

Tag: computational legal studies
ASU – Arkfeld Electronic Discovery Conference
 Yesterday I had the pleasure of providing the concluding remarks at the ASU – Arkfeld Electronic Discovery Conference in Tempe, Arizona. It was a really good mix of practicing lawyers, judges and technology providers in the room. Kudos to Michael Arkfeld, Josh Abbott and the rest of the planning committee for a great conference!
Yesterday I had the pleasure of providing the concluding remarks at the ASU – Arkfeld Electronic Discovery Conference in Tempe, Arizona. It was a really good mix of practicing lawyers, judges and technology providers in the room. Kudos to Michael Arkfeld, Josh Abbott and the rest of the planning committee for a great conference!
The Forum on Legal Evolution – NYC 02.26.13

Last week Bill Henderson, Bruce MacEwen and Daniel Martin Katz convened the first Forum on Legal Evolution – a small invitation only forum – for leaders from across the legal supply chain (General Counsels, Law Firms, Legal Technologists, Legal Media, Legal Educators, etc.). It was a good mix of members of the AM 200, GC’s of large companies, strategically important technology providers, etc. The primary focus of this first forum was three-fold: (1) change management and the diffusion of innovation, (2) process engineering and process improvement and (3) big data, legal analytics and machine learning in law practice (katz+bommartio slides are available here).
Aric Press from The American Lawyer offers a short write up of the event here.
Brian Dalton from Above the Law offers his perspective here.
Gartner Legal IT Scenario, 2020 – Smart Machines and LPO Radically Disrupt Legal Profession (via Gartner IT)
 The report offers a number of predictions including those quoted above and “by 2018, legal IT courses will be required for the graduates of at least 20 U.S. Tier 1 and Tier 2 law schools.”
The report offers a number of predictions including those quoted above and “by 2018, legal IT courses will be required for the graduates of at least 20 U.S. Tier 1 and Tier 2 law schools.”
While that would be sensible idea given the emerging opportunities in the legal market, I doubt that this will happen by 2018. Indeed, I would predict that somewhere between {0-2} law schools will make such the move of making such content mandatory by 2018. The ability to teach such a course is almost never a recognized hiring priority or hiring qualification that institutions are seeking (see here here here, etc.). Instead, law schools and faculty hiring committees typically focus on hiring for existing or perceived institutional needs. Even when institutions focus on the so called “best athlete” model of hiring … legal technology, etc. typically does not constitute a relevant dimension of the question. In other words, as I said in my MIT School of Law slide deck (and paper) the best athlete model depends upon what sport we are playing.
I am proud to be one of the few tenure track faculty members who actually teaches such courses inside a law school environment (legal technology / legal information engineering, quantitative methods, e-discovery, entrepruenerial lawyering, legal analytics, etc.) Among the existing institutions, there are strong and weaker version of the above courses. However, minus a few notable exceptions, most institutions do not have faculty members with the technical chops that are necessary to effectively teach such course(s).
The intersection of law+technology is one of the growth sectors within legal and as such it is a very exciting time to work in this area. Arbitrage opportunities are temporal in nature and given the highly competitive environment among law schools, it does not bother me if other law schools do not make this a priority. It allows those of us who are so inclined to build relationships with the leading folks in this emerging industry sub-sector before it lands on the radar of others.
Hilary Mason – Machine Learning for Hackers
Hilary Mason – Machine Learning for Hackers from BACON: things developers love on Vimeo.
