
- United States Code
April 15th is Tax Day! Unless you’ve filed for an extension or you’re a corporation on your own fiscal year, you’ve hopefully finished your taxes by now!
While you were filing your return, you may have noticed references to the Internal Revenue Code (IRC). The IRC, also known as Title 26, is legal slang for the “Tax Code.” Along with the Treasury Regulations compiled into the Code of Federal Regulations (26 C.F.R.), the Internal Revenue Code contains many of the rules and regulations governing how we can and can’t file our taxes. Even if you prepared your taxes using software like TurboTax, the questions generated by these programs are determined by the rules and regulations within the Tax Code and Treasury Regulations.
Many argue that there are too many of these rules and regulations or that these rules and regulations are too complex. Furthermore, many also claim that the “Tax Code” is becoming larger or more complex over time. Unfortunately, most individuals do not support this claim with solid data. When they do, they often rely on either the number of pages in Title 26 or the CCH Standard Federal Tax Reporter. None of these measures take into consideration the real complexity of the Code, however.
In honor of Tax Day, we’re going to highlight a recent paper that we’ve written that tries to address some of these issues – A Mathematical Approach to the Study of the United States Code. The first point to make is that this paper is a study of the entire United States Code. Title 26, the Tax Code, is actually only one small part of the set of rules and regulations defined in the United States Code. The United States Code as a whole is the largest and arguably most important source of Federal statutory law. Compiled from the legislation and treaties published in the Statutes at Large in 6-year intervals, the entire document contains over 22 million words.
In this paper, we develop a mathematical approach to the study of the large bodies of statutory law and in particular, the United States Code. This approach can be summarized as guided by a representation of the Code as an object with three primary parts:
- A hierarchical network that corresponds to the structure of concept categories.
- A citation network that encodes the interdependence of concepts.
- The language contained within each section.
Given this representation, we then calculate a number of properties for the United States Code in 2008, 2009, and 2010 as provided by the Legal Information Institute at the Cornell University Law School. Our results can be summarized in three points:
- The structure of the United States Code is growing by over 3 sections per day.
- The interdependence of the United States Code is increasing by over 7 citations per day.
- The amount of language in the United States Code is increasing by over 2,000 words per day.
The figure above is an actual image of the structure and interdependence of the United States Code. The black lines correspond to structure and the red lines correspond to interdependence. Though visually stunning, the true implication of this figure is that the United States Code is a very interdependent set of rules and regulations, both within and across concept categories.
If you’re interested in more detail, make sure to read the paper –A Mathematical Approach to the Study of the United States Code. If you’re really interested, make sure to check back in the near future for our forthcoming paper entitled Measuring the Complexity of the United States Code.






")


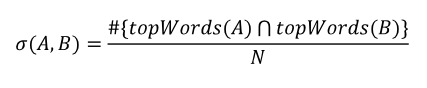 An edge exists between A and B in the set of edges if σ (A,B) exceeds some threshold. This threshold is the minimum similarity necessary for the graph to represent the presence of a semantic connection.”
An edge exists between A and B in the set of edges if σ (A,B) exceeds some threshold. This threshold is the minimum similarity necessary for the graph to represent the presence of a semantic connection.” 


