The above image is a visualization of temporal citation patterns in the history of the United States Supreme Court. Each case is placed horizontally across the image in chronological order. We then draw citations between cases as curved arcs. We use three distinct arc colors to show qualitative differences between these citations:
RED arcs correspond to citations within a natural court (e.g., the Rehnquist court citing the Rehnquist court).
GREEN arcs correspond to citations from one natural court to the previous natural court (e.g., the Rehnquist court citing the Burger court).
BLUE arcscorrespond to citations from one natural court to a natural court prior to the previous natural court (e.g., the the Rehnquist court citing the Marshall court).
Note that yellow is produced when red and green overlap.
Though there are many ways to interpret this data, we wanted to provide three simple conclusions to draw:
The number of cases decided within each natural court varies dramatically. For instance, the Rehnquist court decided fewer cases than the Fuller court.
Most citations are to recent cases, not cases in the distant past.
The Burger and Rehnquist courts rely heavily on cases from the Hughes, Stone, and Vinson courts
The United States Supreme Court has recently launched its newly redesigned website. Given the significant limitations associated with the prior website, this launch had been highly anticipated. Indeed, many had hoped for a website that would reflect well upon the Court. While we applaud the decision to move away from the prior design, a review of the Court’s new website reveals a product which still falls far below the mark.
One of the very disappointing aspects of the new interface is that it appears to have been created with little regard for the overtures offered by folks such as the Sunlight Foundation. Specifically, in an effort to improve the experience of end users, the Sunlight Foundation offered a very constructive mockup redesign for the website. Unfortunately, the current redesign does not reflect most of their ideas.
For those interested in additional thoughts on this matter, the good folks over at Law Librarian Blog offer a number of constructive suggestions for improvements. These include unlocking PDF documents by simultaneously making their content available in friendly formats such as XML / HTML. Anyway, we hope that this is merely one step in the direction of genuine improvement …. but given the current state of affairs … the path to a 21st century website for the United States Supreme Court looks to be quite long.
(1) The Supreme Court’s increasing reliance upon its own decisions over the 1800-1830 window.
(2) The important role of maritime/admiralty law in the early years of the Supreme Court’s citation network. At least with respect to the Supreme Court’s citation network, these maritime decisions are the root of the Supreme Court’s jurisprudence.
The Development of Structure in the SCOTUS Citation Network
The visualization offered above is the largest weakly connected component of the citation network of the United States Supreme Court (1800-1829). Each time slice visualizes the aggregate network as of the year in question.
In our paper entitled Distance Measures for Dynamic Citation Networks, we offer some thoughts on the early SCOTUS citation network. In reviewing the visual above note ….“[T]he Court’s early citation practices indicate a general absence of references to its own prior decisions. While the court did invoke well-established legal concepts, those concepts were often originally developed in alternative domains or jurisdictions. At some level, the lack of self-reference and corresponding reliance upon external sources is not terribly surprising. Namely, there often did not exist a set of established Supreme Court precedents for the class of disputes which reached the high court. Thus, it was necessary for the jurisprudence of the United States Supreme Court, seen through the prism of its case-to-case citation network, to transition through a loading phase. During this loading phase, the largest weakly connected component of the graph generally lacked any meaningful clustering. However, this sparsely connected graph would soon give way, and by the early 1820’s, the largest weakly connected component displayed detectable structure.”
What are the elements of the network?
What are the labels?
To help orient the end-user, the visualization highlights several important decisions of the United States Supreme Court offered within the relevant time period:
Why do cases not always enter the visualization when they are decided?
As we are interested in the core set of cases, we are only visualizing the largest weakly connected componentof the United States Supreme Court citation network. Cases are not added until they are linked to the LWCC. For example, Marbury v. Madison is not added to the visualization until a few years after it is decided.
How do I best view the visualization?
Given this is a high-definition video, it may take few seconds to load. We believe that it is worth the wait. In our view, the video is best consumed (1) Full Screen (2) HD On (3) Scaling Off.
Where can I find related papers?
Here is a non-exhaustive list of related scholarship:
(1) The Supreme Court’s increasing reliance upon its own decisions over the 1800-1830 window.
(2) The important role of maritime/admiralty law in the early years of the Supreme Court’s citation network. At least with respect to the Supreme Court’s citation network, these maritime decisions are the root of the Supreme Court’s jurisprudence.
The Development of Structure in the SCOTUS Citation Network
The visualization offered above is the largest weakly connected component of the citation network of the United States Supreme Court (1800-1829). Each time slice visualizes the aggregate network as of the year in question.
