
Very happy to see this favorable ruling! Coverage in Bloomberg Law. I was one of 36 signatories to one of the Amicus Briefs in the case.

Very happy to see this favorable ruling! Coverage in Bloomberg Law. I was one of 36 signatories to one of the Amicus Briefs in the case.

Today is the day that SCOTUS considers Georgia v. Public.Resource.Org, Inc. (18-1150) — https://www.oyez.org/cases/2019/18-1150
 Another version of what we document in our paper … Daniel Katz, Michael J Bommarito II, Tyler Sollinger & Jim Chen, Law on the Market? Abnormal Stock Returns and Supreme Court Decision-Making
Another version of what we document in our paper … Daniel Katz, Michael J Bommarito II, Tyler Sollinger & Jim Chen, Law on the Market? Abnormal Stock Returns and Supreme Court Decision-Making
 The next leg of our SCOTUS Crowdsourcing Tour takes us to Minneapolis – for talk at the University of Minnesota Law School. Looking forward to it!
The next leg of our SCOTUS Crowdsourcing Tour takes us to Minneapolis – for talk at the University of Minnesota Law School. Looking forward to it!
Today Michael J Bommarito II and I were live in Ann Arbor at the University of Michigan Center for Political Studies to kickoff the tour for our #SCOTUS Crowd Prediction Paper — here is version 1.01 of the slide deck !

