
 < Access HERE >
< Access HERE >
Tag: machine learning
Network Analysis and Machine Learning in Law Conference – University of Oslo Faculty of Law – Call for Papers

Call For Papers: “The empirical turn in legal scholarship has intensified with the integration of a new quantitative and computational methods. In our second annual workshop on law and social science methods, we call for papers on two increasingly popular approaches: network science and machine learning. We are especially interested in papers that seek to deepen the understanding of these methods or apply them to doctrinal or interdisciplinary questions in areas such as criminology, international law, corporate Law and sustainable development.
The Keynote Speaker for the workshop is Dan Katz, Illinois Tech – Chicago Kent College of Law, who has been a pioneer in the use of both methods in understanding and predicting the behavior of the US Supreme Court and advancing the field of legal technology”
Abstracts of approximately 200 words should be submitted to Martin Nøkleberg and Hanna Ahlström by 22 August 2018.
Acceptance of papers will be notified by 1 September 2018.
Papers should be submitted by 24 September 2018.
Workshop 10-11 October 2018 at the University of Olso
OpenEDGAR: Open Source Software for SEC EDGAR Analysis (Michael Bommarito, Daniel Martin Katz & Eric Detterman)
 Our next paper — OpenEDGAR – Open Source Software for SEC Edgar Analysis is now available. This paper explores a range of #OpenSource tools we have developed to explore the EDGAR system operated by the US Securities and Exchange Commission (SEC). While a range of more sophisticated extraction and clause classification protocols can be developed leveraging LexNLP and other open and closed source tools, we provide some very simple code examples as an illustrative starting point.
Our next paper — OpenEDGAR – Open Source Software for SEC Edgar Analysis is now available. This paper explores a range of #OpenSource tools we have developed to explore the EDGAR system operated by the US Securities and Exchange Commission (SEC). While a range of more sophisticated extraction and clause classification protocols can be developed leveraging LexNLP and other open and closed source tools, we provide some very simple code examples as an illustrative starting point.
Click here for Paper: < SSRN > < arXiv >
Access Codebase Here: < Github >
Abstract: OpenEDGAR is an open source Python framework designed to rapidly construct research databases based on the Electronic Data Gathering, Analysis, and Retrieval (EDGAR) system operated by the US Securities and Exchange Commission (SEC). OpenEDGAR is built on the Django application framework, supports distributed compute across one or more servers, and includes functionality to (i) retrieve and parse index and filing data from EDGAR, (ii) build tables for key metadata like form type and filer, (iii) retrieve, parse, and update CIK to ticker and industry mappings, (iv) extract content and metadata from filing documents, and (v) search filing document contents. OpenEDGAR is designed for use in both academic research and industrial applications, and is distributed under MIT License at https://github.com/LexPredict/openedgar

Google launches Cloud AutoML to automatically build custom AI models (via Venture Beat)

The March of Machine Learning as a Service #MLaaS rolls on !
Workforce Implications of Machine Learning – Brynjolfsson + Mitchell in Science

Regarding the quote above — we agree. However, it should be noted that the ‘simple substitution story’ works at the aggregate level over a period of time with the simple assumption that the tasks which comprise current jobs can be decomposed and recombined into new jobs. Certainly, institutions (both firms and public sector) will take some period of time to be able to repackage certain existing jobs. Thus, lags are to be expected. < Click Here to Access the Article >

Applied Introduction to Machine Learning (via International Legal Technology Association Blog)

Fish & Richardson is one of the largest IP firms in the US so it is cool to see them exploring these ideas. If you look at this intro using Microsoft Azure – this is very on point with lots of we have been saying about the mix of semistructured data and #MLaaS (machine learning as a service) … and why we teach both an introduction to quant methods and a machine learning for lawyers course.


LexPredict Open Sources The 1910 Version of Black’s Law – The World’s Most Well Known Legal Dictionary is Now a Data Object

From the release: “At their core, many academic and commercial applications of natural language processing and machine learning can benefit from a controlled lexicon of expert-selected terms (i.e., a dictionary). This is especially true of highly technical language, such as legal text. However, after a search of the existing landscape, we were unable to find a high-quality open source or freely-available legal dictionary. Instead, the best existing versions, when available, exist under some form of restrictive licensing conditions.”
“Thus, in furtherance of both the legal profession as well as a range of legal technology providers and solutions, we are announcing another step in our broader open source plan that we outlined earlier this month. Namely, we are making available on Github the 1910 Version of Black’s Law (i.e., Black’s Law 2nd Edition) as a structured data object. This early version of arguably the premier legal dictionary is made available under the open source GPL license 3.0 which should allow both researchers and commercial providers to operate with limited restrictions.”
Click here to access the GitHub Repo.
Why We’re Open-Sourcing ContraxSuite – Product Overview, Some Use Cases and Plan for Release
–
Following up on our prior announcement – here is a slidedeck offering more Product Overview, Use Case and Plan for Release.
Why We Are Open Sourcing ContraxSuite and Some Thoughts About Legal Tech and the Modern Information Economy

