining the output of multiple SVM classiers. We report results of 98% average F1 score in predicting a case ruling, 96% F1 score for predicting the law area of a case, and 87.07% F1 score on estimating the date of a ruling
ABSTRACT: In this paper, we investigate the application of text classication methods to support law professionals. We present several experiments applying machine learning techniques to predict with high accuracy the ruling of the French Supreme Court and the law area to which a case belongs to. We also investigate the inuence of the time period in which a ruling was made on the form of the case description and the extent to which we need to mask information in a full case ruling to automatically obtain training and test data that resembles case descriptions. We developed a mean probability ensemble system combining the output of multiple SVM classiers. We report results of 98% average F1 score in predicting a case ruling, 96% F1 score for predicting the law area of a case, and 87.07% F1 score on estimating the date of a ruling
Second Edition of The Forum on Legal Evolution – Hosted at Northwestern Law

Yesterday was the 2nd Edition of The Forum on Legal Evolution – Hosted at Northwestern University Pritzker School of Law — The Forum is comprised of legal innovators and early adopters, organized around a shared interest in the changing legal market. Paul Lippe + Mark Chandler received lifetime achievement awards. Thanks to William Henderson and his team for organizing the event!
Law on the Market – Supreme Court and Stock Market Movements – Paper Presented at University of Chicago Workshop on Judicial Behavior – Organized by Lee Epstein, Frank Easterbrook, Dennis Hutchinson, William Landes and Richard Posner
