
Tag: computational linguistics
Complex Systems Models in the Social Science @ UMich ICPSR Summer Program in Quantitative Methods
 This week and next week I have the pleasure of teaching “Complex Systems Models in the Social Sciences” here at the University of Michigan ICPSR Summer Program in Quantitative Methods. The field of complex systems is very diverse and it is difficult to do complete justice to the range of scholarship conducted under this umbrella. However, we strive to cover the canonical topics such as computational game theory and computational modeling, network science, natural language processing, randomness vs. determinism, diffusion, cascades, emergence, empirical approaches to study complexity (including measurement), social epidemiology, non-linear dynamics, etc.
This week and next week I have the pleasure of teaching “Complex Systems Models in the Social Sciences” here at the University of Michigan ICPSR Summer Program in Quantitative Methods. The field of complex systems is very diverse and it is difficult to do complete justice to the range of scholarship conducted under this umbrella. However, we strive to cover the canonical topics such as computational game theory and computational modeling, network science, natural language processing, randomness vs. determinism, diffusion, cascades, emergence, empirical approaches to study complexity (including measurement), social epidemiology, non-linear dynamics, etc.
Using Algorithmic Attribution Techniques to Determine Authorship In Unsigned Judicial Opinions

From the Abstract: “This Article proposes a novel and provocative analysis of judicial opinions that are published without indicating individual authorship. Our approach provides an unbiased, quantitative, and computer scientific answer to a problem that has long plagued legal commentators. Our work uses natural language processing to predict authorship of judicial opinions that are unsigned or whose attribution is disputed. Using a dataset of Supreme Court opinions with known authorship, we identify key words and phrases that can, to a high degree of accuracy, predict authorship. Thus, our method makes accessible an important class of cases heretofore inaccessible. For illustrative purposes, we explain our process as applied to the Obamacare decision, in which the authorship of a joint dissent was subject to significant popular speculation. We conclude with a chart predicting the author of every unsigned per curiam opinion during the Roberts Court.” <HT: Josh Blackman>
International Conference on Artificial Intelligence and Law – ICAIL Rome 2013
 Today I had the pleasure of attending the opening workshops/tutorials at the ICAIL Conference in Rome. The program continues tomorrow with the core conference and accepted papers. While I unfortunately will not be able to attend all of the meeting, I suggest that you click here or above to access the program and list of presentations.
Today I had the pleasure of attending the opening workshops/tutorials at the ICAIL Conference in Rome. The program continues tomorrow with the core conference and accepted papers. While I unfortunately will not be able to attend all of the meeting, I suggest that you click here or above to access the program and list of presentations.
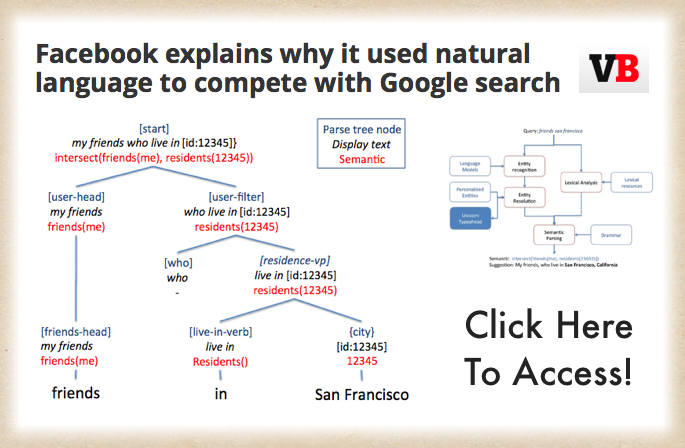

