I am excited to be quoted in the FT’s Big Read today!

I am excited to be quoted in the FT’s Big Read today!
 My colleague Warren Agin from LexPredict — Predicts Chapter 13 Bankruptcy Cases Using Machine Learning – Learn More HERE – #AI #LegalAI #MachineLearning #LegalTech #LegalData
My colleague Warren Agin from LexPredict — Predicts Chapter 13 Bankruptcy Cases Using Machine Learning – Learn More HERE – #AI #LegalAI #MachineLearning #LegalTech #LegalData
 This is a very interesting paper!
This is a very interesting paper!
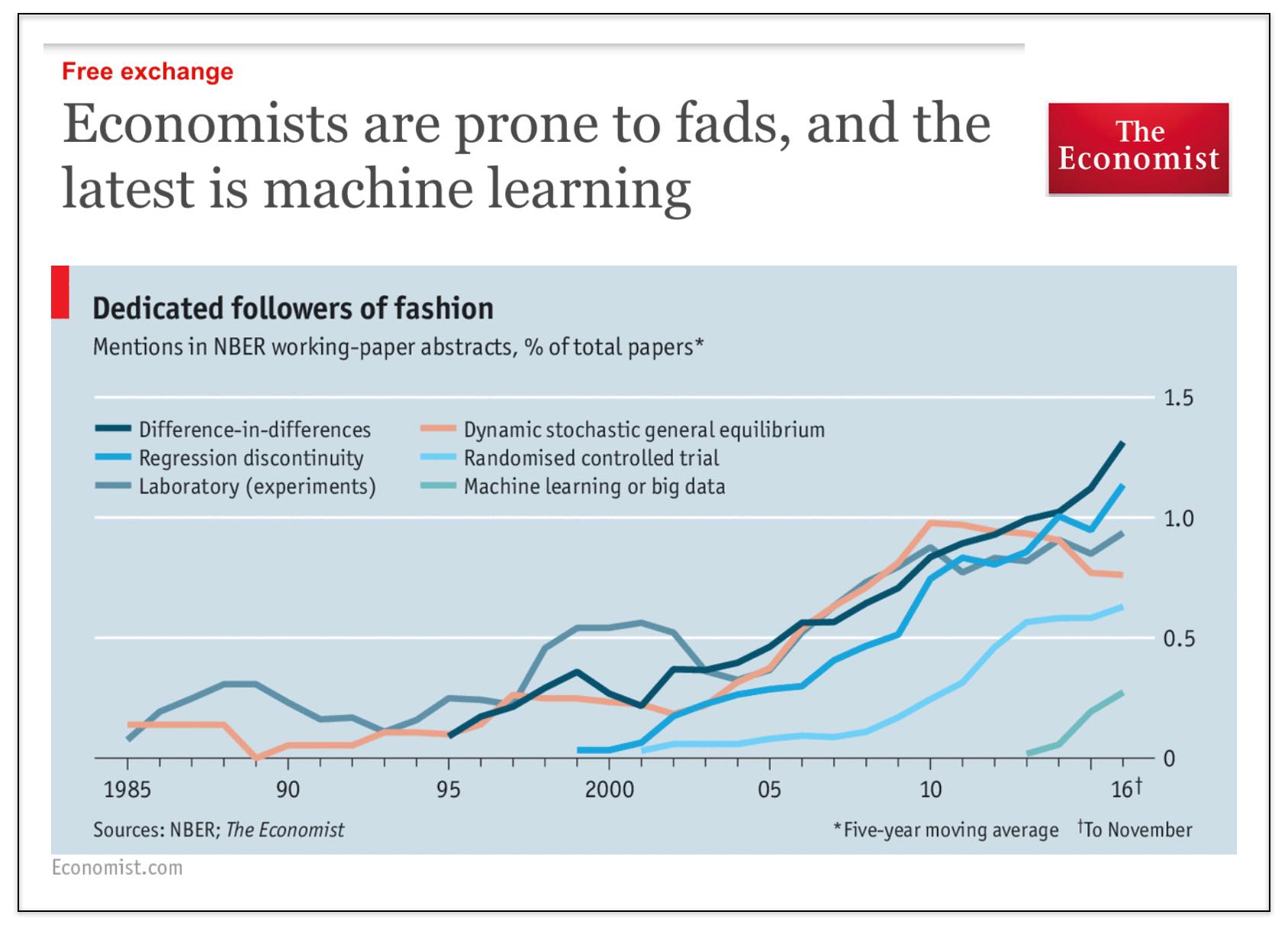
We started this blog (7 years ago) because we thought that there was insufficient attention to computational methods in law (NLP, ML, NetSci, etc.) Over the years this blog has evolved to become mostly a blog about the business of law (and business more generally) and the world is being impacted by automation, artificial intelligence and more broadly by information technology.
