 For the third installment of posts related to Reproduction of Hierarchy? A Social Network Analysis of the American Law Professoriate, we offer a Netlogo simulation of intellectual diffusion on the network we previously visualized. As noted in prior posts, we are interested legal socialization and its role in considering the spread of particular intellectual or doctrinal paradigms. This model captures a discrete run of the social epidemiological model we offer in the paper. As we noted within the paper, this represents a first cut on the question—where we favor parsimony over complexity. In reality, there obviously exist far more dynamics than we engage herein. The purpose of this exercise is simply to begin to engage the question. In our estimation, a positive theory of law should engage the sociology of the academy — a group who collectively socialize nearly every lawyer and judge in the United States. In the paper and in the model documentation, we offer some possible model extensions which could be considered in future scholarship.
For the third installment of posts related to Reproduction of Hierarchy? A Social Network Analysis of the American Law Professoriate, we offer a Netlogo simulation of intellectual diffusion on the network we previously visualized. As noted in prior posts, we are interested legal socialization and its role in considering the spread of particular intellectual or doctrinal paradigms. This model captures a discrete run of the social epidemiological model we offer in the paper. As we noted within the paper, this represents a first cut on the question—where we favor parsimony over complexity. In reality, there obviously exist far more dynamics than we engage herein. The purpose of this exercise is simply to begin to engage the question. In our estimation, a positive theory of law should engage the sociology of the academy — a group who collectively socialize nearly every lawyer and judge in the United States. In the paper and in the model documentation, we offer some possible model extensions which could be considered in future scholarship.
Once you click through to the model, here is how it works:
(1) Click the Setup Button in the Upper Left Corner. This will Display the Network in the Circular Layout.
(2) Click the Layout Button. Depending upon the speed of your machine this may take up to 30 seconds. Stop the Layout Button by Re-Clicking the Button.
(3) Click the Size Nodes by Degree Button. You Will Notice the Fairly Central Node Colored in Red. This is School #12 Northwestern University Law School. Observe how we have set the default infected school as #12 Northwestern (Hat Tip to Uri Wilensky). A Full List of School Number is available at the bottom of the page when you click through.
(4) Now, we are ready to begin. Click the Spread Once Button. The idea then reaches its neighbors with probability p (set as a default at .05). You can click the Toggle Infection Tree button (at any point) to observe the discrete paths traversed by the idea.
(5) Click the Spread Once Button, again and again. Notice the plot tracking the time on the x axisand the number of institution infected on the y axis. This is an estimate of the diffusion curve for the institution.
(6) To restart the simulation, click the Reinfect One button. Prior to hitting this button, slide theInfected Slider to any Law School you would like to observe. Also, feel free to adjust the p slider to increase or decrease the infectiousness of the idea.
Please comment if you have any difficulty or questions. Note you must have Java 1.4.1 + installed on your computer. The Information Technology professionals at many institutions will have already installed this on your machine but if not you will need to download it. We hope you enjoy!



![IPMZ-ASNA[1]](http://computationallegalstudies.com/wp-content/uploads/2009/08/IPMZ-ASNA1.gif "IPMZ-ASNA[1]")







 At the recent
At the recent 
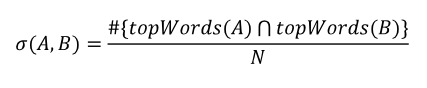 An edge exists between A and B in the set of edges if σ (A,B) exceeds some threshold. This threshold is the minimum similarity necessary for the graph to represent the presence of a semantic connection.”
An edge exists between A and B in the set of edges if σ (A,B) exceeds some threshold. This threshold is the minimum similarity necessary for the graph to represent the presence of a semantic connection.” 
