As noted earlier, we imposed a break over the Memorial Day Weekend and hope to return to a regular posting schedule this week. For the first post of the week, we want to reach out to readers exclusively socialized in legal or traditional social scientific circles. Namely, we recognize that a number of the approaches highlighted herein are not currently within the mainstream. Thus, many may not be familiar with the methods presented on this blog. So, just to reset ….
On this blog, we discuss scholarship or projects applying a computational, complex systems or informatics approach to questions of potential interest to legal and/or social science scholars. Our approach is unappolgetically interdisciplinary as we attempt to weave together a wide range of scientific methods and intellectual traditions. We have or will feature relevant scholarship from computer science, physics, network science, empirical legal studies, information visualization, new social history, computational politics and economics, mathematical sociology, behavioral biology, neuroscience, anthropology, linguistics ….
We have deeper motivations — but at a minimum — we believe the embrace of the techniques presented herein is justified as a search for intellectual returns on investment. While not applicable to all substantive questions, where appropriate we believe our approach to scholarship can convert higher-hanging fruit into low-hanging fruit.
It is hardly a revelation to note that disciplines tend to be insular. They develop cultures of intellectual reenforcement that can operate to stymie innovation by punishing deviations from status quo practices. Recognizing that switching costs are non-trivial, we want to once again highlight two articles previously discussed on this blog. For those interested in exploring a different terrain, we believe these articles offer both the rationale for and some of the mechanics of a computational approach to legal studies.
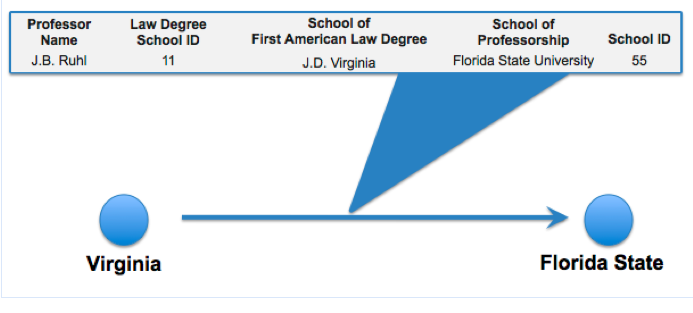
The first article, drawn from a recent issue of Science Magazine and authored by some of the leaders in field, highlights some of the possibilities of and potential perils associated with a computational revolution in the social sciences. It is a call to arms to many in social science circles. In a similar vein, Paul Ohm’s forthcoming article represents the law review analog. Among other things, Professsor Ohm offers a concrete playbook for those interested in applying the relevant mechanics to some discrete question of interest. The code displayed above is drawn from his article.





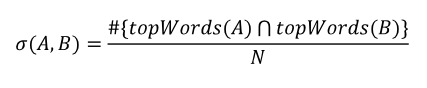 An edge exists between A and B in the set of edges if σ (A,B) exceeds some threshold. This threshold is the minimum similarity necessary for the graph to represent the presence of a semantic connection.”
An edge exists between A and B in the set of edges if σ (A,B) exceeds some threshold. This threshold is the minimum similarity necessary for the graph to represent the presence of a semantic connection.”