In our paper entitled Distance Measures for Dynamic Citation Networks, we offer some thoughts on the early SCOTUS citation network. In reviewing the visual above note ….“[T]he Court’s early citation practices indicate a general absence of references to its own prior decisions. While the court did invoke well-established legal concepts, those concepts were often originally developed in alternative domains or jurisdictions. At some level, the lack of self-reference and corresponding reliance upon external sources is not terribly surprising. Namely, there often did not exist a set of established Supreme Court precedents for the class of disputes which reached the high court. Thus, it was necessary for the jurisprudence of the United States Supreme Court, seen through the prism of its case-to-case citation network, to transition through a loading phase. During this loading phase, the largest weakly connected component of the graph generally lacked any meaningful clustering. However, this sparsely connected graph would soon give way, and by the early 1820’s, the largest weakly connected component displayed detectable structure.”
What are the elements of the network?
What are the labels?
To help orient the end-user, the visualization highlights several important decisions of the United States Supreme Court offered within the relevant time period:
Why do cases not always enter the visualization when they are decided?
As we are interested in the core set of cases, we are only visualizing the largest weakly connected componentof the United States Supreme Court citation network. Cases are not added until they are linked to the LWCC. For example, Marbury v. Madison is not added to the visualization until a few years after it is decided.
How do I best view the visualization?
Those interested in viewing the full screen video—click on the full screen icon contained in the Vimeo bottom banner. Check out the NEW Hi-Def (HD) version of the video!
We have spent the past couple days at the University of Pennsylvania where we presented information about our efforts to compile a complete United States Supreme Court Corpus. As noted in the slides below, we are interested in creating a corpus containing not only every SCOTUS opinion, but also every SCOTUS disposition from 1791-2010. Slight variants of the slides below were presented at the Penn Computational Linguistics Lunch (CLunch) and the Linguistic Data Consortium(LDC). We really appreciated the feedback and are looking forward to continue our work with the LDC. For those who might be interested, take a look at the slides embedded below or click on this link:
During our break from blogging, Ian Ayers offered a very interesting post over a Freakonomics entitled “Prediction Markets vs. Super Crunching: Which Can Better Predict How Justice Kennedy Will Vote?” In general terms, the post compares the well known statistical model offered by Martin-Quinn to the new Supreme Court Fantasy Leaguecreated by Josh Blackman. We were particularly interested in a sentence located at end of the post … “[T]he fantasy league predictions would probably be more accurate if market participants had to actually put their money behind their predictions (as with intrade.com).” This point is well taken. Extending the idea of having some “skin in the game,” we wondered what sort of intellectual returns could be generated for the field of quantitative Supreme Court prediction by some sort of Netflix style SCOTUS challenge.
The Martin-Quinn model has significantly advanced the field of quantitative analysis of the United States Supreme Court. However, despite all of the benefits the model has offered, it is unlikely to be the last word on the question. While only time will tell, an improved prediction algorithm might very well be generated through the application of ideas in machine learning and via incorporation of additional components such as text, citations, etc.
With significant financial sum at stake … even far less than the real Netflix challenge … it is certainly possible that a non-trivial mprovement could be generated. In a discussion among a few of us here at the Michigan CSCS lab,we generated the following non-exhaustive set of possible ground rules for a Netflix Style SCOTUS challenge:
To be unseated, the winning team should be required to make a non-trivial improvement upon the out-of-sample historical success of the Martin-Quinn Model.
To prevent overfitting, the authors of this non-trivial improvement should be required to best the existing model for some prospective period.
All of those who submit agree to publish their code in a standard programming language (C, Java, Python, etc.) with reasonable commenting / documentation.
This is a really great visualization. In just one poster, the authors convey a tremendous amount of relevant information to the end user. I would highly recommend acquiring this visualization for any SCOTUS fan on your holiday list!
Mike and I just spent a couple days a Washington University’s Center for Empirical Research in the Law for a meeting related to the Supreme Court Open Infrastructure Project. The meeting featured a number of great folks with cool data projects. The discussion was very fruitful and it is clear that the end product is going to offer a wide range of data relevant resources. We are looking forward to contribute to the project in the months to come!
So, I was a bit late on this … However, it is a really cool idea and thus I want to flag it for those who might have missed it. As covered over at SCOTUS Blog and ELS Blog, the November 12th Wall Street Journal features a story entitled “Statistical Time Travel Helps to Answer What-Ifs.” Of interest to legal scholars, Professors Andrew Martin and Kevin Quinn discuss a series of what-ifs including how today’s Supreme Court would have voted on Roe v. Wade … Check it out!
