

In our paper Law as a Seamless Web, we offer a first-order method to generate case-to-case and opinionunit-to-opinionunit semantic networks. As constructed in the figure above, nodes represent cases decided between 1791-1865 while edges are drawn when two cases possess a certain threshold of semantic similarity. Except for the definition of edges, the process of constructing the semantic graph is identical to that of the citation graph we offered in the prior post. While computer science/computational linguistics offers a variety of possible semantic similarity measures, we choose to employ a commonly used measure. Here a description from the paper:
“Semantic similarity measures are the focus of significant work in computational linguistics. Given the scope of the dataset, we have chosen a first-order method for calculating similarity. After lemmatizing the text of the case with WordNet, we store the nouns with the top N frequencies for each case or opinion unit. We define the similarity between two cases or opinion units A and B as the percentage of words that are shared between the top words of A and top words of B.
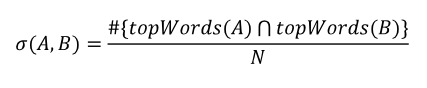 An edge exists between A and B in the set of edges if σ (A,B) exceeds some threshold. This threshold is the minimum similarity necessary for the graph to represent the presence of a semantic connection.”
An edge exists between A and B in the set of edges if σ (A,B) exceeds some threshold. This threshold is the minimum similarity necessary for the graph to represent the presence of a semantic connection.”
As this a technical paper, it is slanted toward demonstrating proof of methodological concept rather than covering significant substantive ground. With that said, we do offer a hint of our broader substantive goal of detecting the spread of legal concepts between various topical domains. Specifically, with respect to enriching positive political theory, we believe union, intersect and compliment of the semantic and citation networks are really important. More on this point is forthcoming in a subsequent post…