Today we here at LexPredict announce that we will be open sourcing our document analytics platform ContraxSuite (which works on a wide class of documents beyond just contracts).
From the Announcement – “Starting on August 1st, this code base and our public development roadmap will be hosted on Github under a permissive open-source licensing model that will allow most organizations to quickly and freely implement and customize their own contract and document analytics. Like Redhat does for Linux, we will provide support, customization, and data services to “cover the last mile” for those organizations who need it.
We believe that a very important future for law lies in its central role in facilitating and regulating the modern information economy. But unless we start treating law itself like the production of information, we’ll never get there. Before we can solve big problems with smart contracts, we need to start by structuring existing legacy contracts. We hope our actions today will help lawyers, companies, and other LegalTech providers accelerate the pace of improvement and innovation through more open collaboration.” (click here for full announcement or access via Slideshare)
The Theory is Predictive, but is it Complete? An Application to Human Perception of Randomness
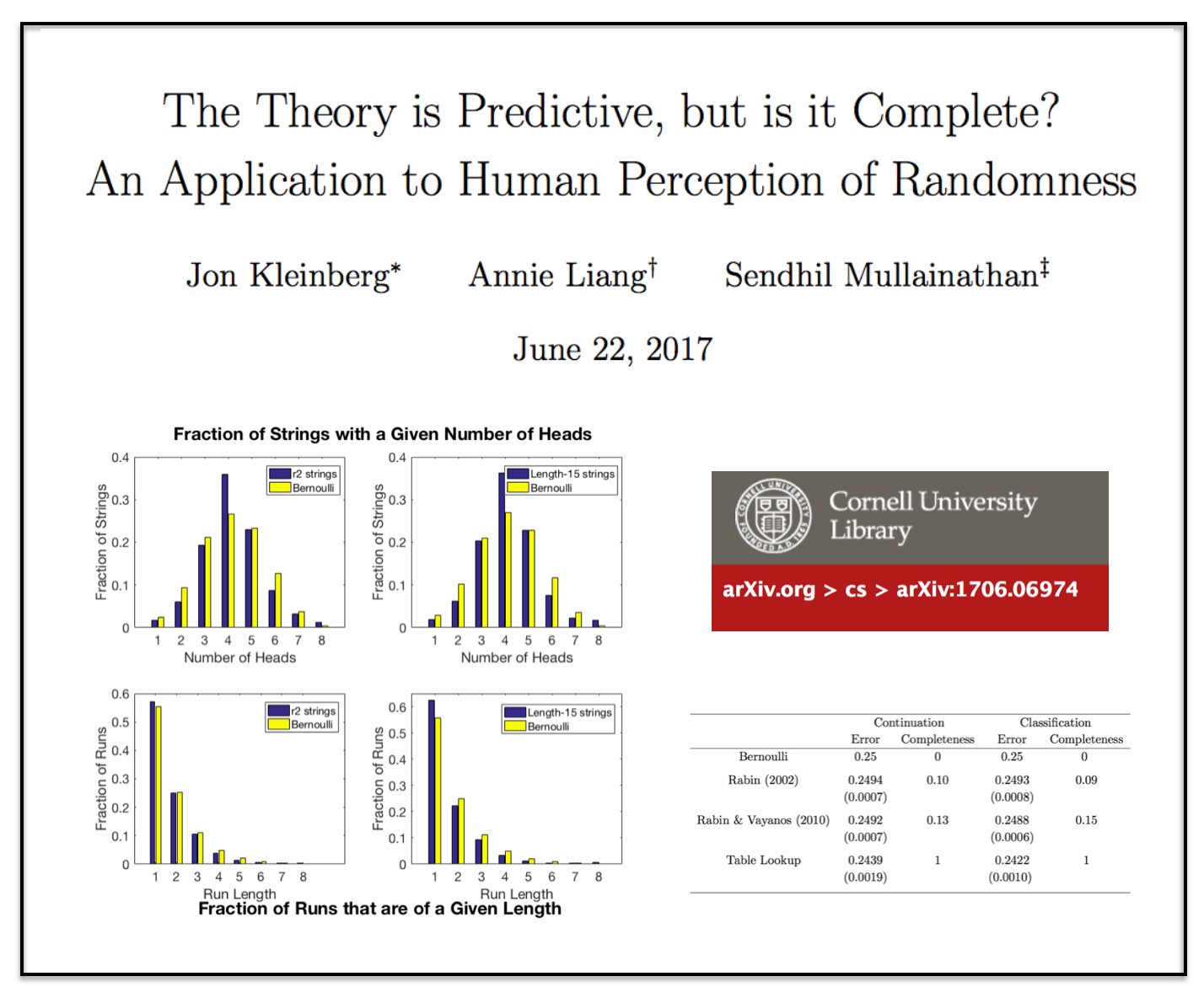 This is a very interesting paper!
This is a very interesting paper!
Fastcase to Launch Artificial Intelligence ‘Sandbox’ for Law Firms (via Bob Ambrogi – LawSites Blog)
This is an interesting development – click here to access story!