

The March of Machine Learning as a Service #MLaaS rolls on !
Tag: machine learning for lawyers
Why We’re Open-Sourcing ContraxSuite – Product Overview, Some Use Cases and Plan for Release
–
Following up on our prior announcement – here is a slidedeck offering more Product Overview, Use Case and Plan for Release.
Why We Are Open Sourcing ContraxSuite and Some Thoughts About Legal Tech and the Modern Information Economy

Today we here at LexPredict announce that we will be open sourcing our document analytics platform ContraxSuite (which works on a wide class of documents beyond just contracts).
From the Announcement – “Starting on August 1st, this code base and our public development roadmap will be hosted on Github under a permissive open-source licensing model that will allow most organizations to quickly and freely implement and customize their own contract and document analytics. Like Redhat does for Linux, we will provide support, customization, and data services to “cover the last mile” for those organizations who need it.
We believe that a very important future for law lies in its central role in facilitating and regulating the modern information economy. But unless we start treating law itself like the production of information, we’ll never get there. Before we can solve big problems with smart contracts, we need to start by structuring existing legacy contracts. We hope our actions today will help lawyers, companies, and other LegalTech providers accelerate the pace of improvement and innovation through more open collaboration.” (click here for full announcement or access via Slideshare)
Economists are Prone to Fads, and the Latest is Machine Learning (via The Economist)
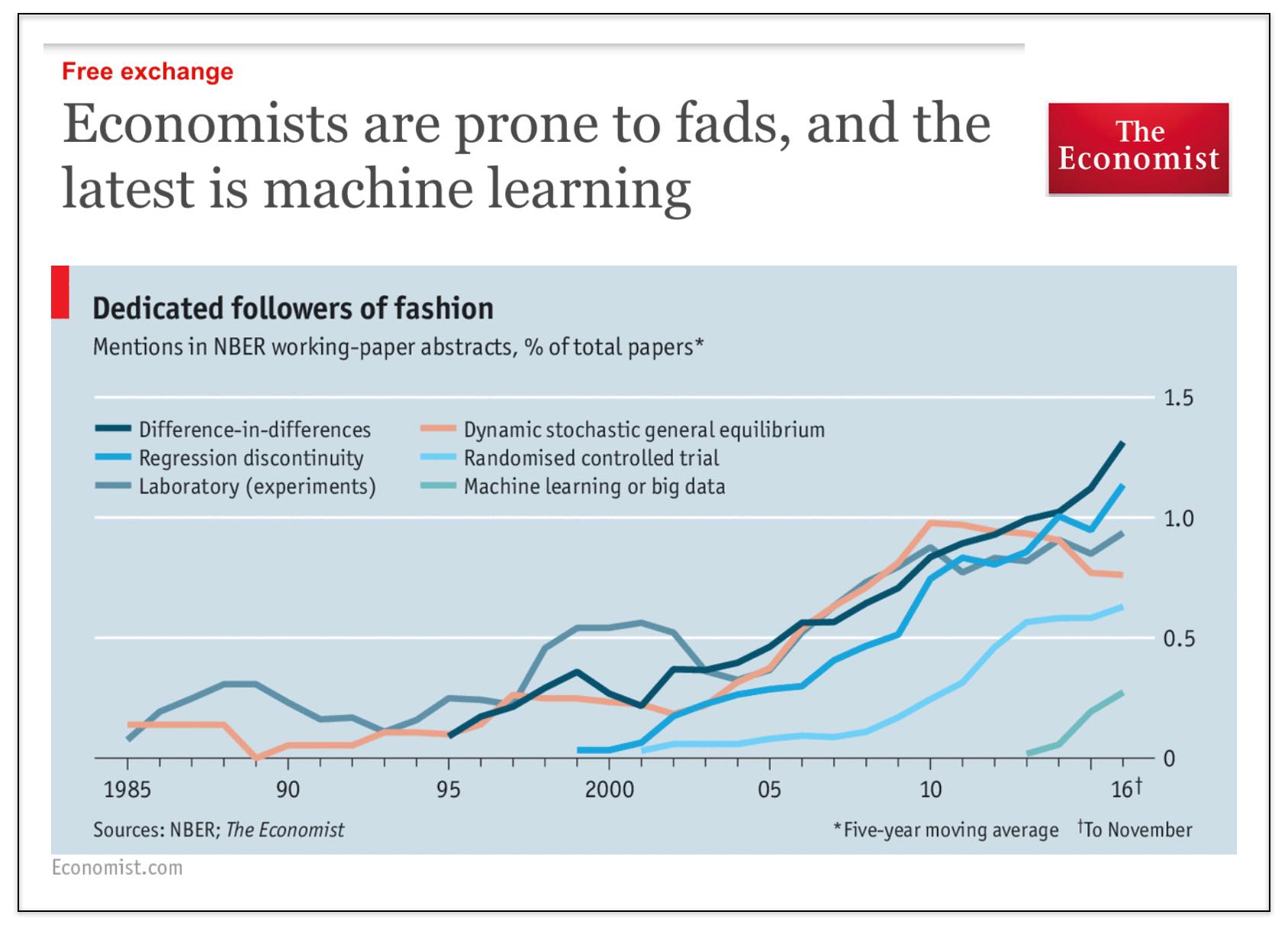
We started this blog (7 years ago) because we thought that there was insufficient attention to computational methods in law (NLP, ML, NetSci, etc.) Over the years this blog has evolved to become mostly a blog about the business of law (and business more generally) and the world is being impacted by automation, artificial intelligence and more broadly by information technology.
