
Tag: artificial intelligence and law
Over 100 Videos on Legal Innovation Now Available at TheLawLabChannel.com
Over the past few years, we have hosted a number of conferences devoted to various sub-topics in legal innovation including The Make Law Better Conference, Fin Legal Tech Conference and the Block Legal Tech Conference. We have aggregated videos from these events on TheLawLabChannel.com for you to enjoy at your convenience.
Data Science & Machine Learning in Containers (or Ad Hoc vs Enterprise Grade Data Products)

As Mike Bommarito, Eric Detterman and I often discuss – one of the consistent themes in the Legal Tech / Legal Analytics space is the disconnect between what might be called ‘ad hoc’ data science and proper enterprise grade products / approaches (whether B2B or B2C). As part of the organizational maturity process, many organizations who decide that they must ‘get data driven’ start with an ad hoc approach to leveraging doing data science. Over time, it then becomes apparent that a more fundamental and robust undertaking is what is actually needed.
Similar dynamics also exist within the academy as well. Many of the code repos out there would not be considered proper production grade data science pipelines. Among other things, this makes deployment, replication and/or extension quite difficult.
Anyway, this blog post from Neptune.ai outlines just some of these issues.
Immigration Document Classification and Automated Response Generation
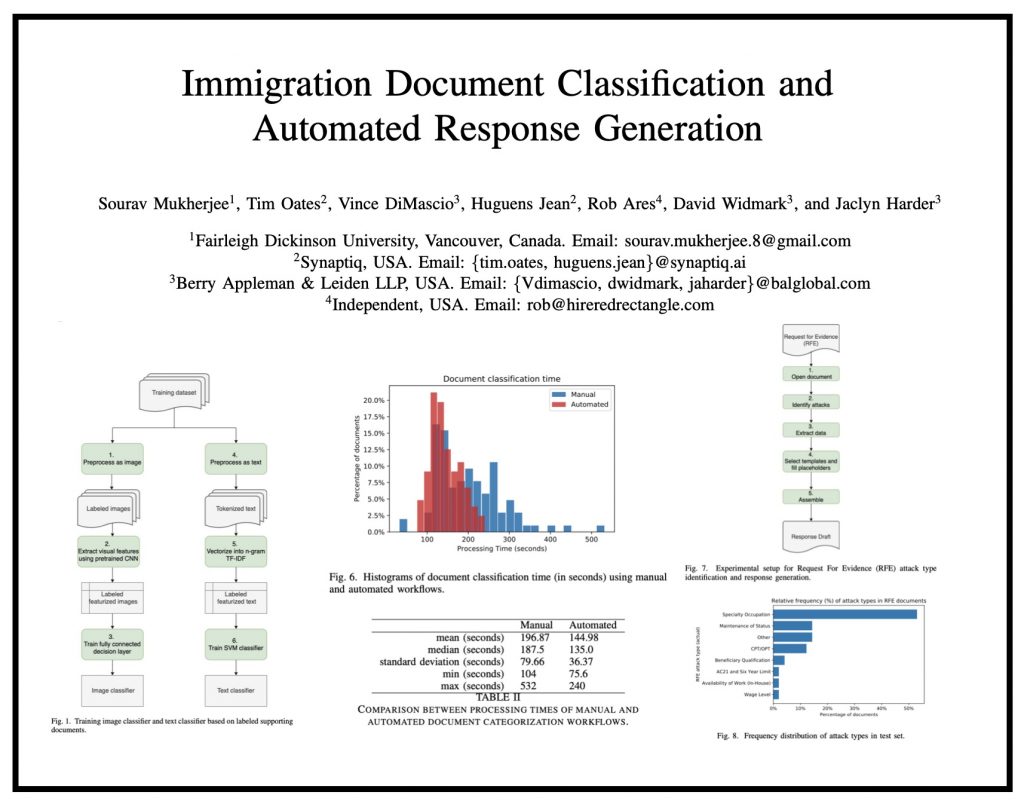
ABSTRACT: “In this paper, we consider the problem of organizing supporting documents vital to U.S. work visa petitions, as well as responding to Requests For Evidence (RFE) issued by the U.S.