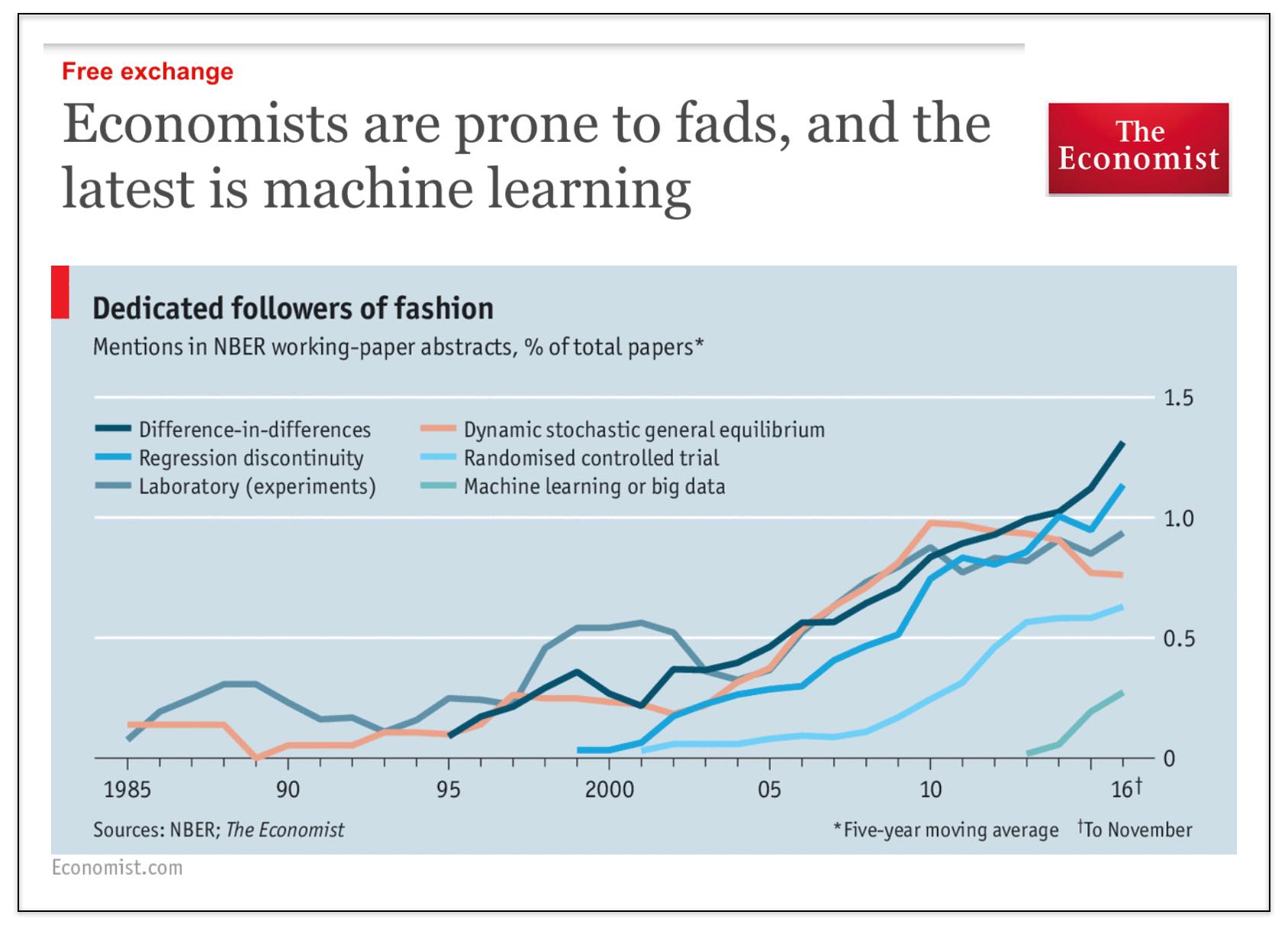
There is likely to be lots of recriminations in the pollster space but I think one thing is pretty clear — there was not enough uncertainty in the various methods of poll aggregation.
I will highlight the Huffington Post (Huff Po) model because they had such hubris about their approach. Indeed, Ryan Grimm wrote an attempted attack piece on the 538 model which stated “Silver is making a mockery of the very forecasting industry that he popularized.” (Turns out his organization was the one making the mockery)
Nate Silver responded quite correctly that this Huff Po article is “so fucking idiotic and irresponsible.” And it was indeed.
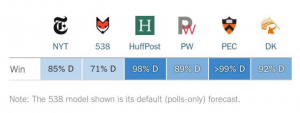
Even after the election Huff Po is out there trying to characterize it as a black swan event. It is *not* a black swan event. Far from it … and among the major poll aggregators Five Thirty Eight was the closest because they had more uncertainty (which turns out was quite appropriate). Specifically, the uncertainty that cascaded through 538’s model was truthful … and just because it resulted in big bounds didn’t mean that it was a bad model, because the reality is that the system in question was intrinsically unpredictable / stochastic.
From the 538 article cited above “Our finding, consistently, was that it was not very robust because of the challenges Clinton faced in the Electoral College, especially in the Midwest, and therefore our model gave a much better chance to Trump than other forecasts did.”
Take a look again at the justification (explanation) from the Huffington Post: “The model structure wasn’t the problem. The problem was that the data going into the model turned out to be wrong in several key places.”
Actually the model structure was the problem in so much as any aggregation model should try to characterize (in many ways) the level of uncertainty associated with a particular set of information that it is leveraging.
Poll aggregation (or any sort of crowd sourcing exercise) is susceptible to systemic bias. Without sufficient diversity of inputs, boosting and related methodological approaches are *not* able to remove systematic bias. However, one can build a meta-meta model whereby one attempts to address the systemic bias after undertaking the pure aggregation exercise.
So what is the chance that a set of polls have systematic error such that the true preferences of a group of voters is not reflected? Could their be a Bradley type effect? How much uncertainty should that possibility impose on our predictions? These were the questions that needed better evaluation pre-election.
It is worth noting that folks were aware of the issue in theory but most of them discounted it to nearly zero. Remember this piece in Vanity Fair which purported to debunk the Myth of the Secret Trump Voter (which is the exact systematic bias that appeared to undermine most polls)?
Let us look back to the dynamics of this election. There was really no social stigma associated with voting for Hillary Clinton (in most social circles) and quite a bit (at least in certain social circles) with voting for Trump.
So while this is a set back for political science, I am hoping what comes from all of this is better science in this area (not a return to data free speculation (aka pure punditry)).
P.S. Here is one more gem from the pre-election coverage – Election Data Hero Isn’t Nate Silver. It’s Sam Wang (the Princeton Professor had HRC at more than a 99% chance of winning). Turns out this was probably the worst performing model because it has basically zero model meta-uncertainty.