However, returning to our roots here — it is pretty interesting to see that the Economist has identified that #MachineLearning is finally coming to economics (pol sci + law as well).
Social science generally (and law as a late follower of developments in social science) it is still obsessed with causal inference (i.e. diff in diff, regression discontinuity, etc.). This is perfectly reasonable as it pertains to questions of evaluating certain aspects of public policy, etc.
However, there are many other problems in the universe that can be evaluated using tools from computer science, machine learning, etc. (and for which the tools of causal inference are not particularly useful).
In terms of the set of econ papers using ML, my bet is that a significant fraction of those papers are actually from finance (where people are more interested in actually predicting stuff).
In my 2013 article in Emory Law Journal called Quantitative Legal Prediction – I outline this distinction between causal inference and prediction and identify just a small set of the potential uses of predictive analytics in law. In some ways, my paper is already somewhat dated as the set of use cases has only grown. That said, the core points outlined therein remains fully intact …
The 16th International Conference on Artificial Intelligence and Law – King College London (June 2017)

The program committee for the 16th International Conference on Artificial Intelligence and Law has just named King College London as the host for the biannual ICAIL conference. Mark you calendars for 2017 in London!
The British Legal Technology Forum 2016

It was a great pleasure to delivery one of the Keynote Address at the 2016 British Legal Technology Forum. My talk was Fin(Legal)Tech – Law’s Future from Finance’s Past. Thanks to Richard Susskind and the full team at NetLaw Media for a wonderful event.


Experts, Crowds and Algorithms – AI Machine Learns to Drive Using Crowdteaching
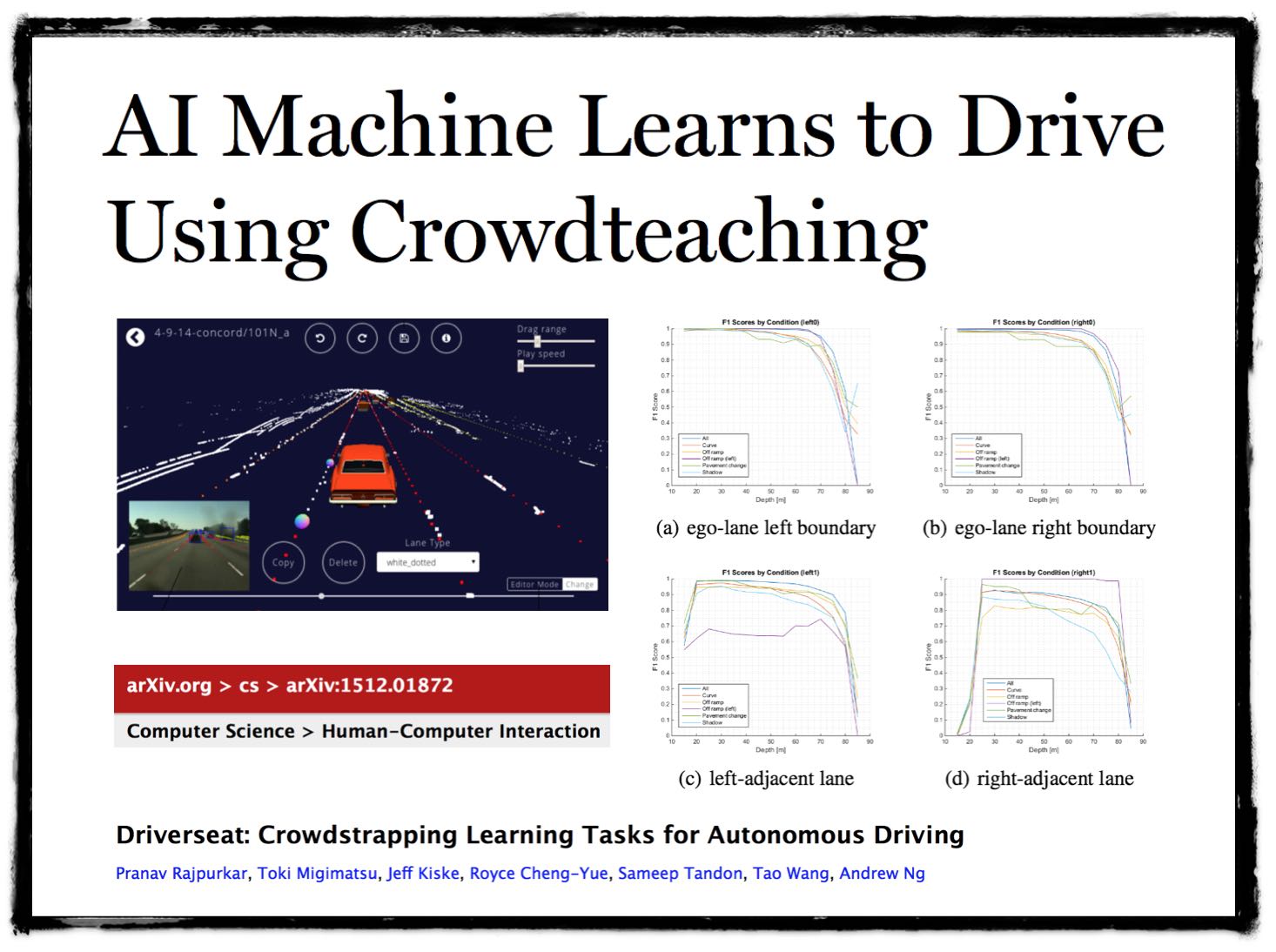
The example above is an algorithmic system that enhanced by the use of crowd based teaching. It is a useful example of the creativity employed by those in the machine learning research community. It is also instructive (at broader level) of the cutting edge approaches used in all of predictive analytics / machine learning.