HT: Noah Waisberg (Diligence Engine Blog)
Rank and Filed – SEC Filings for Humans
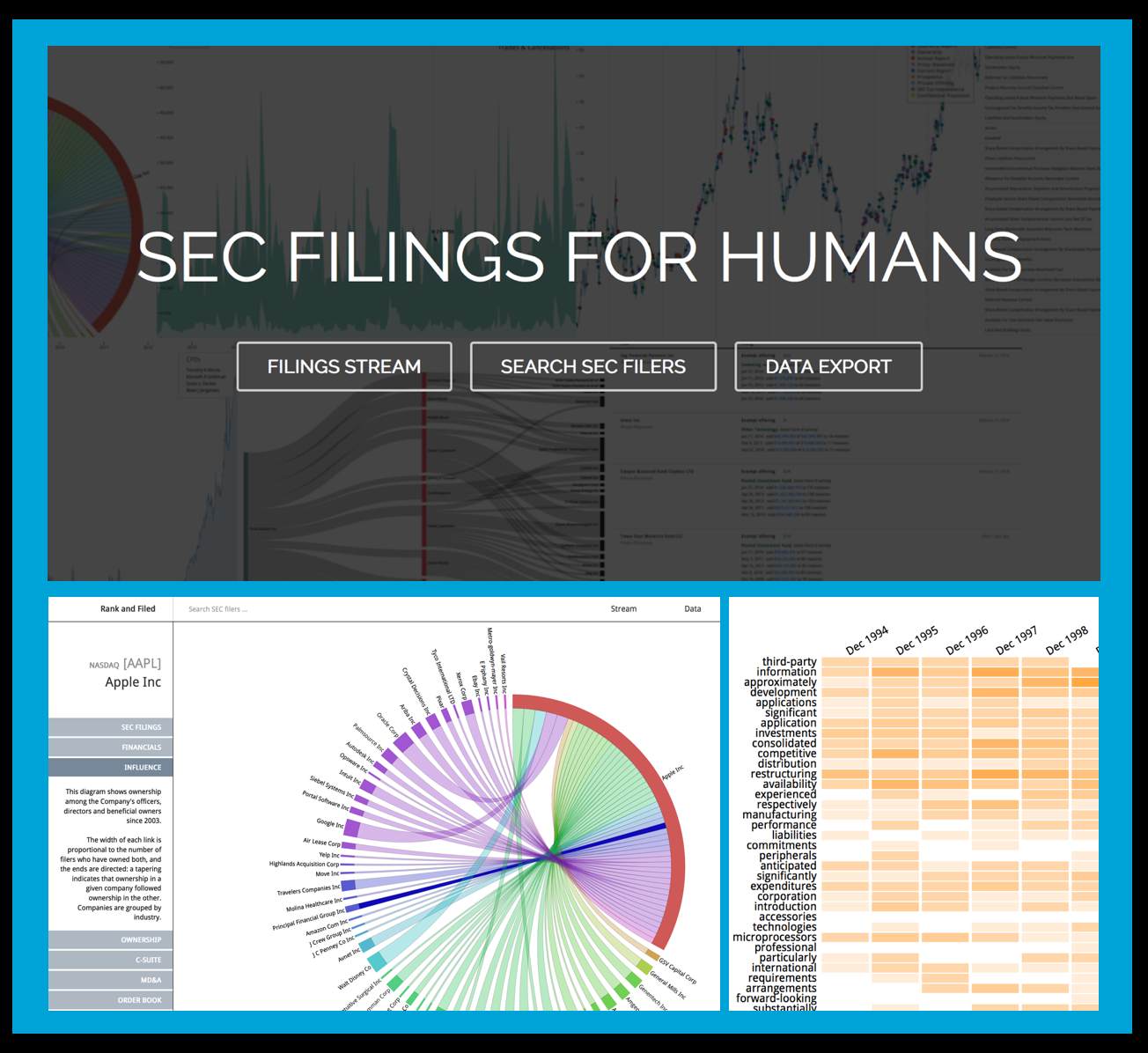 Really Impressive Work! – Read More Here. (HT to Ted Sichelman)
Really Impressive Work! – Read More Here. (HT to Ted Sichelman)
Legal Analytics – Introduction to the Course – Professors Daniel Martin Katz + Michael J Bommarito
Legal Analytics – Introduction to the Course – Professor Daniel Martin Katz + Professor Michael J Bommartio II from Daniel Martin Katz
Here is an introductory slide deck from “Legal Analytics” which is a course that Mike Bommarito and I are teaching this semester. Relevant legal applications include predictive coding in e-discovery (i.e. classification), early case assessment and overall case prediction, pricing and staff forecasting, prediction of judicial behavior, etc.
As I have written in my recent article in Emory Law Journal – we are moving into an era of data driven law practice. This course is a direct response to demands from relevant industry stakeholders. For a large number of prediction tasks … humans + machines > humans or machines working alone.
