See the press release here.

 From Venture Beat – “AI startup Bonsai has raised $7.6 million to grow its platform that simplifies open-source machine learning library TensorFlow to help businesses construct their own artificial intelligence models and incorporate AI into their business.”
From Venture Beat – “AI startup Bonsai has raised $7.6 million to grow its platform that simplifies open-source machine learning library TensorFlow to help businesses construct their own artificial intelligence models and incorporate AI into their business.”
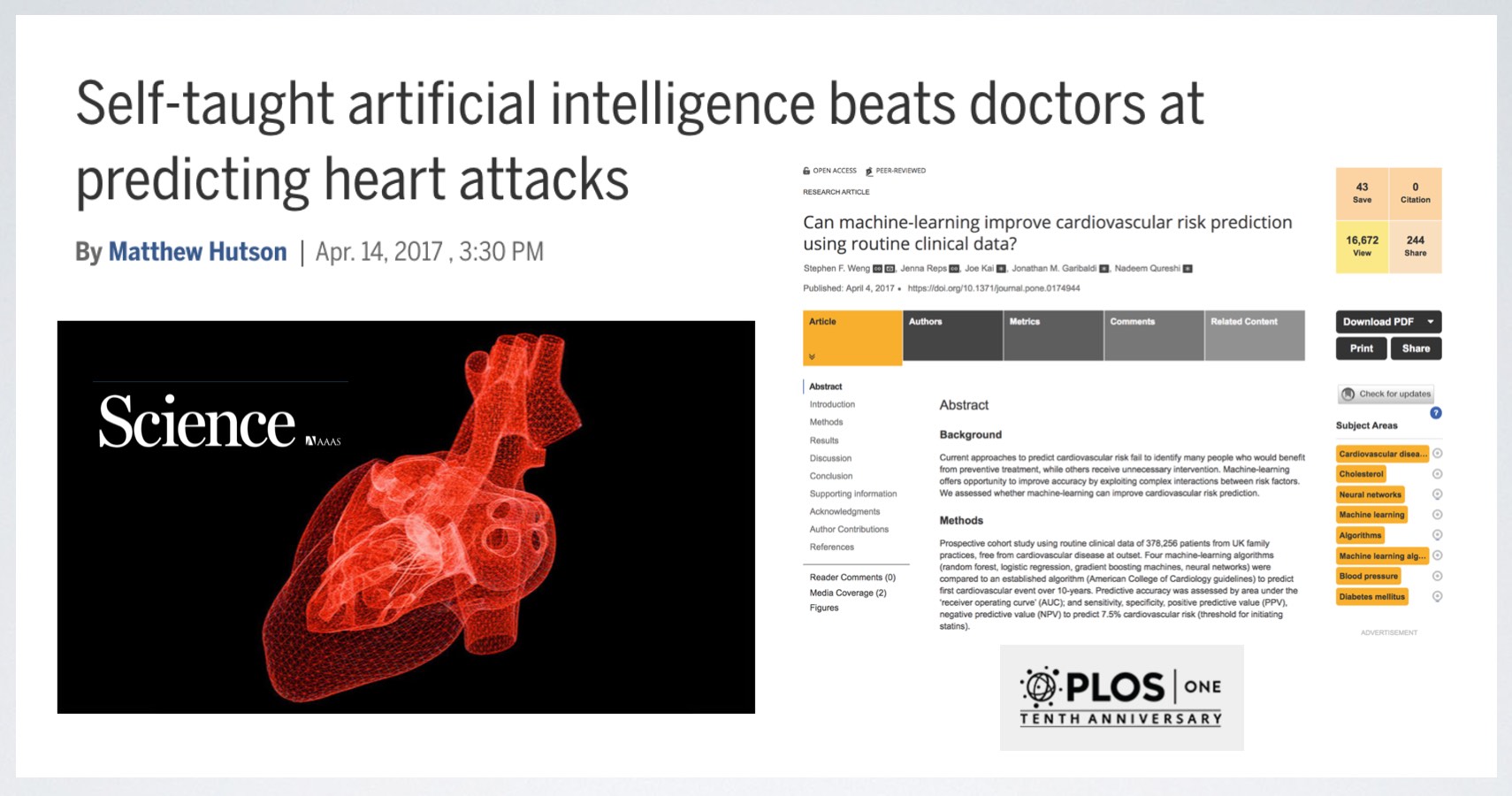
From Science News – “In the new study, Weng and his colleagues compared use of the ACC/AHA guidelines with four machine-learning algorithms: random forest, logistic regression, gradient boosting, and neural networks.”