In discussing legal prediction or the application of predictive analytics in law, we often try to start by highlighting The Three Forms of (Legal) Prediction: Experts, Crowds and Algorithms. These are really the only streams of intelligence that one can use to forecast anything. Historically, in the law – experts centered forecasting has almost exclusively dominated the industry. In virtually every field of human endeavor, there have been improvements (sometimes small to sometimes large) in forecasting which have been driven in the move from experts to ensembles (i.e. mixtures of these respective streams of intelligence – experts, crowds + algorithms).
Through our company LexPredict and in our research, we have been working toward building such ensemble models across a wide range of topics. In addition, we have engaged in a public display of these ideas through Fantasy SCOTUS, our SCOTUS prediction algorithm and through the identification of non-traditional experts (i.e. our superforecasters which — unlike most lawyers — are folks that have actually been benchmarked in their predictive performance). Finally, we have demonstrated the usefulness of SCOTUS prediction in a narrow subset of cases that actually move the securities market.
Machine Learning Explained (via Google’s Nat + Lo)
Pretty useful summary which is something we try to teach our students in our Legal Analytics Course (which could really be called Machine Learning for Lawyers). BTW – For those of you who emailed us, we promise to fill out the balance of the set of free, online Legal Analytics course materials in the coming months.
Econometrics (hereinafter Causal Inference) versus Machine Learning
 Perhaps some hyperbolic language in here but the basic idea is still intact … for law+economics / empirical legal studies – the causal inference versus machine learning point is expressed in detail in this paper called “Quantitative Legal Prediction.” Mike Bommarito and I have made this point in these slides, these slides, these slides, etc. Mike and I also make this point on Day 1 of our Legal Analytics Class (which really could be called “machine learning for lawyers”).