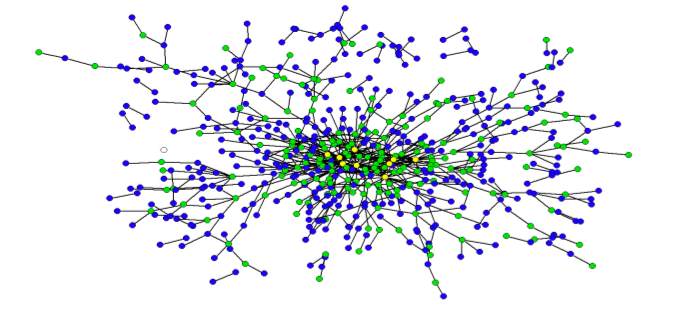
Together with Derek Stafford from the University of Michigan Department of Political Science, Hustle and Flow: A Social Network Analysis of the American Federal Judiciary represents our initial foray into Computational Legal Studies. The full paper contains a number of interesting visualizations where we draw various federal judges together on the basis of their shared law clerks (1995-2004). The screen print above is a zoom very center of the center of the network. Yellow Nodes represent Supreme Court Justices, Green Nodesrepresent Circuit Court Justices, Blue Nodes represent District Court Justices.
There exist many high quality formal models of judicial decision making including those considering decisions rendered by judges in judicial hierarchy, whistle blowing, etc. One component which might meaningfully contribute to the extent literature is the rigorous consideration of the social and professional relationships between jurists and the impacts (if any) these relationships impose upon outcomes. Indeed, from a modeling standpoint, we believe the “judicial game” is a game on a graph–one where an individual strategic jurist must take stock of time evolving social topology upon which he or she is operating. Even among judges of equal institutional rank, we observe jurists with widely variant levels social authority (specifically social authority follows a power law distribution).
So what does all of this mean? Take whistle blowing — the power law distribution implies that if the average judge has a whistle, the “super-judges” we identify within the paper could be said to have an air horn. With the goal of enriching positive political theory / formal modeling of the courts, we believe the development of a positive theory of judicial social structurecan enrich our understanding of the dynamics of prestige and influence. In addition, we believe, at least in part, “judicial peer effects” can help legal doctrine socially spread across the network. In that vein, here is a view of our operationalization of the social landscape … a wide shot of the broader network visualized using the Kamada-Kawai visualization algorithm:
Here is the current abstract for the paper: Scholars have long asserted that social structure is an important feature of a variety of societal institutions. As part of a larger effort to develop a fully integrated model of judicial decision making, we argue that social structure-operationalized as the professional and social connections between judicial actors-partially directs outcomes in the hierarchical federal judiciary. Since different social structures impose dissimilar consequences upon outputs, the precursor to evaluating the doctrinal consequences that a given social structure imposes is a descriptive effort to characterize its properties. Given the difficulty associated with obtaining appropriate data for federal judges, it is necessary to rely upon a proxy measure to paint a picture of the social landscape. In the aggregate, we believe the flow of law clerks reflects a reasonable proxy for social and professional linkages between jurists. Having collected available information for all federal judicial law clerks employed by an Article III judge during the “natural” Rehnquist Court (1995-2004), we use these roughly 19,000 clerk events to craft a series of network based visualizations. Using network analysis, our visualizations and subsequent analytics provide insight into the path of peer effects in the federal judiciary. For example, we find the distribution of “degrees” is highly skewed implying the social structure is dictated by a small number of socially prominent actors. Using a variety of centrality measures, we identify these socially prominent jurists. Next, we draw from the extant complexity literature and offer a possible generative process responsible for producing such inequality in social authority. While the complete adjudication of a generative process is beyond the scope of this article, our results contribute to a growing literature documenting the highly-skewed distribution of authority across the common law and its constitutive institutions.
As part our multipart series on the clerkship tournament, here is a simple bar graph for the top placing law schools in the Supreme Court Clerkship Tourney. It is important to note that we do not threshold for the number of graduates per school. Specifically, we do not just divide by the number graduates per school because we have little theoretic reason to believe that placements linearly scale to differences in size of graduating classes. In other words, given we do not know the proper functional form — we just offer the raw data. For those interested in other posts, please click herefor the law clerks tag.
As we mentioned in previous posts, Seadragon is a really cool product. Please note load times may vary depending upon your specific machine configuration as well as the strength of your internet connection. For those not familiar with how to operate it please see below. In our view, the Full Screen is best the way to go ….