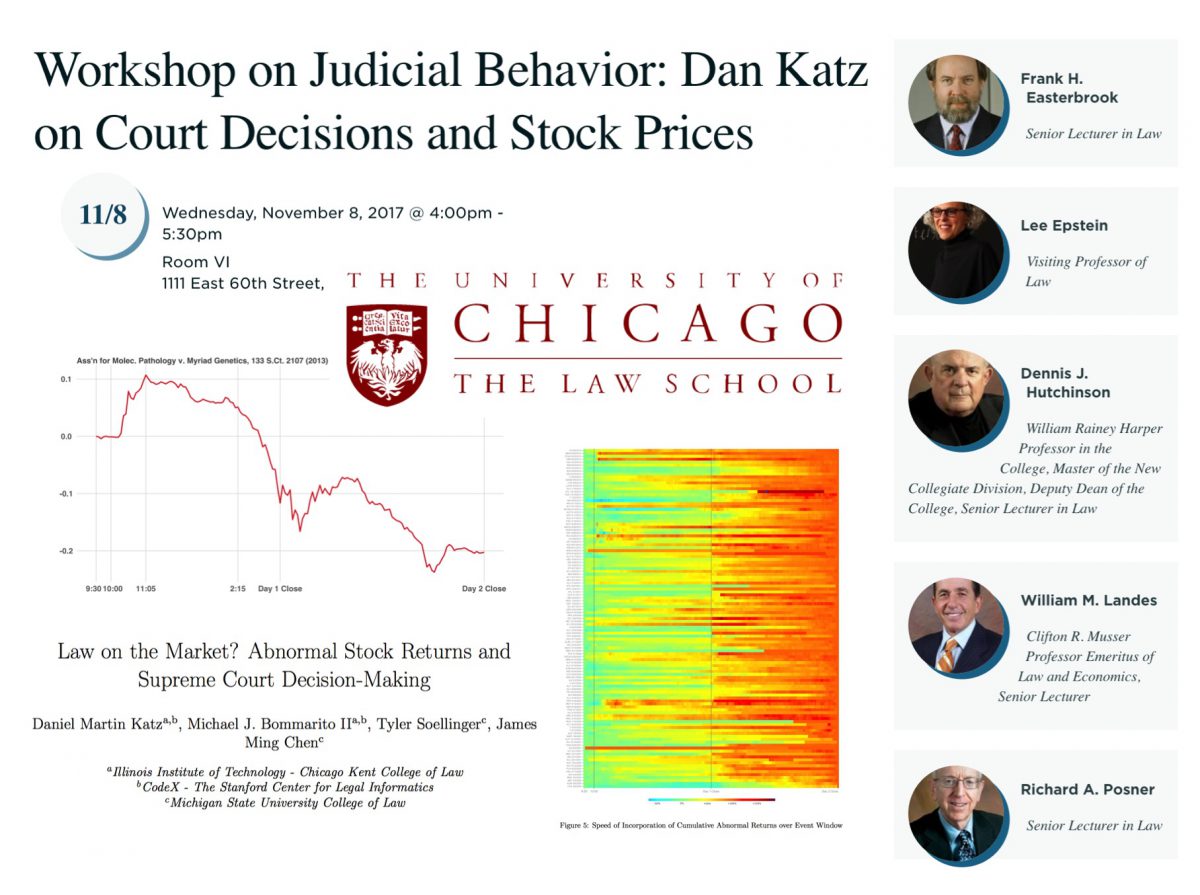 Today – on behalf of my co-authors — I presented at the University of Chicago – Workshop on Judicial Behavior – Organized by Lee Epstein, Frank Easterbrook, Dennis Hutchinson, William Landes and Richard Posner. I think we have a very appropriate UChicago styled paper on Judicial Decision Making and Stock Market Movements.
Today – on behalf of my co-authors — I presented at the University of Chicago – Workshop on Judicial Behavior – Organized by Lee Epstein, Frank Easterbrook, Dennis Hutchinson, William Landes and Richard Posner. I think we have a very appropriate UChicago styled paper on Judicial Decision Making and Stock Market Movements.
New Index Measures Law Schools on Innovation and Technology Programs (via Bob Ambrogi)
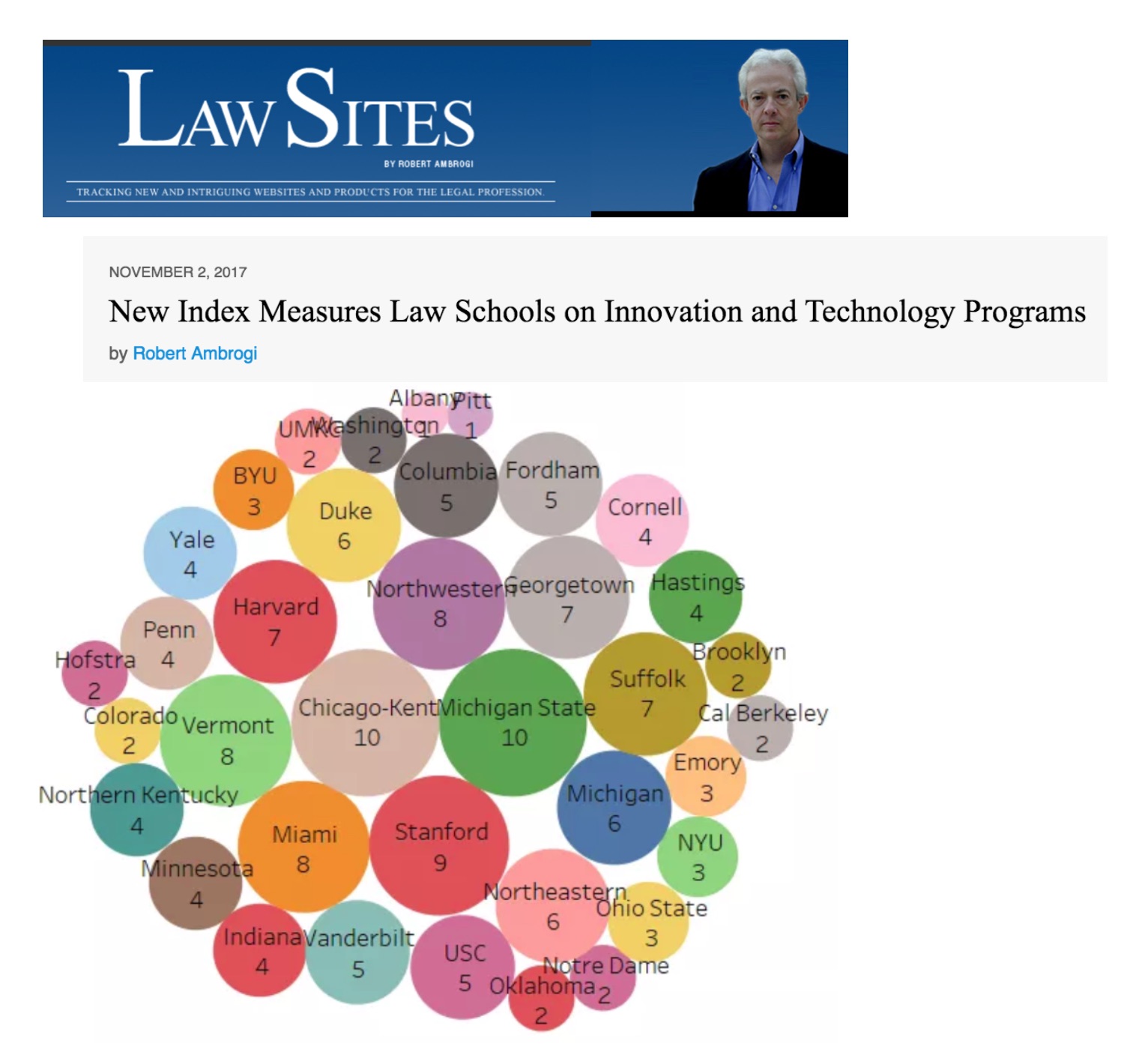
Access article here — whether or not this is precisely accurate – any measure that says The Law Lab @ Chicago Kent is #1 in Legal Innovation has to be correct 🙂

The Future of Law Schools Conference – Organized by the Thomson Reuters Legal Executive Institute

Tomorrow I will be speaking at The Future of Law Schools Conference – Organized by the Thomson Reuters Legal Executive Institute.
Here is our panel which kicks off the afternoon –
Moderator:
David Curle, Director, Market Intelligence, Thomson Reuters Legal
Panelists:
Daniel B. Rodriguez, Dean @ Northwestern Pritzker School of Law
Joseph Harroz, Dean @ University of Oklahoma
Daniel Martin Katz, Assoc. Prof @ Illinois Tech – Chicago Kent Law
Gabriel H. Teninbaum, Professor @ Suffolk University Law School
Tanina Rostain, Professor @ Georgetown Law