Perhaps some hyperbolic language in here but the basic idea is still intact … for law+economics / empirical legal studies – the causal inference versus machine learning point is expressed in detail in this paper called “Quantitative Legal Prediction.” Mike Bommarito and I have made this point in these slides, these slides, these slides, etc. Mike and I also make this point on Day 1 of our Legal Analytics Class (which really could be called “machine learning for lawyers”).
Amazon Introduces a Cloud Service for Machine Learning (via Venture Beat)
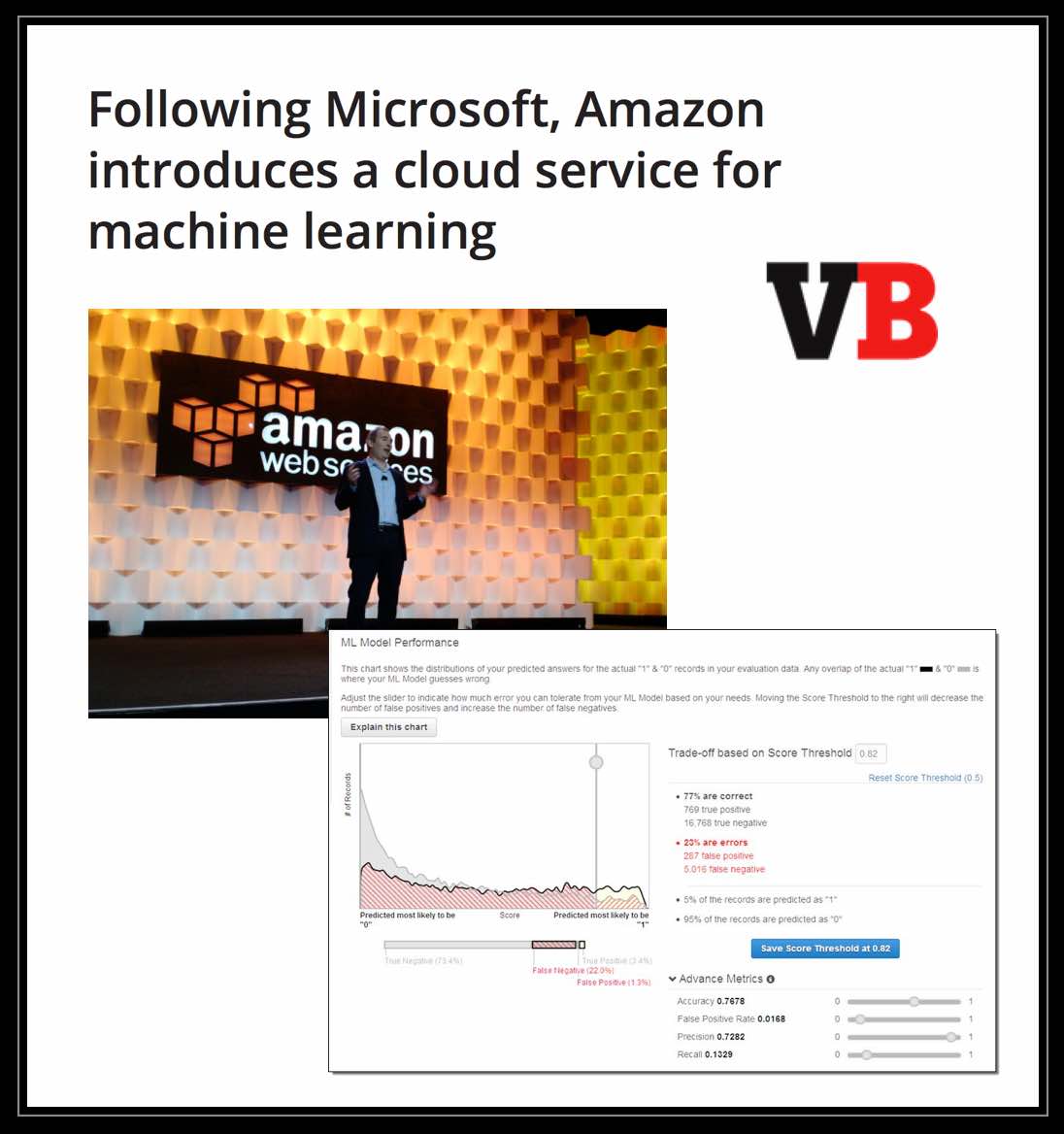
Suffice to say – this platform and competing platforms are going to collectively lower barriers to entry … and that is likely to have some implications (some good and some bad)