~Citizenship and Immigration Services (USCIS). Typically, both processes require a significant amount of repetitive manual effort. To reduce the burden of mechanical work, we apply machine learning methods to automate these processes, with humans in the loop to review and edit output for submission. In particular, we use an ensemble of image and text classifiers to categorize supporting documents. We also use a text classifier to automatically identify the types of evidence being requested in an RFE, and used the identified types in conjunction with response templates and extracted fields to assemble draft responses. Empirical results suggest that our approach achieves considerable accuracy while significantly reducing processing time.” Access Via arXiv — To Appear in ICDM 2020 workshop: MLLD-2020
LEGAL-BERT: The Muppets Straight Out of Law School
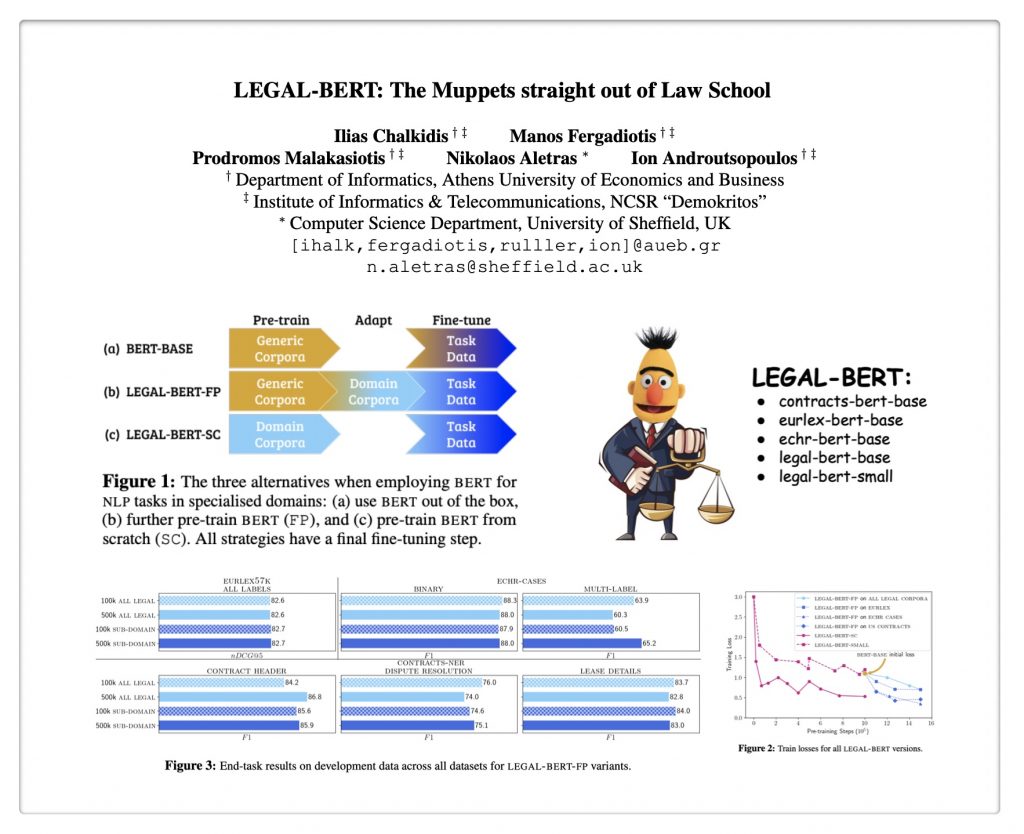
ABSTRACT: “BERT has achieved impressive performance in several NLP tasks. However, there has been limited investigation on its adaptation guidelines in specialised domains. Here we focus on the legal domain, where we explore several approaches for applying BERT models to downstream legal tasks, evaluating on multiple datasets. Our findings indicate that the previous guidelines for pre-training and fine-tuning, often blindly followed, do not always generalize well in the legal domain. Thus we propose a systematic investigation of the available strategies when applying BERT in specialised domains. These are: (a) use the original BERT out of the box, (b) adapt BERT by additional pre-training on domain-specific corpora, and (c) pre-train BERT from scratch on domain-specific corpora. We also propose a broader hyper-parameter search space when fine-tuning for downstream tasks and we release LEGAL-BERT, a family of BERT models intended to assist legal NLP research, computational law, and legal technology applications.”