We believe this is the first ever Machine Learning Course offered to law students and it our goal to help develop the first wave of human capital trained to thrive as this this new data driven era takes hold. Richard Susskind likes to highlight this famous quote from Wayne Gretzky … “A good hockey player plays where the puck is. A great hockey player plays where the puck is going to be.”
Over 800 Folks in Attendance at Cooper Union for ReInventLaw NYC 2014 – Thanks So Much For Coming!
It is a wrap for #ReInventLaw NYC 2014. We finished up with just over 800 folks in attendance for this free, public facing event at the Cooper Union (~725 at the peak of the day according to the security guards who were keeping the count). As the conference co-organizer, I want to thank all of our speakers for speaking, all of our sponsors for sponsoring and all of our attendees for attending!
There are many interesting changes underway within the legal industry. Many of the participants (both speakers and attendees) are part of the innovator / early adopter segment. It was great to connect with everyone. I hope to continue the conversation. More importantly, I look forward to working together to help build the future …
Network Analysis and the Law — 3D-Hi-Def Visualization of the Time Evolving Citation Network of the United States Supreme Court

What are some of the key takeaway points?
(1) The Supreme Court’s increasing reliance upon its own decisions over the 1800-1830 window.
(2) The important role of maritime/admiralty law in the early years of the Supreme Court’s citation network. At least with respect to the Supreme Court’s citation network, these maritime decisions are the root of the Supreme Court’s jurisprudence.
(3) The increasing centrality of decisions such as Marbury v. Madison, Martin v. Hunter’s Lessee to the overall network.
The Development of Structure in the SCOTUS Citation Network
The visualization offered above is the largest weakly connected component of the citation network of the United States Supreme Court (1800-1829). Each time slice visualizes the aggregate network as of the year in question.
In our paper entitled Distance Measures for Dynamic Citation Networks, we offer some thoughts on the early SCOTUS citation network. In reviewing the visual above note ….“[T]he Court’s early citation practices indicate a general absence of references to its own prior decisions. While the court did invoke well-established legal concepts, those concepts were often originally developed in alternative domains or jurisdictions. At some level, the lack of self-reference and corresponding reliance upon external sources is not terribly surprising. Namely, there often did not exist a set of established Supreme Court precedents for the class of disputes which reached the high court. Thus, it was necessary for the jurisprudence of the United States Supreme Court, seen through the prism of its case-to-case citation network, to transition through a loading phase. During this loading phase, the largest weakly connected component of the graph generally lacked any meaningful clustering. However, this sparsely connected graph would soon give way, and by the early 1820’s, the largest weakly connected component displayed detectable structure.”
What are the elements of the network?

What are the labels?
To help orient the end-user, the visualization highlights several important decisions of the United States Supreme Court offered within the relevant time period:
Marbury v. Madison, 5 U.S. 137 (1803) we labeled as ”Marbury”
Murray v. The Charming Betsey, 6 U.S. 64 (1804) we labeled as “Charming Betsey” Martin v. Hunter’s Lessee, 14 U.S. 304 (1816) we labeled as “Martin’s Lessee”
The Anna Maria, 15 U.S. 327 (1817) we labeled as “Anna Maria”
McCulloch v. Maryland, 17 U.S. 316 (1819) we labeled as “McCulloch”
Why do cases not always enter the visualization when they are decided?
As we are interested in the core set of cases, we are only visualizing the largest weakly connected component of the United States Supreme Court citation network. Cases are not added until they are linked to the LWCC. For example, Marbury v. Madison is not added to the visualization until a few years after it is decided.
How do I best view the visualization?
Given this is a high-definition video, it may take few seconds to load. We believe that it is worth the wait. In our view, the video is best consumed (1) Full Screen (2) HD On (3) Scaling Off.
Where can I find related papers?
Here is a non-exhaustive list of related scholarship:
Daniel Martin Katz, Network Analysis Reveals the Structural Position of Foreign Law in the Early Jurisprudence of the United States Supreme Court (Working Paper – 2014)
Yonatan Lupu & James H. Fowler, Strategic Citations to Precedent on the U.S. Supreme Court, 42 Journal of Legal Studies 151 (2013)
Michael Bommarito, Daniel Martin Katz, Jon Zelner & James Fowler, Distance Measures for Dynamic Citation Networks, 389 Physica A 4201 (2010).
