
See coverage of our paper in MIT Technology Review and access paper on arXiv or SSRN

See coverage of our paper in MIT Technology Review and access paper on arXiv or SSRN
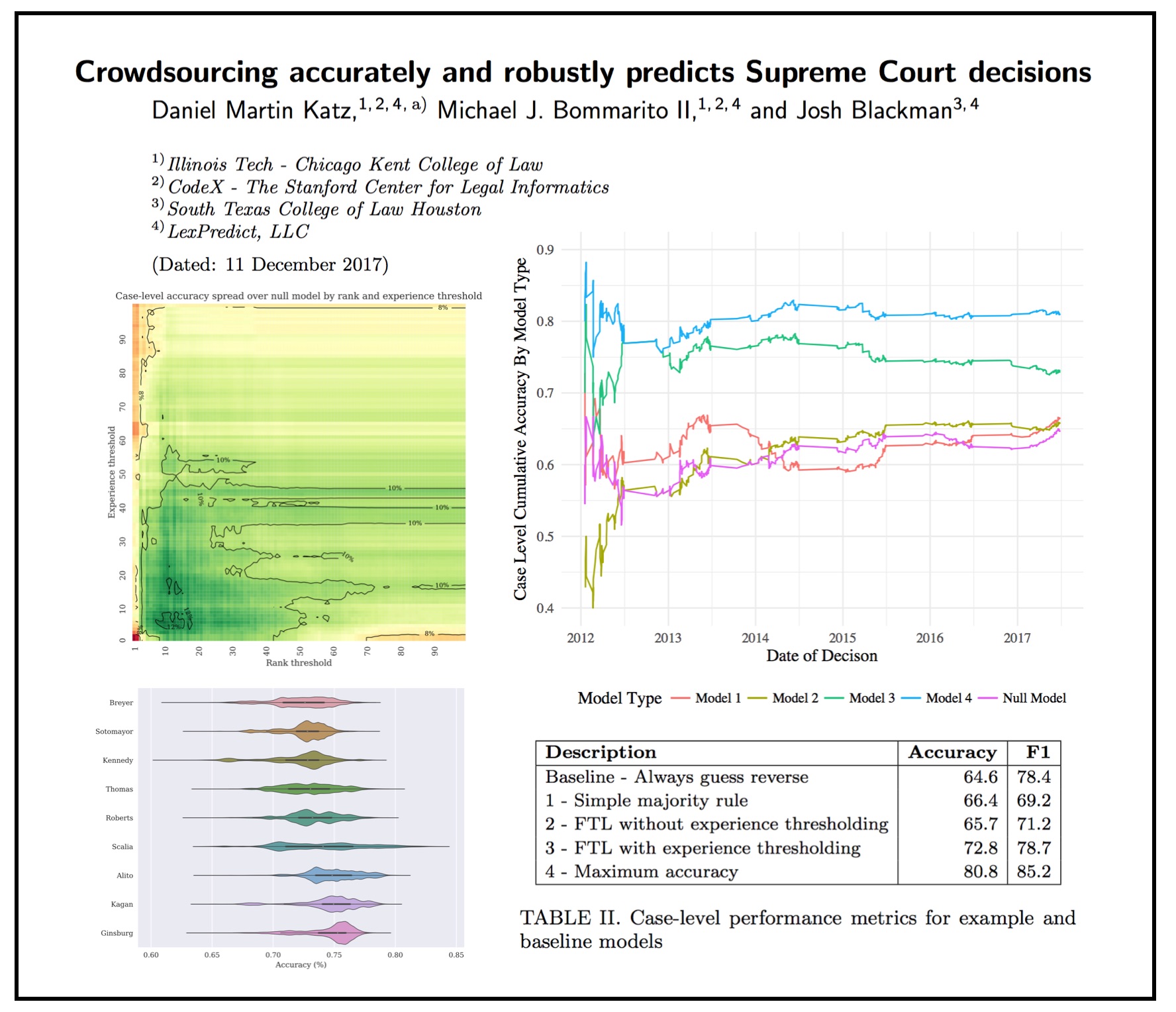
ABSTRACT: Scholars have increasingly investigated “crowdsourcing” as an alternative to expert-based judgment or purely data-driven approaches to predicting the future. Under certain conditions, scholars have found that crowd-sourcing can outperform these other approaches. However, despite interest in the topic and a series of successful use cases, relatively few studies have applied empirical model thinking to evaluate the accuracy and robustness of crowdsourcing in real-world contexts. In this paper, we offer three novel contributions. First, we explore a dataset of over 600,000 predictions from over 7,000 participants in a multi-year tournament to predict the decisions of the Supreme Court of the United States. Second, we develop a comprehensive crowd construction framework that allows for the formal description and application of crowdsourcing to real-world data. Third, we apply this framework to our data to construct more than 275,000 crowd models. We find that in out-of-sample historical simulations, crowdsourcing robustly outperforms the commonly-accepted null model, yielding the highest-known performance for this context at 80.8% case level accuracy. To our knowledge, this dataset and analysis represent one of the largest explorations of recurring human prediction to date, and our results provide additional empirical support for the use of crowdsourcing as a prediction method. (via SSRN)