Congrats to all of the authors on their acceptance in the Empirical Methods in Natural Language Processing Conference in November.
In the legal scientific community, we are witnessing increasing efforts to connect general purpose NLP Advances to domain specific applications within law. First, we saw Word Embeddings (i.e. word2Vec, etc.) now Transformers (i.e BERT, etc.). (And dont forget about GPT-3, etc.) Indeed, the development of LexNLP is centered around the idea that in order to have better performing Legal AI – we will need to connect broader NLP developments to the domain specific needs within law. Stay tuned!
Predicting United States Policy Outcomes with Random Forests (via arXiv)
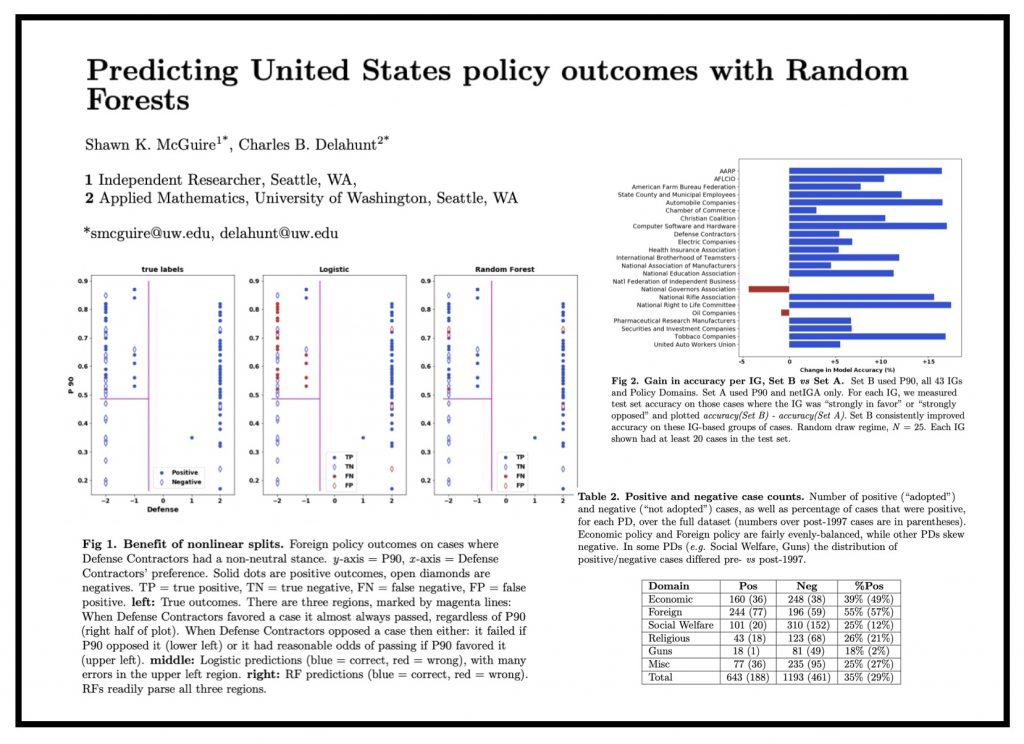
Interesting paper which follows on to a number of Machine Learning / NLP driven Legislative Prediction or Government Prediction papers. Access the draft of paper from arXiv.
For more examples, see e.g. the follow papers —
Gerrish SM, Blei DM. “Predicting legislative roll calls from text”. ICML, 2011.
Yano T, Smith NA, Wilkerson JD. “Textual Predictors of Bill Survival in Congressional Committees”. Proc 2012 Conf N Amer Chapter Assoc Comp Linguistics, Human Language Technologies, 2012.
Katz DM, Bommarito MJ, Blackman J. “A general approach for predicting the
behavior of the Supreme Court of the United States”. PLOS One, 2017.
Nay, J. “Predicting and Understanding Law Making with Word Vectors and an Ensemble Model.” PLOS One, 2017.
Waltl, Bernhard Ernst. “Semantic Analysis and Computational Modeling of Legal Documents.” PhD diss., Technische Universität München, 2018.
Davoodi, Maryam, Eric Waltenburg, and Dan Goldwasser. “Understanding the Language of Political Agreement and Disagreement in Legislative Texts.” In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 5358-5368. 2020.
How Humans Judge Machines Launch Event