However, returning to our roots here — it is pretty interesting to see that the Economist has identified that #MachineLearning is finally coming to economics (pol sci + law as well).
Social science generally (and law as a late follower of developments in social science) it is still obsessed with causal inference (i.e. diff in diff, regression discontinuity, etc.). This is perfectly reasonable as it pertains to questions of evaluating certain aspects of public policy, etc.
However, there are many other problems in the universe that can be evaluated using tools from computer science, machine learning, etc. (and for which the tools of causal inference are not particularly useful).
In terms of the set of econ papers using ML, my bet is that a significant fraction of those papers are actually from finance (where people are more interested in actually predicting stuff).
In my 2013 article in Emory Law Journal called Quantitative Legal Prediction – I outline this distinction between causal inference and prediction and identify just a small set of the potential uses of predictive analytics in law. In some ways, my paper is already somewhat dated as the set of use cases has only grown. That said, the core points outlined therein remains fully intact …
 From the article: “The prevalence of noise has been demonstrated in several studies. Academic researchers have repeatedly confirmed that professionals often contradict their own prior judgments when given the same data on different occasions. For instance, when software developers were asked on two separate days to estimate the completion time for a given task, the hours they projected differed by 71%, on average. When pathologists made two assessments of the severity of biopsy results, the correlation between their ratings was only .61 (out of a perfect 1.0), indicating that they made inconsistent diagnoses quite frequently. Judgments made by different people are even more likely to diverge. Research has confirmed that in many tasks, experts’ decisions are highly variable: valuing stocks, appraising real estate,sentencing criminals, evaluating job performance, auditing financial statements, and more. The unavoidable conclusion is that professionals often make decisions that deviate significantly from those of their peers, from their own prior decisions, and from rules that they themselves claim to follow.”
From the article: “The prevalence of noise has been demonstrated in several studies. Academic researchers have repeatedly confirmed that professionals often contradict their own prior judgments when given the same data on different occasions. For instance, when software developers were asked on two separate days to estimate the completion time for a given task, the hours they projected differed by 71%, on average. When pathologists made two assessments of the severity of biopsy results, the correlation between their ratings was only .61 (out of a perfect 1.0), indicating that they made inconsistent diagnoses quite frequently. Judgments made by different people are even more likely to diverge. Research has confirmed that in many tasks, experts’ decisions are highly variable: valuing stocks, appraising real estate,sentencing criminals, evaluating job performance, auditing financial statements, and more. The unavoidable conclusion is that professionals often make decisions that deviate significantly from those of their peers, from their own prior decisions, and from rules that they themselves claim to follow.”
Suffice to say we at LexPredict agree. Indeed, building from our work on Fantasy SCOTUS where our expert crowd outperforms any known single alternative (including the highest ranked Fantasy SCOTUS player), we have recently launched LexSemble (our configurable crowdsourcing platform) in order to help legal and other related organizations make better decisions (in transactions, litigation, regulatory matters, etc.).
We are working to pilot with a number of industry partners interested in applying underwriting techniques to more rigorously support their decision making. This is also an example of what we have been calling Fin(Legal)Tech (the financialization of law). If you want to learn more please sign up for our Fin(Legal)Tech conference coming on November 4th in Chicago) (tickets are free but space is limited).