We teach 3 out of 4 of these methods in our Legal Analytics Course (which is a machine learning for lawyers class).
The underlying paper was published in Plos One (one of my favorite journals) and the location where we recently published our US Supreme Court Prediction paper. In that paper, we use a time evolving random forest (with the novel twist of a tree burning protocol).
 Not sure this is actually a “set back for AI in Medicine.” Rather, long story short — it ain’t 2014 anymore … as we discuss in our talk – Machine Learning as a Service : #MLaaS, Open Source and the Future of Legal Analytics – what started with Watson has turned into significant competition among major technology industry players. Throw in a some open source and you have some really strong economic forces which are upending even business models which were sound just three years ago …
Not sure this is actually a “set back for AI in Medicine.” Rather, long story short — it ain’t 2014 anymore … as we discuss in our talk – Machine Learning as a Service : #MLaaS, Open Source and the Future of Legal Analytics – what started with Watson has turned into significant competition among major technology industry players. Throw in a some open source and you have some really strong economic forces which are upending even business models which were sound just three years ago …
From the story — “The partnership between IBM and one of the world’s top cancer research institutions is falling apart. The project is on hold, MD Anderson confirms, and has been since late last year. MD Anderson is actively requesting bids from other contractors who might replace IBM in future efforts. And a scathing report from auditors at the University of Texas says the project cost MD Anderson more than $62 million and yet did not meet its goals. The report, however, states: ‘Results stated herein should not be interpreted as an opinion on the scientific basis or functional capabilities of the system in its current state’….”

I am pleased to serve as a Program Chair and Speaker at the Plenary Presidential Summit @ New York State Bar Association Annual Meeting. Today’s topic will be Artificial Intelligence and its Impact on the Legal Profession. Joining me on the panel are the following panelists covering the following topics:
What is Artificial Intelligence? What is Machine Learning?
Dera J. Nevin, eDiscovery Counsel, Proskauer
What are Some Applications of Artificial Intelligence, Machine Learning, and Predictive Analytics in Law?
Andrew M.J. Arruda, CEO & Co-Founder, Ross Intelligence
Daniel Martin Katz, J.D., Ph.D., Associate Professor of Law, Illinois Tech – Chicago Kent Law
What are the Labor Market Impacts? More Jobs, Less Jobs, Different Forms of Legal Jobs and Legal Work?
Noah Waisberg, J.D., Co-founder & CEO, Kira Systems

Long time coming for us but here is Version 2.01 of our #SCOTUS Paper …
We have added three times the number years to the prediction model and now predict out-of-sample nearly two centuries of historical decisions (1816-2015). Then, we compare our results to three separate null models (including one which leverages in-sample information).
Here is the abstract: Building on developments in machine learning and prior work in the science of judicial prediction, we construct a model designed to predict the behavior of the Supreme Court of the United States in a generalized, out-of-sample context. Our model leverages the random forest method together with unique feature engineering to predict nearly two centuries of historical decisions (1816-2015). Using only data available prior to decision, our model outperforms null (baseline) models at both the justice and case level under both parametric and non-parametric tests. Over nearly two centuries, we achieve 70.2% accuracy at the case outcome level and 71.9% at the justice vote level. More recently, over the past century, we outperform an in-sample optimized null model by nearly 5%. Our performance is consistent with, and improves on the general level of prediction demonstrated by prior work; however, our model is distinctive because it can be applied out-of-sample to the entire past and future of the Court, not a single term. Our results represent an advance for the science of quantitative legal prediction and portend a range of other potential applications.