See coverage of our paper in MIT Technology Review and access paper on arXiv or SSRN
Here is an updated slidedeck from the presentation at the UChicago Judicial Behavior Workshop.
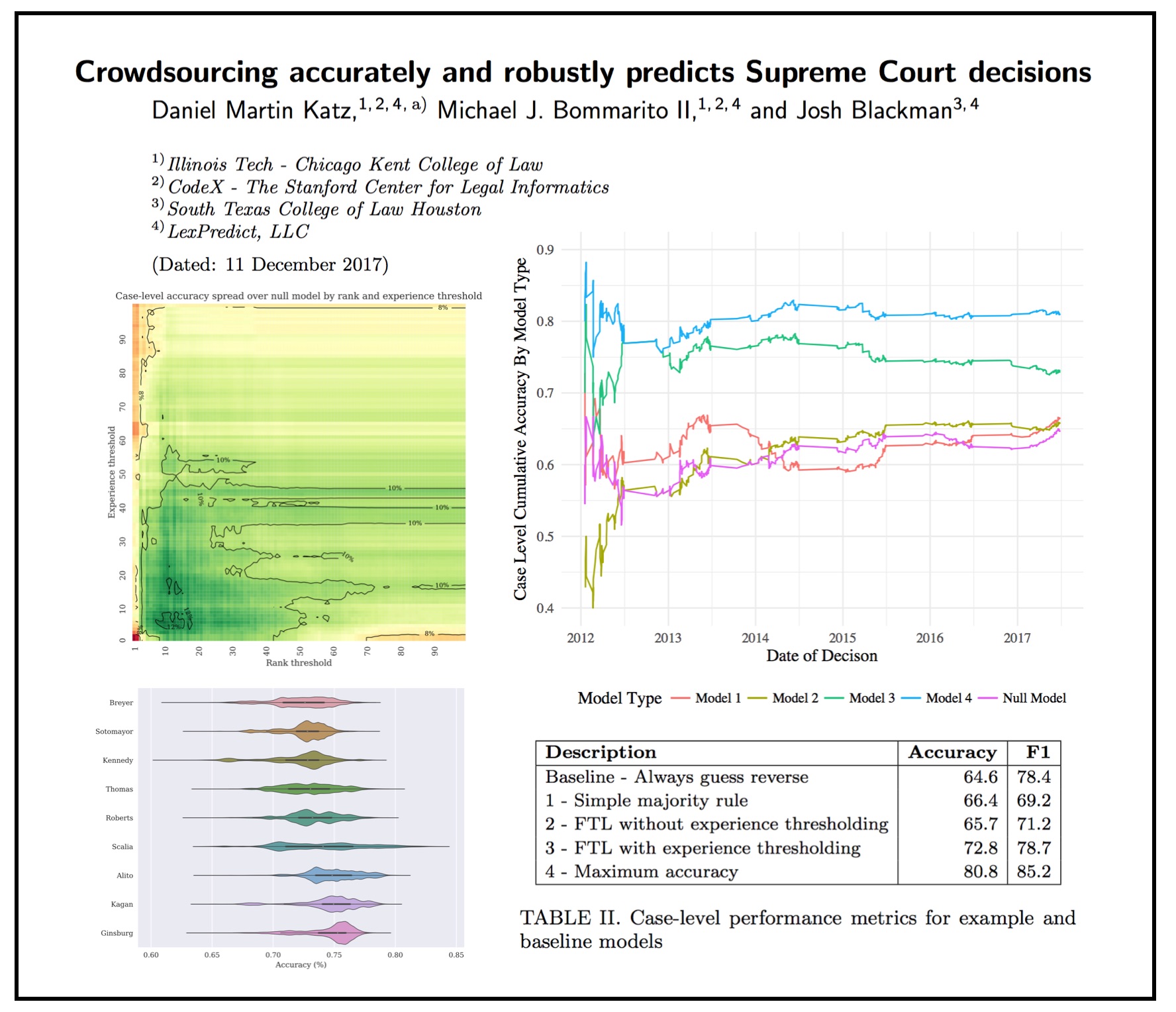
ABSTRACT: Scholars have increasingly investigated “crowdsourcing” as an alternative to expert-based judgment or purely data-driven approaches to predicting the future. Under certain conditions, scholars have found that crowd-sourcing can outperform these other approaches. However, despite interest in the topic and a series of successful use cases, relatively few studies have applied empirical model thinking to evaluate the accuracy and robustness of crowdsourcing in real-world contexts. In this paper, we offer three novel contributions. First, we explore a dataset of over 600,000 predictions from over 7,000 participants in a multi-year tournament to predict the decisions of the Supreme Court of the United States. Second, we develop a comprehensive crowd construction framework that allows for the formal description and application of crowdsourcing to real-world data. Third, we apply this framework to our data to construct more than 275,000 crowd models. We find that in out-of-sample historical simulations, crowdsourcing robustly outperforms the commonly-accepted null model, yielding the highest-known performance for this context at 80.8% case level accuracy. To our knowledge, this dataset and analysis represent one of the largest explorations of recurring human prediction to date, and our results provide additional empirical support for the use of crowdsourcing as a prediction method. (via SSRN)
 We have a paper on Abnormal Returns and Supreme Court decision making – this looks like a prime candidate for casino stocks, etc. (not a guarantee but a real possibility) — if only we had the technology to predict Supreme Court cases using methods such as crowds and algorithms 🙂
We have a paper on Abnormal Returns and Supreme Court decision making – this looks like a prime candidate for casino stocks, etc. (not a guarantee but a real possibility) — if only we had the technology to predict Supreme Court cases using methods such as crowds and algorithms 🙂
 Today – on behalf of my co-authors — I presented at the University of Chicago – Workshop on Judicial Behavior – Organized by Lee Epstein, Frank Easterbrook, Dennis Hutchinson, William Landes and Richard Posner. I think we have a very appropriate UChicago styled paper on Judicial Decision Making and Stock Market Movements.
Today – on behalf of my co-authors — I presented at the University of Chicago – Workshop on Judicial Behavior – Organized by Lee Epstein, Frank Easterbrook, Dennis Hutchinson, William Landes and Richard Posner. I think we have a very appropriate UChicago styled paper on Judicial Decision Making and Stock Market Movements.
Starting my fall road show across Chicago Area law schools, today I gave the faculty lunch seminar at Depaul University College of Law. I presented our paper on Judicial Decision Making and Stock Market Movements. Thanks to the good folks at Depaul for your thoughtful comments on the paper.
On behalf of my co-authors — next month — I will be presenting at the University of Chicago – Workshop on Judicial Behavior – Organized by Lee Epstein, Frank Easterbrook, Dennis Hutchinson, William Landes and Richard Posner. I think we have a very appropriate UChicago styled paper on Judicial Decision Making and Stock Market Movements.
This is one of our all time best efforts from a scientific perspective (and it is now 7 years old). We did a rehash of it in our recent paper in the March 31, 2017 edition of Science magazine.
What are some of the key takeaway points?
(1) The Supreme Court’s increasing reliance upon its own decisions over the 1800-1830 window.
(2) The important role of maritime/admiralty law in the early years of the Supreme Court’s citation network. At least with respect to the Supreme Court’s citation network, these maritime decisions are the root of the Supreme Court’s jurisprudence.
(3) The increasing centrality of decisions such as Marbury v. Madison, Martin v. Hunter’s Lessee to the overall network.
The Development of Structure in the SCOTUS Citation Network
The visualization offered above is the largest weakly connected component of the citation network of the United States Supreme Court (1800-1829). Each time slice visualizes the aggregate network as of the year in question.
In our paper entitled Distance Measures for Dynamic Citation Networks, we offer some thoughts on the early SCOTUS citation network. In reviewing the visual above note ….“[T]he Court’s early citation practices indicate a general absence of references to its own prior decisions. While the court did invoke well-established legal concepts, those concepts were often originally developed in alternative domains or jurisdictions. At some level, the lack of self-reference and corresponding reliance upon external sources is not terribly surprising. Namely, there often did not exist a set of established Supreme Court precedents for the class of disputes which reached the high court. Thus, it was necessary for the jurisprudence of the United States Supreme Court, seen through the prism of its case-to-case citation network, to transition through a loading phase. During this loading phase, the largest weakly connected component of the graph generally lacked any meaningful clustering. However, this sparsely connected graph would soon give way, and by the early 1820’s, the largest weakly connected component displayed detectable structure.”
We also explore this network in our 2010 paper — Michael Bommarito, Daniel Martin Katz, Jonathan Zelner & James Fowler, Distance Measures for Dynamic Citation Networks 389 Physica A 4201 (2010) < SSRN > < arXiv >

