Research in the academic world suffers from the “hammer problem” – that is, the methods we use are often those that we have in our toolbox, not necessarily those that we should be using. This is especially true in computational social science, where we often attempt to directly import well-developed methods from the hard sciences.
To prove the point, I’d like to highlight one example we’ve come across in our research. In Leicht et al’s Large-scale structure of time evolving citation networks, the authors apply two methods to a simplified representation of the United States Supreme Court citation network. Both of these methods rely on complicated statistical algorithms and require iterative non-linear system solvers. However, the results are consistent, and they detect “events” around 1900, 1940, and 1970.

One first-order alternative to detecting significant “events” in the Court would be to count citations. One might suspect, for instance, that the formation or destruction of law might go hand-in-hand with an acceleration or deceleration in the rate of citation. Such a method is purely conjectural, but costs much less to implement than the methods discussed above.

This figure shows the number of outgoing citations per year in blue, as well as the ten-year moving average in purple. The plot shows jumps that coincide very well with the plot from Leicht, et. al. Thus, although only a first-order approximation to the underlying dynamics, this method would lead historians down a similar path with much less effort.
This example, though simple, is one that really hits home for me. After a week of struggling to align interpretations and methods, this plot convinced me more than any eigenvector or Lagrangian system. Perhaps more importantly, unlike the above methods, you can explain this plot to a lay audience in a fifteen minute talk.


 As we mentioned in previous posts, Seadragon is a really cool product. Please note load times may vary depending upon your specific machine configuration as well as the strength of your internet connection. For those not familiar with how to operate it please see below. In our view, the Full Screen is best the way to go ….
As we mentioned in previous posts, Seadragon is a really cool product. Please note load times may vary depending upon your specific machine configuration as well as the strength of your internet connection. For those not familiar with how to operate it please see below. In our view, the Full Screen is best the way to go ….





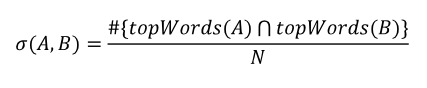 An edge exists between A and B in the set of edges if σ (A,B) exceeds some threshold. This threshold is the minimum similarity necessary for the graph to represent the presence of a semantic connection.”
An edge exists between A and B in the set of edges if σ (A,B) exceeds some threshold. This threshold is the minimum similarity necessary for the graph to represent the presence of a semantic connection.” 