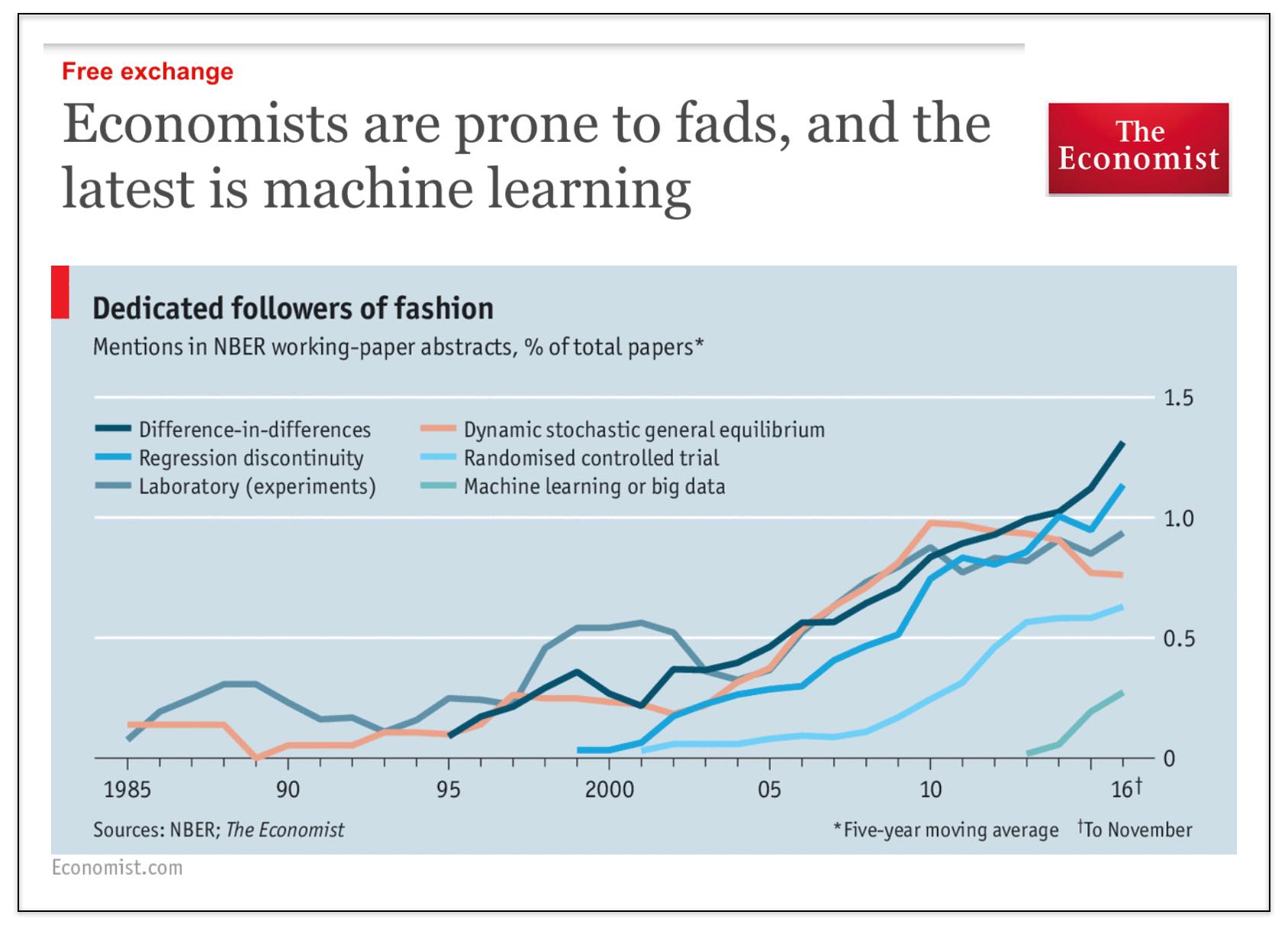
We started this blog (7 years ago) because we thought that there was insufficient attention to computational methods in law (NLP, ML, NetSci, etc.) Over the years this blog has evolved to become mostly a blog about the business of law (and business more generally) and the world is being impacted by automation, artificial intelligence and more broadly by information technology.
However, returning to our roots here — it is pretty interesting to see that the Economist has identified that #MachineLearning is finally coming to economics (pol sci + law as well).
Social science generally (and law as a late follower of developments in social science) it is still obsessed with causal inference (i.e. diff in diff, regression discontinuity, etc.). This is perfectly reasonable as it pertains to questions of evaluating certain aspects of public policy, etc.
However, there are many other problems in the universe that can be evaluated using tools from computer science, machine learning, etc. (and for which the tools of causal inference are not particularly useful).
In terms of the set of econ papers using ML, my bet is that a significant fraction of those papers are actually from finance (where people are more interested in actually predicting stuff).
In my 2013 article in Emory Law Journal called Quantitative Legal Prediction – I outline this distinction between causal inference and prediction and identify just a small set of the potential uses of predictive analytics in law. In some ways, my paper is already somewhat dated as the set of use cases has only grown. That said, the core points outlined therein remains fully intact …