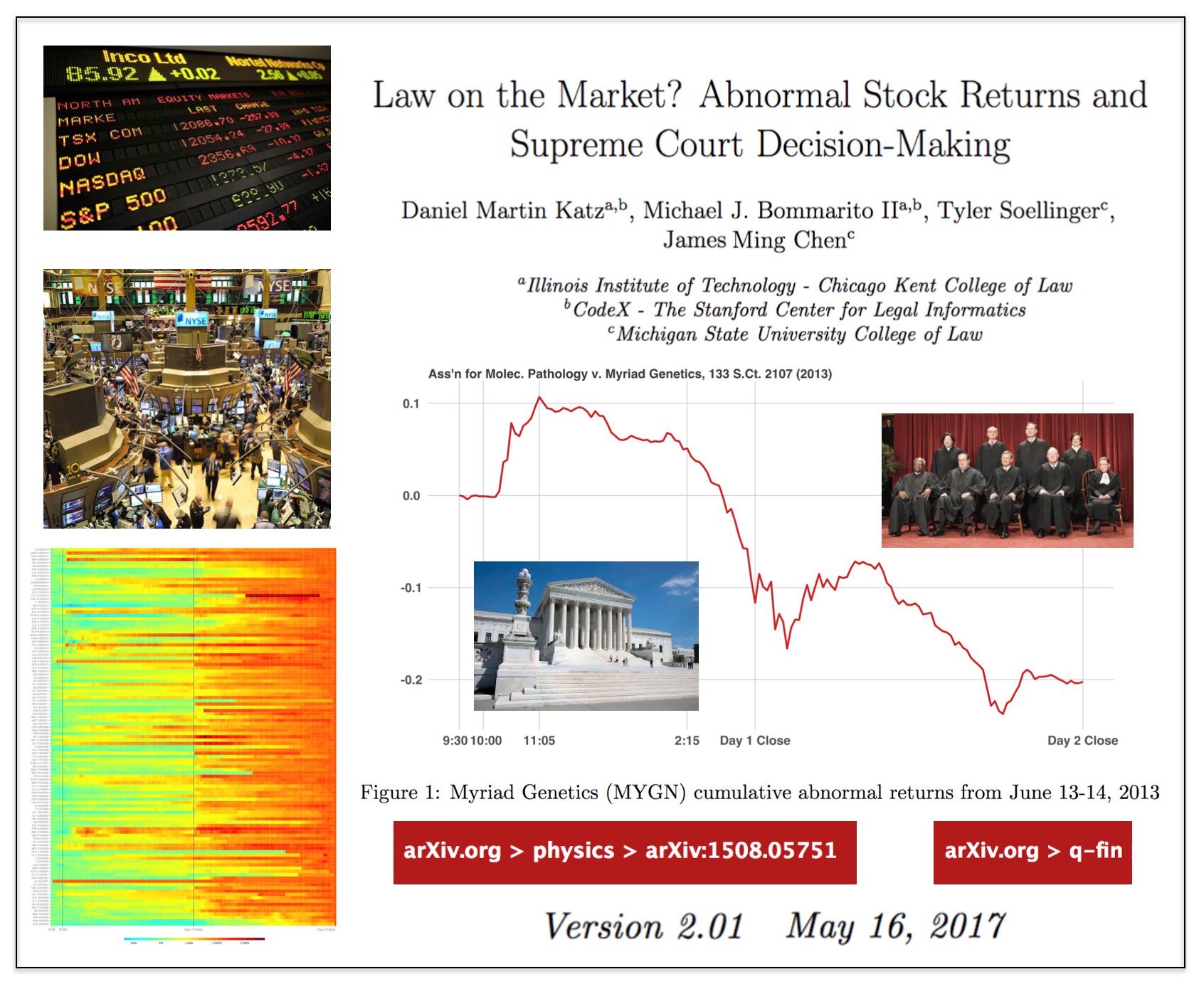
Here is Version 2.01 of the Law on the Market Paper —
From the Abstract: What happens when the Supreme Court of the United States decides a case impacting one or more publicly-traded firms? While many have observed anecdotal evidence linking decisions or oral arguments to abnormal stock returns, few have rigorously or systematically investigated the behavior of equities around Supreme Court actions. In this research, we present the first comprehensive, longitudinal study on the topic, spanning over 15 years and hundreds of cases and firms. Using both intra- and interday data around decisions and oral arguments, we evaluate the frequency and magnitude of statistically-significant abnormal return events after Supreme Court action. On a per-term basis, we find 5.3 cases and 7.8 stocks that exhibit abnormal returns after decision. In total, across the cases we examined, we find 79 out of the 211 cases (37%) exhibit an average abnormal return of 4.4% over a two-session window with an average |t|-statistic of 2.9. Finally, we observe that abnormal returns following Supreme Court decisions materialize over the span of hours and days, not minutes, yielding strong implications for market efficiency in this context. While we cannot causally separate substantive legal impact from mere revision of beliefs, we do find strong evidence that there is indeed a “law on the market” effect as measured by the frequency of abnormal return events, and that these abnormal returns are not immediately incorporated into prices.

