

The First Workshop on Natural Legal Language Processing (NLLP) will take place as part of the larger North American Association of Computational Linguistics Conference in Minneapolis June 2019. NAACL is one of the premier technical events in the field of NLP / Computational Linguistics. Thus, I am very happy to give one of the Keynotes at this workshop. It is one more step toward making Legal Informatics and Legal AI / NLP a mainstream idea within the technically oriented portion of the academy.
I plan to highlight both my work with Mike Bommarito and others as well as provide an overview of the state of the field from both a technical and commercial perspective.



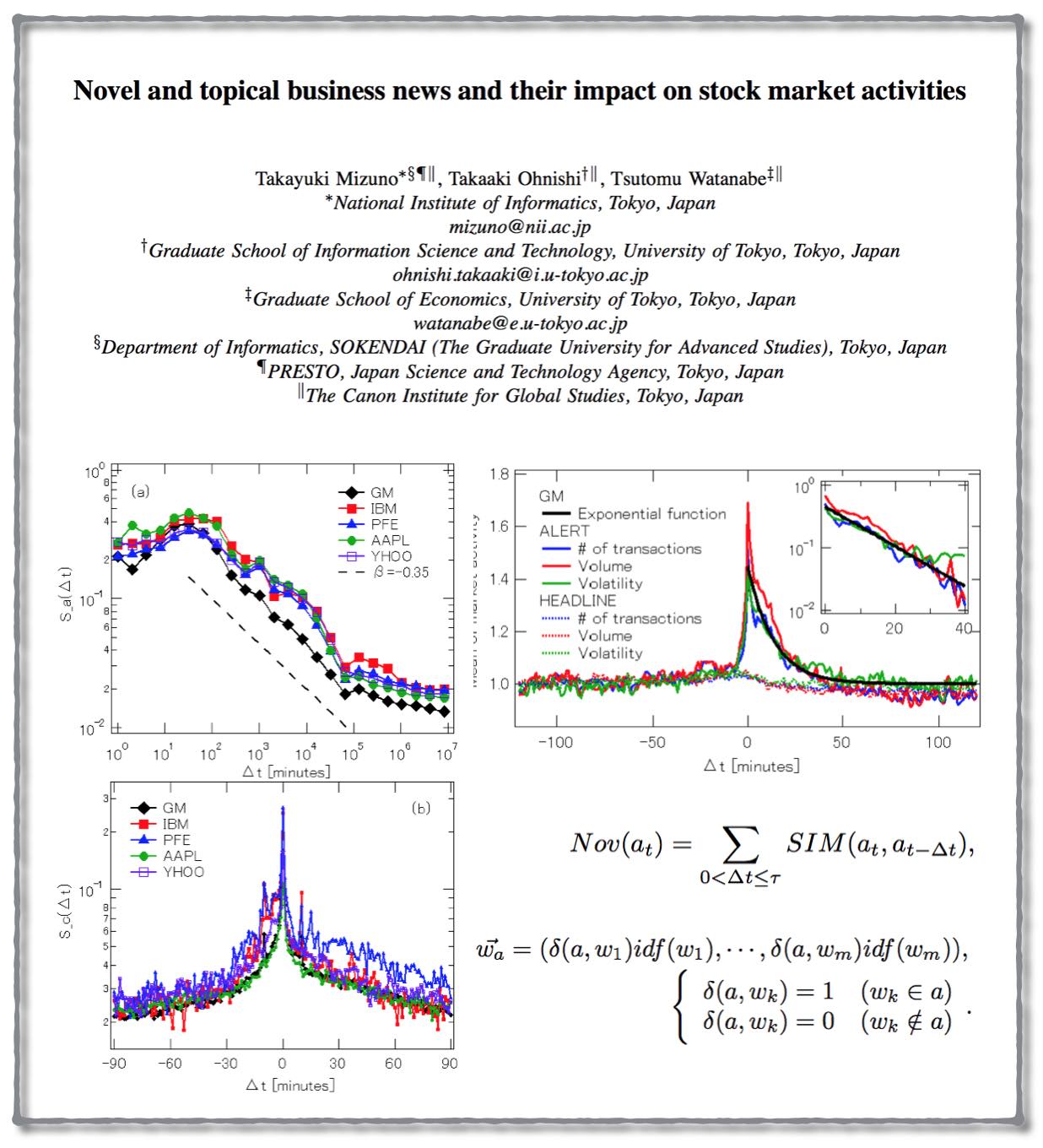

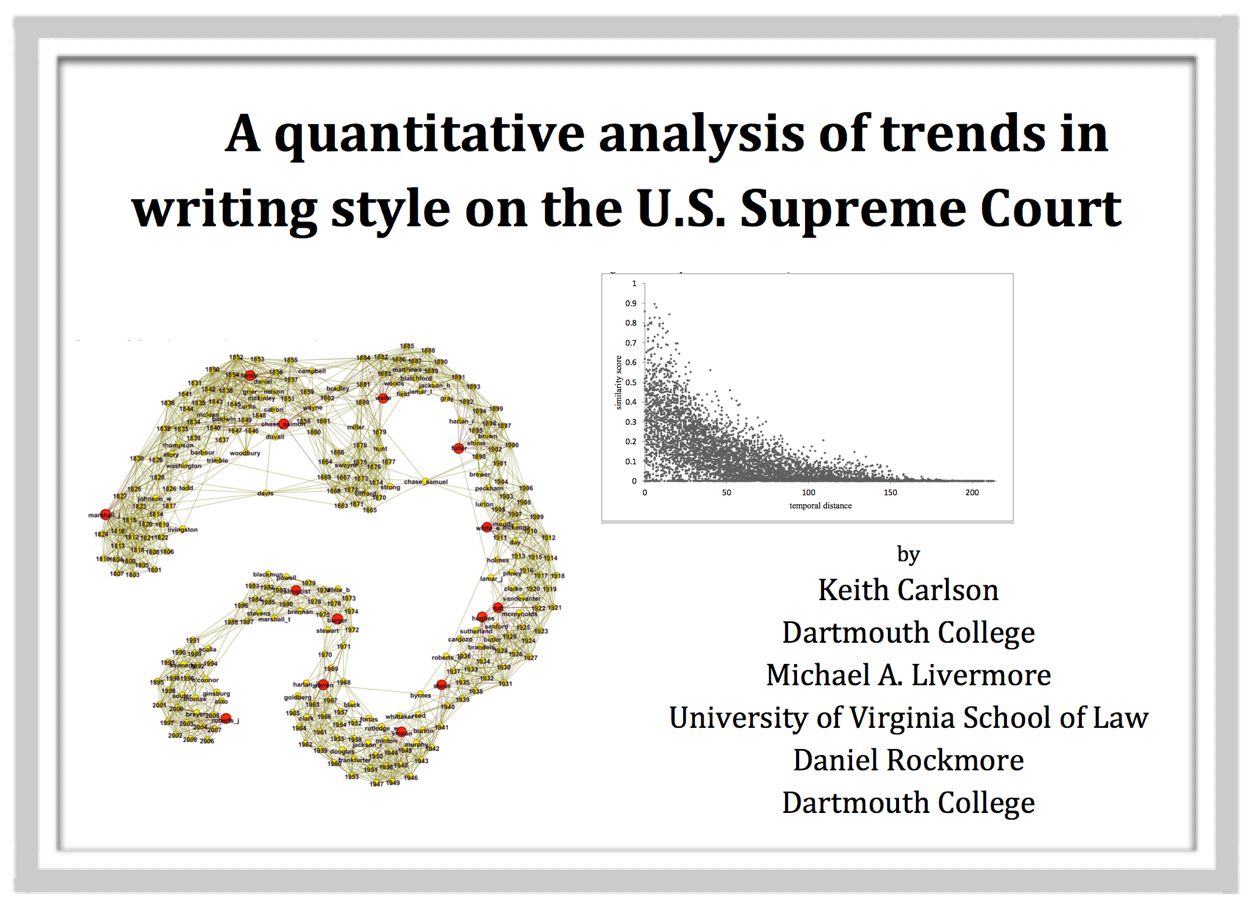

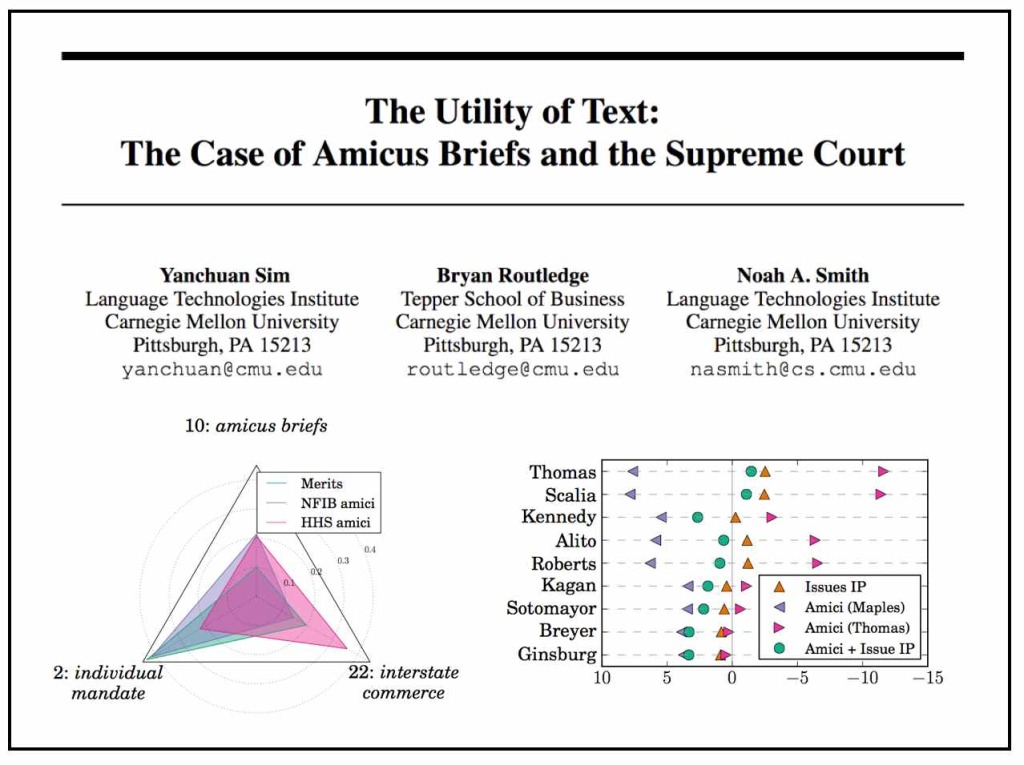 From the Abstract
From the Abstract


