
We started this blog (7 years ago) because we thought that there was insufficient attention to computational methods in law (NLP, ML, NetSci, etc.) Over the years this blog has evolved to become mostly a blog about the business of law (and business more generally) and the world is being impacted by automation, artificial intelligence and more broadly by information technology.
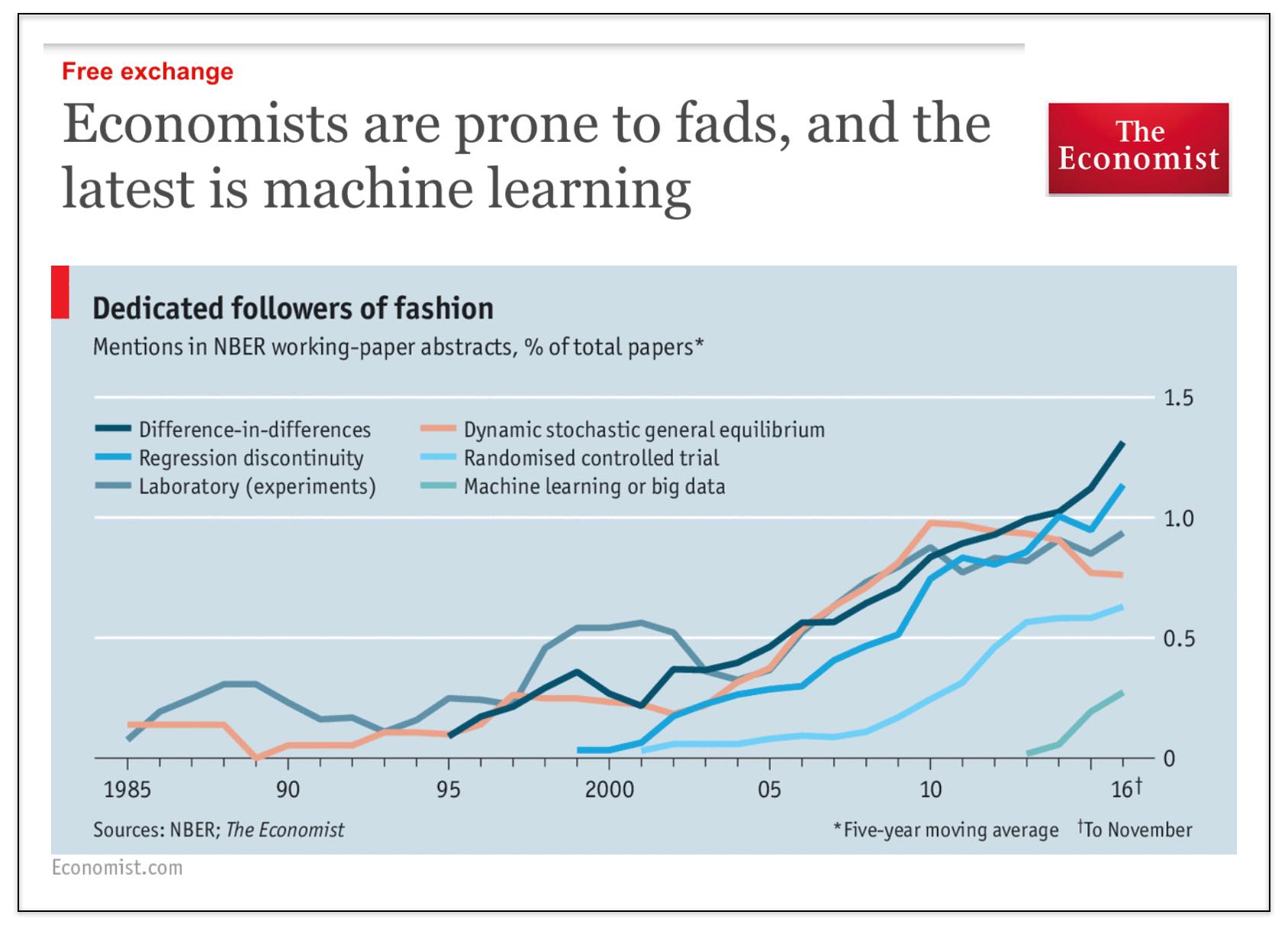
However, returning to our roots here — it is pretty interesting to see that the Economist has identified that #MachineLearning is finally coming to economics (pol sci + law as well).
Social science generally (and law as a late follower of developments in social science) it is still obsessed with causal inference (i.e. diff in diff, regression discontinuity, etc.). This is perfectly reasonable as it pertains to questions of evaluating certain aspects of public policy, etc.
However, there are many other problems in the universe that can be evaluated using tools from computer science, machine learning, etc. (and for which the tools of causal inference are not particularly useful).
In terms of the set of econ papers using ML, my bet is that a significant fraction of those papers are actually from finance (where people are more interested in actually predicting stuff).
In my 2013 article in Emory Law Journal called Quantitative Legal Prediction – I outline this distinction between causal inference and prediction and identify just a small set of the potential uses of predictive analytics in law. In some ways, my paper is already somewhat dated as the set of use cases has only grown. That said, the core points outlined therein remains fully intact …