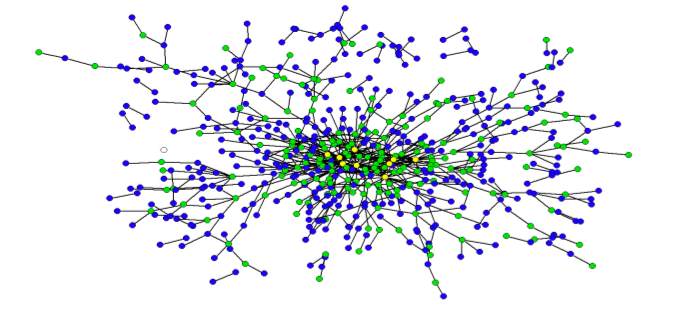
Understanding the sources of complexity in legal systems is a matter long considered by legal commentators. In tackling the question, scholars have applied various approaches including descriptive, theoretical and, in some cases, empirical analysis. The list is long but would certainly include work such as Long & Swingen (1987), Schuck (1992), White (1992), Kaplow (1995), Epstein (1997), Kades (1997), Wright (2000) and Holz (2007). Notwithstanding the significant contributions made by these and other scholars, we argue that an extensive empirical inquiry into the complexity of the law still remains to be undertaken.
While certainly just a slice of the broader legal universe, the United States Code represents a substantively important body of law familiar to both legal scholars and laypersons. In published form, the Code spans many volumes. Those volumes feature hundreds of thousands of provisions and tens of millions of words. The United States Code is obviously complicated, however, measuring its size and complexity has proven be non-trivial.
In our paper entitled, A Mathematical Approach to the Study of the United States Code we hope to contribute to the effort by formalizing the United States Code as a mathematical object with a hierarchical structure, a citation network and an associated text function that projects language onto specific vertices.
In the visualization above, Figure (a) is the full United States Code visualized to the section level. In other words, each ring is a layer of a hierarchical tree that halts at the section level. Of course, many sections feature a variety of nested sub-sections, etc. For example, the well known 26 U.S.C. 501(c)(3) is only shown above at the depth of Section 501. If we added all of these layers there would simply be additional rings. For those interested in the visualization of specific Titles of the United States Code … we have previously created fully zoomable visualizations of Title 17 (Copyright), Title 11 (Bankruptcy), Title 26 (Tax) [at section depth], Title 26 (Tax) [Capital Gains & Losses] as well as specific pieces of legislation such as the original Health Care Bill — HR 3962.
In the visualization above, Figure (b) combines this hierarchical structure together with a citation network. We have previously visualized the United States Code citation network and have a working paper entitled Properties of the United States Code Citation Network. Figure (b) is thus a realization of the full United States Code through the section level.
With this representation in place, it is possible to measure the size of the Code using its various structural features such as vertices V and its edges E. It is possible to measure the full Code at various time snapshots and consider whether the Code is growing or shrinking. Using a limited window of data, we observe growth not only in the size of the code but also its network of dependancies (i.e. its citation network).

Of course, growth in the size United States Code alone is not necessarily analogous to an increase in complexity. Indeed, while we believe in general the size of the code tends to contribute to “complexity,” some additional measures are needed. Thus, our paper features structural measurements such as number of sections, section sizes, etc.
In addition, we apply the well known Shannon Entropy measure (borrowed from Information Theory) to evaluate the “complexity” of the message passing / language contained therein. Shannon Entropy has a long intellectual history and has been used as a measure of complexity by many scholars. Here is the formula for Shannon entropy:

For those interested in reviewing the full paper, it is forthcoming in Physica A: Statistical Mechanics and its Applications. For those not familiar, Physica A is a journal published by Elsevier and is a popular outlet for Econophysics and Quantitative Finance. A current draft of the paper is available on the SSRN and the physics arXiv
We are currently working on a follow up paper that is longer, more detailed and designed for a general audience. Even if you have little or no interest in the analysis of the United States Code, we hope principles such as entropy, structure, etc. will prove useful in the measurement of other classes of legal documents including contracts, treaties, administrative regulations, etc.

 From our abstract: “Einstein’s razor, a corollary of Ockham’s razor, is often paraphrased as follows: make everything as simple as possible, but not simpler. This rule of thumb describes the challenge that designers of a legal system face—to craft simple laws that produce desired ends, but not to pursue simplicity so far as to undermine those ends. Complexity, simplicity’s inverse, taxes cognition and increases the likelihood of suboptimal decisions. In addition, unnecessary legal complexity can drive a misallocation of human capital toward comprehending and complying with legal rules and away from other productive ends.
From our abstract: “Einstein’s razor, a corollary of Ockham’s razor, is often paraphrased as follows: make everything as simple as possible, but not simpler. This rule of thumb describes the challenge that designers of a legal system face—to craft simple laws that produce desired ends, but not to pursue simplicity so far as to undermine those ends. Complexity, simplicity’s inverse, taxes cognition and increases the likelihood of suboptimal decisions. In addition, unnecessary legal complexity can drive a misallocation of human capital toward comprehending and complying with legal rules and away from other productive ends.