How Humans Judge Machines compares people’s reactions to human and machine actions across dozens of experiments, revealing when and why humans are biased in favor or against machines. The Digital Version is Free and available as of today. Obviously, should not judge book by cover but it looks to be an interesting book.
Computational Legal Studies Rebooted !

Lots has happened since Mike and I launched this site back in 2009 including a much larger community of folks interested in Computational Law. See the picture above from the Second Post on this blog.
We are rebooting Computational Legal Studies after a ~16 month break and back filling it with content that we have posted on other platforms such as LinkedIn, Facebook, etc.
It is good to be back pursuing the Computational Legal Agenda through this site.
We have a bunch of things in the works including our book “Legal Informatics” which is being released by Cambridge University Press in February 2021!
Best,
Daniel Martin Katz & Michael Bommarito
GPT-3 and Another Chat About the End of Lawyers

Today I was Quoted in LegalIT Insider discussing GPT-3 and what it might mean for the future of Legal Tech / Legal AI … “There a few demos out there which look promising (but lots of things look good in a demo but are not robust in the end). I think the open question is always to what extent we can project any general advance in NLP to the domain specific challenges here in law-law land … On the positive side, I think every major and even minor advances present opportunities for us here in legal. It took a while but for example you see many of the products in our space taking advantage of Word Embedding [or transformer] methods (Word2Vec, BERT, ELMo, etc.)”
Introductory Pre Session of the Bucerius Legal Tech Essentials
Yesterday we had our Introductory Pre Session of the Bucerius Legal Tech Essentials … the video for our intro session in now available on YouTube (see video above).
The official first session begins in earnest Monday June 29th Noon US Central / 700pm CEST. It is not too late to join us if you still want to sign up for FREE — https://techsummer.law-school.de/
And the conversation continues at #BuceriusLegalTech …
See you on Monday !
Bucerius Legal Tech Essentials – Are You Ready?
ARE YOU READY? Bucerius Legal Tech Essentials starts this week with our Intro Session on Thursday (regular sessions begin on Monday June 29th) … Over 3200+ Participants from 90+ Countries and the Conversation continues at #BuceriusLegalTech …
You can still Sign up today for FREE — https://techsummer.law-school.de/
Thanks as always to Baker McKenzie for Sponsoring and thank you to our global academic and organizational partners (Stanford CodeX, Chicago Kent & European Legal Technology Association) !
Dirk Hartung and I also would like to also thank our Confirmed Lecturers — Roland Vogl Janis Beckedorf Alma Asay Liam Brown David Perla Daniel W. Linna Jr. Gloria Sanchez J.B. Ruhl How Khang Lim William Henderson Corinna Coupette Shannon Salter Richard Susskind Markus Hartung Mary O’Carroll Daniel B. Rodriguez Mari Sako John Duggan Lucy Endel Bassli Riikka Koulu David Cambria Valérie Saintot …
#legaltech #legalinnovation #legalops #lawschool #legaleducation #law #makelawbetter #legalai #legalprofession
Introduction to Legal Technology & Innovation Course at Illinois Tech – Chicago Kent College of Law

In the past week (and weekend) I have taught classes via Zoom for my school (Illinois Tech – Chicago Kent – shown below) as well as University of Toronto Law and IE Law in Spain (early this morning) … Thanks to Chicago Kent Alums – Jason Dirkx (Littler Mendelson) and Amy Monaghan (Perkins Coie) for joining us in the virtual class!
ContraxSuite’s Document Explorer UI: Supporting COVID-19 Contract Analysis
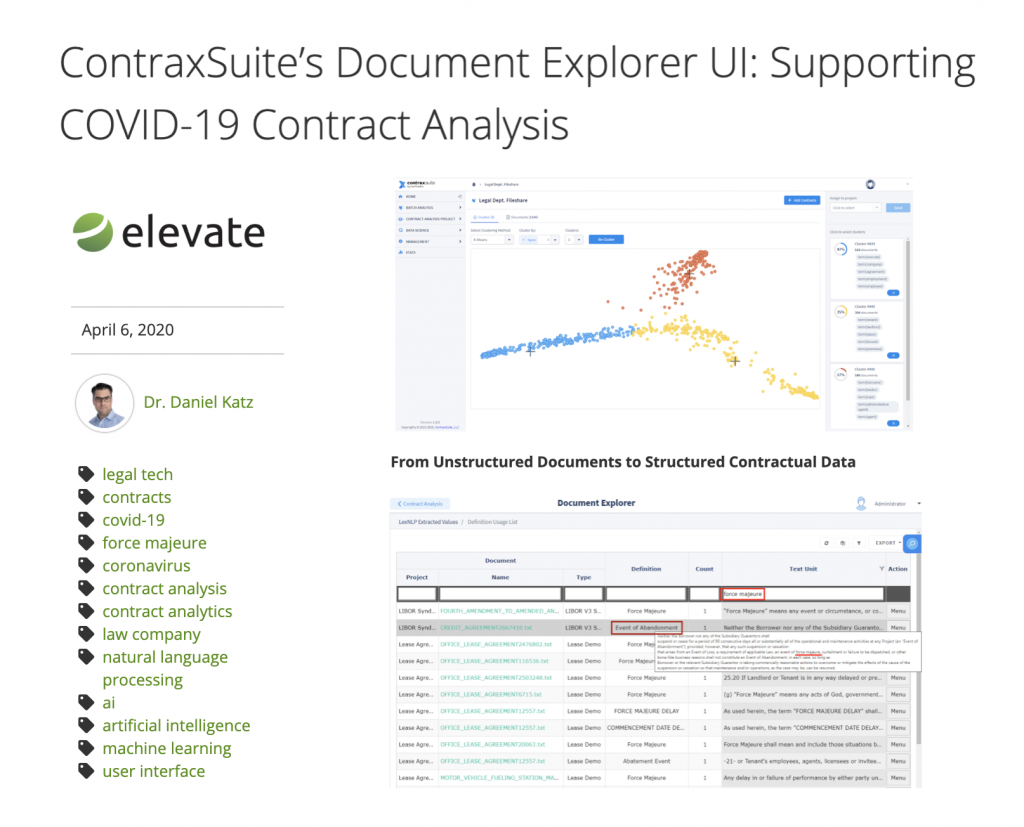
< See Blog Post on Elevate Blog Site >

Delivering the Opening Keynote at the CLOC London 2020 Conference

It was my pleasure to deliver the opening keynote address at London CLOC 2020 ! #LegalTech #LegalData #LegalInnovation #LegalOps