Long time coming for us but here is Version 2.01 of our #SCOTUS Paper …
We have added three times the number years to the prediction model and now predict out-of-sample nearly two centuries of historical decisions (1816-2015). Then, we compare our results to three separate null models (including one which leverages in-sample information).
Here is the abstract: Building on developments in machine learning and prior work in the science of judicial prediction, we construct a model designed to predict the behavior of the Supreme Court of the United States in a generalized, out-of-sample context. Our model leverages the random forest method together with unique feature engineering to predict nearly two centuries of historical decisions (1816-2015). Using only data available prior to decision, our model outperforms null (baseline) models at both the justice and case level under both parametric and non-parametric tests. Over nearly two centuries, we achieve 70.2% accuracy at the case outcome level and 71.9% at the justice vote level. More recently, over the past century, we outperform an in-sample optimized null model by nearly 5%. Our performance is consistent with, and improves on the general level of prediction demonstrated by prior work; however, our model is distinctive because it can be applied out-of-sample to the entire past and future of the Court, not a single term. Our results represent an advance for the science of quantitative legal prediction and portend a range of other potential applications.
 From the article: “The prevalence of noise has been demonstrated in several studies. Academic researchers have repeatedly confirmed that professionals often contradict their own prior judgments when given the same data on different occasions. For instance, when software developers were asked on two separate days to estimate the completion time for a given task, the hours they projected differed by 71%, on average. When pathologists made two assessments of the severity of biopsy results, the correlation between their ratings was only .61 (out of a perfect 1.0), indicating that they made inconsistent diagnoses quite frequently. Judgments made by different people are even more likely to diverge. Research has confirmed that in many tasks, experts’ decisions are highly variable: valuing stocks, appraising real estate,sentencing criminals, evaluating job performance, auditing financial statements, and more. The unavoidable conclusion is that professionals often make decisions that deviate significantly from those of their peers, from their own prior decisions, and from rules that they themselves claim to follow.”
From the article: “The prevalence of noise has been demonstrated in several studies. Academic researchers have repeatedly confirmed that professionals often contradict their own prior judgments when given the same data on different occasions. For instance, when software developers were asked on two separate days to estimate the completion time for a given task, the hours they projected differed by 71%, on average. When pathologists made two assessments of the severity of biopsy results, the correlation between their ratings was only .61 (out of a perfect 1.0), indicating that they made inconsistent diagnoses quite frequently. Judgments made by different people are even more likely to diverge. Research has confirmed that in many tasks, experts’ decisions are highly variable: valuing stocks, appraising real estate,sentencing criminals, evaluating job performance, auditing financial statements, and more. The unavoidable conclusion is that professionals often make decisions that deviate significantly from those of their peers, from their own prior decisions, and from rules that they themselves claim to follow.”
Suffice to say we at LexPredict agree. Indeed, building from our work on Fantasy SCOTUS where our expert crowd outperforms any known single alternative (including the highest ranked Fantasy SCOTUS player), we have recently launched LexSemble (our configurable crowdsourcing platform) in order to help legal and other related organizations make better decisions (in transactions, litigation, regulatory matters, etc.).
We are working to pilot with a number of industry partners interested in applying underwriting techniques to more rigorously support their decision making. This is also an example of what we have been calling Fin(Legal)Tech (the financialization of law). If you want to learn more please sign up for our Fin(Legal)Tech conference coming on November 4th in Chicago) (tickets are free but space is limited).

In conjunction with Janders Dean International, and SeyfarthLean Consulting we are excited to offer two, half-day educational sessions on July 13th 2016.
Quantified Law Primer (Morning SESSION)
Instructors: Daniel Martin Katz (Chicago-Kent College of Law), Karl Haraldsson (Janders Dean), and Andrew Baker (Janders Dean)
Agile LPM Workshop (Afternoon SESSION)
Instructors: Kim Craig (SeyfarthLean Consulting), Andrew Baker (Janders Dean), and Justin North (Janders Dean)
These workshops are to be held in conjunction with the Chicago Kent- Janders Dean Legal Horizon Conference on July 14th in Chicago. The Legal Horizon event features more than 20+ speakers in a single day, single stage event.

It was a great pleasure to deliver the opening keynote at LegalTech Asia 2016 here at the JW Marriott in Hong Kong. The event draws leading legal professionals from across the Asia-Pacific region. It was a great to connect with everyone as part of a global conversation directed toward moving the profession forward!





