Lots has happened since Mike and I launched this site back in 2009 including a much larger community of folks interested in Computational Law. See the picture above from the Second Post on this blog.
We are rebooting Computational Legal Studies after a ~16 month break and back filling it with content that we have posted on other platforms such as LinkedIn, Facebook, etc.
It is good to be back pursuing the Computational Legal Agenda through this site.
We have a bunch of things in the works including our book “Legal Informatics” which is being released by Cambridge University Press in February 2021!
Today is the 2nd Workshop on Natural Legal Language Processing (NLLP) which is co-located at the broader 2020 KDD Virtual Conference. Corinna Coupette is presenting our paper ‘Complex Societies and the Growth of the Law’ as a Non-Archival Paper. NLLP is a strong scientific workshop (I did one the Keynote Addresses last year and found it to be a very good group of scholars and industry experts). More information is located here.
Open Call for Papers for a Special Collection in FRONTIERS in PHYSICS — “The Physics of the Law: Legal Systems Through the Prism of Complexity Science.” So far we have more than 30+ Scholars who have accepted our call for papers but we welcome others who would like to participate. Abstracts are due September 14th.
We welcome Original Research and Reviews where complexity science and quantitative approaches are deployed to evaluate the law / legal systems. Papers will be Peer Reviewed under the standards of Frontiers in Physics (or allied Frontiers Journals).
Papers can be empirical or theoretical but should be technical. If you have any questions feel free to message me.
An Online Virtual Conference will be held in early November.
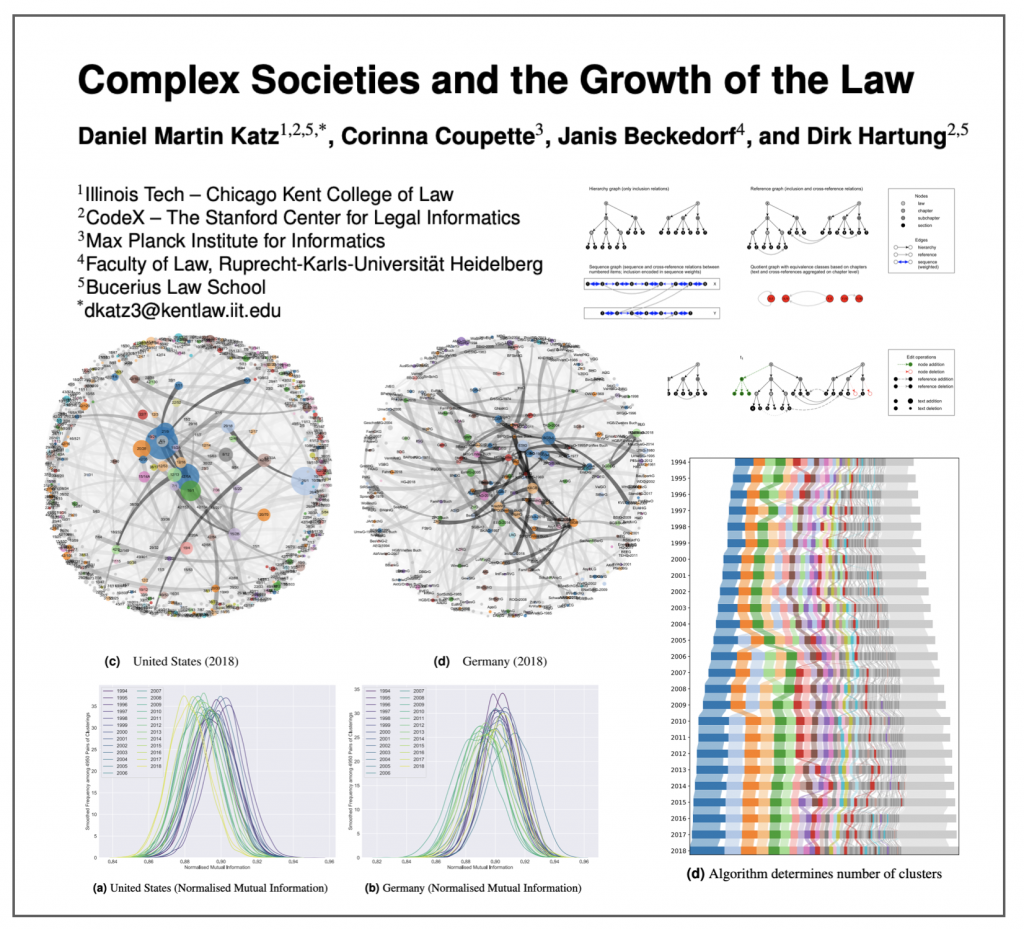
Updated Version of our Paper — ’Complex Societies and the Growth of the Law’ is now on SSRN / arXiv. It is primarily a methods and measurement paper combining Network Science, Natural Language Processing, etc. to evaluate the growth of the law as a function of time. #LegalComplexity #LegalScience #NLP #NetworkScience #ComplexSystems #DataScience
ABSTRACT – While a large number of informal factors influence how people interact, modern societies rely upon law as a primary mechanism to formally control human behaviour. How legal rules impact societal development depends on the interplay between two types of actors: the people who create the rules and the people to which the rules potentially apply. We hypothesise that an increasingly diverse and interconnected society might create increasingly diverse and interconnected rules, and assert that legal networks provide a useful lens through which to observe the interaction between law and society. To evaluate these propositions, we present a novel and generalizable model of statutory materials as multidimensional, time-evolving document networks. Applying this model to the federal legislation of the United States and Germany, we find impressive expansion in the size and complexity of laws over the past two and a half decades. We investigate the sources of this development using methods from network science and natural language processing. To allow for cross-country comparisons over time, we algorithmically reorganise the legislative materials of the United States and Germany into cluster families that reflect legal topics. This reorganisation reveals that the main driver behind the growth of the law in both jurisdictions is the expansion of the welfare state, backed by an expansion of the tax state.
Today I was Quoted in LegalIT Insider discussing GPT-3 and what it might mean for the future of Legal Tech / Legal AI … “There a few demos out there which look promising (but lots of things look good in a demo but are not robust in the end). I think the open question is always to what extent we can project any general advance in NLP to the domain specific challenges here in law-law land … On the positive side, I think every major and even minor advances present opportunities for us here in legal. It took a while but for example you see many of the products in our space taking advantage of Word Embedding [or transformer] methods (Word2Vec, BERT, ELMo, etc.)”
Yesterday I ran the anchor leg (i.e. gave the closing Keynote) at the Artificial Intelligence and Law Summit — Hosted by the Law Society of England and Wales here in London! #LegalAI#LegalTech#LegalInnovation
During my recent visit to Madrid a few weeks ago, I sat down for an interview with Alejandro Galisteo from the Expansión Newspaper. Access the Full Article here.
My colleague Warren Agin from LexPredict — Predicts Chapter 13 Bankruptcy Cases Using Machine Learning – Learn More HERE – #AI #LegalAI #MachineLearning #LegalTech #LegalData