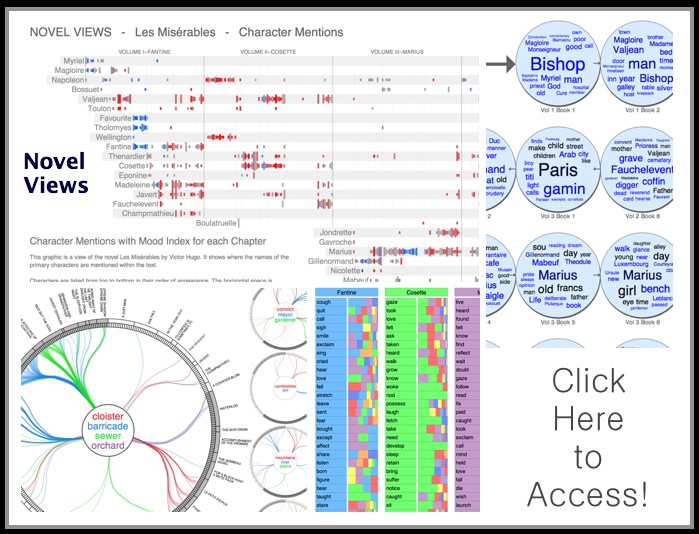
Partner Seeking Help On E-Discovery – or – Why it is a Good Idea to Learn Something About E-Discovery Before You Commit Malpractice
This semester here at Michigan State University College of Law, I am team teaching E-Discovery together with my colleague Adam Candeub. For a number of reasons, I enjoyed this video as it highlights the real gap in knowledge that exists between the tech infused Lawyer for the 21st Century and everyone else. The future belongs to the former and the time to acquire those skills is now!
Family Tree of Languages Has Roots in Anatolia, Biologists Say {via NY Times}
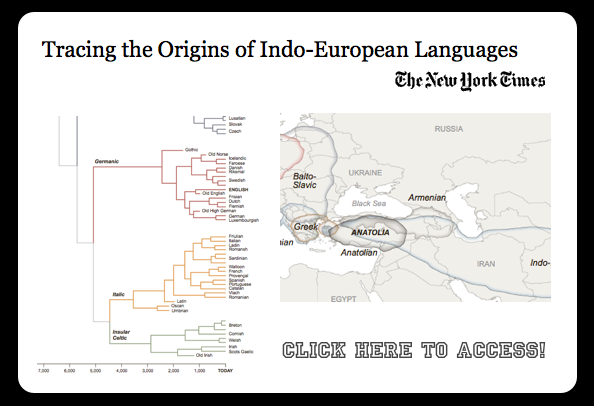 (1) Kinda amazing – the NY Times decided to have the public chew on a dendrogram – pretty damn cool 🙂
(1) Kinda amazing – the NY Times decided to have the public chew on a dendrogram – pretty damn cool 🙂
(2) Among other reasons, I also post this because this topic is of great import to the ungoing study of the origins of Western Civilization and Western Legal Thought. In particular, this is part of an important active conversation in the legal academy community – (see e.g. Rob Kar’s paper On the Origins of Western Law and Western Civilization (in the Indus Valley). Also, check out – The Early Eastern Origins of Western Law and Western Civilization: New Arguments for a Changed Understanding of Our Earliest Legal and Cultural Origins – Part I, Part II and Part III. They are a real tour de force!

6,000 Pages Tell the World’s History [via GE Data Visualization]
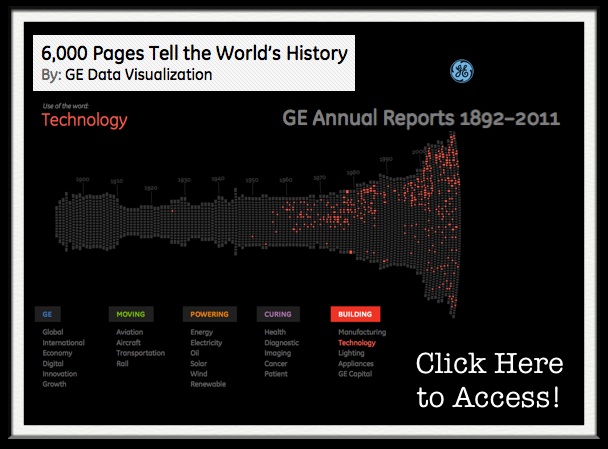 “It’s true. We’ve scanned 6,000 pages of GE’s annual reports to build this interactive visualization. But why? What’s the point? Not only does this provide a rich history of how GE has always been at work building, moving, powering and curing the world, but it is a true reflection of how the economy, U.S. and the world as a whole has progressed from 1892 until 2011. By diving deep into key terms, users can uncover interesting stories about innovation over the last century. Explore for yourself!
“It’s true. We’ve scanned 6,000 pages of GE’s annual reports to build this interactive visualization. But why? What’s the point? Not only does this provide a rich history of how GE has always been at work building, moving, powering and curing the world, but it is a true reflection of how the economy, U.S. and the world as a whole has progressed from 1892 until 2011. By diving deep into key terms, users can uncover interesting stories about innovation over the last century. Explore for yourself!
About this data: The data in this visualization is sourced from all of GE’s annual reports from 1892 until 2011.”
You Had Me at Hello: How Phrasing Affects Memorability [via arXiv.org]
 From the Abstract: “Understanding the ways in which information achieves widespread public awareness is a research question of significant interest. We consider whether, and how, the way in which the information is phrased — the choice of words and sentence structure — can affect this process. To this end, we develop an analysis framework and build a corpus of movie quotes, annotated with memorability information, in which we are able to control for both the speaker and the setting of the quotes. We find significant differences between memorable and non-memorable quotes in several key dimensions. One is lexical distinctiveness: in aggregate, memorable quotes use less common word choices, but at the same time are built upon a scaffolding of common syntactic patterns; another is that memorable quotes tend to be more general in ways that make them easy to apply in new contexts. We also show how the concept of “memorable language” can be extended across domains.”
From the Abstract: “Understanding the ways in which information achieves widespread public awareness is a research question of significant interest. We consider whether, and how, the way in which the information is phrased — the choice of words and sentence structure — can affect this process. To this end, we develop an analysis framework and build a corpus of movie quotes, annotated with memorability information, in which we are able to control for both the speaker and the setting of the quotes. We find significant differences between memorable and non-memorable quotes in several key dimensions. One is lexical distinctiveness: in aggregate, memorable quotes use less common word choices, but at the same time are built upon a scaffolding of common syntactic patterns; another is that memorable quotes tend to be more general in ways that make them easy to apply in new contexts. We also show how the concept of “memorable language” can be extended across domains.”