Michael Bommarito, Daniel Martin Katz & Jon Zelner, Law as a Seamless Web? Comparison of Various Network Representations of the United States Supreme Court Corpus (1791-2005) in Proceedings of the 12th Intl. Conference on Artificial Intelligence and Law (2009).
Frank Cross, Thomas Smith & Antonio Tomarchio, The Reagan Revolution in the Network of Law, 57 Emory L. J. 1227 (2008).
James Fowler & Sangick Jeon, The Authority of Supreme Court Precedent, 30 Soc. Networks 16 (2008).
Elizabeth Leicht, Gavin Clarkson, Kerby Shedden & Mark Newman, Large-Scale Structure of Time Evolving Citation Networks, 59 European Physics Journal B 75 (2007).
Thomas Smith, The Web of the Law, 44 San Diego L.R. 309 (2007).
James Fowler, Timothy R. Johnson, James F. Spriggs II, Sangick Jeon & Paul J. Wahlbeck, Network Analysis and the Law: Measuring the Legal Importance of Precedents at the U.S. Supreme Court, 15 Political Analysis, 324 (2007).
A Case Study in Legal Annotation (Wyner, Peters & Katz)
 This is an ongoing project with Adam Wyner (Dept. of Computer Science @ University of Aberdeen) and Wim Peters (Dept. of Computer Science + NLP Group @ University of Sheffield) … our very initial pilot project was presented at the 2013 Jurix Conference. Slides are located here and the case study paper for the pilot project is located here. Hoping for more to come on this project in 2014!
This is an ongoing project with Adam Wyner (Dept. of Computer Science @ University of Aberdeen) and Wim Peters (Dept. of Computer Science + NLP Group @ University of Sheffield) … our very initial pilot project was presented at the 2013 Jurix Conference. Slides are located here and the case study paper for the pilot project is located here. Hoping for more to come on this project in 2014!


Measuring the Complexity of the Law: The United States Code (By Daniel Martin Katz & Michael J. Bommarito)
 From our abstract: “Einstein’s razor, a corollary of Ockham’s razor, is often paraphrased as follows: make everything as simple as possible, but not simpler. This rule of thumb describes the challenge that designers of a legal system face—to craft simple laws that produce desired ends, but not to pursue simplicity so far as to undermine those ends. Complexity, simplicity’s inverse, taxes cognition and increases the likelihood of suboptimal decisions. In addition, unnecessary legal complexity can drive a misallocation of human capital toward comprehending and complying with legal rules and away from other productive ends.
From our abstract: “Einstein’s razor, a corollary of Ockham’s razor, is often paraphrased as follows: make everything as simple as possible, but not simpler. This rule of thumb describes the challenge that designers of a legal system face—to craft simple laws that produce desired ends, but not to pursue simplicity so far as to undermine those ends. Complexity, simplicity’s inverse, taxes cognition and increases the likelihood of suboptimal decisions. In addition, unnecessary legal complexity can drive a misallocation of human capital toward comprehending and complying with legal rules and away from other productive ends.
While many scholars have offered descriptive accounts or theoretical models of legal complexity, empirical research to date has been limited to simple measures of size, such as the number of pages in a bill. No extant research rigorously applies a meaningful model to real data. As a consequence, we have no reliable means to determine whether a new bill, regulation, order, or precedent substantially effects legal complexity.
In this paper, we address this need by developing a proposed empirical framework for measuring relative legal complexity. This framework is based on “knowledge acquisition,” an approach at the intersection of psychology and computer science, which can take into account the structure, language, and interdependence of law. We then demonstrate the descriptive value of this framework by applying it to the U.S. Code’s Titles, scoring and ranking them by their relative complexity. Our framework is flexible, intuitive, and transparent, and we offer this approach as a first step in developing a practical methodology for assessing legal complexity.”
This is a draft version so we invite your comments (katzd@law.msu.edu) and (michael.
UPDATE: Paper was named “Download of the Week” by Legal Theory Blog.