ABSTRACT: OpenEDGAR is an open source Python framework designed to rapidly construct research databases based on the Electronic Data Gathering, Analysis, and Retrieval (EDGAR) system operated by the US Securities and Exchange Commission (SEC). OpenEDGAR is built on the Django application framework, supports distributed compute across one or more servers, and includes functionality to (i) retrieve and parse index and filing data from EDGAR, (ii) build tables for key metadata like form type and filer, (iii) retrieve, parse, and update CIK to ticker and industry mappings, (iv) extract content and metadata from filing documents, and (v) search filing document contents. OpenEDGAR is designed for use in both academic research and industrial applications, and is distributed under MIT License at https://github.com/LexPredict/openedgar
Thanks to everyone who attended The Physics of Law Virtual Conference earlier this month. Overall, we had 292+ Attendees from 48 Countries watch the presentation of 20 Academic Papers by 62 Authors. We saw a wide range of methods from Physics, Computer Science and Applied Mathematics devoted to the exploration of legal systems and their outputs.
Methodological approaches included Agent Based Modeling, Game Theory and other Formal Modeling, Dynamics of Acyclic Digraphs, Knowledge Graphs, Entropy of Legal Systems, Temporal Modeling of MultiGraphs, Information Diffusion, etc.
NLP Methods on display included traditional approaches such as TF-IDF, n-grams, entity identification and other metadata extraction as well as more advanced methods such as Bert, Word2Vec, GloVe, etc.
Methods were then applied to topics including Attorney Advocacy Networks, Statutory Outputs from Legislatures, various bodies of Regulations, Contracts, Patents, Shell Corporations, Common Law Systems, Legal Scholarship and Legal Rules ∩ Financial Systems.
If you have an eligible paper – it is not too late to submit – papers are due in January. After undergoing the Peer Review process — Look for the Final Papers to be published in Frontiers in Physics in 2021.
Over the next two days, we will have 20 Papers Presented from Scholars from Around the World …Click here to access the site so you can Sign Up for Day 2. If you would like to access the full agenda click here.
Over the past few years, we have hosted a number of conferences devoted to various sub-topics in legal innovation including The Make Law Better Conference, Fin Legal Tech Conference and the Block Legal Tech Conference. We have aggregated videos from these events on TheLawLabChannel.comfor you to enjoy at your convenience.
As Mike Bommarito,Eric Detterman and I often discuss – one of the consistent themes in the Legal Tech / Legal Analytics space is the disconnect between what might be called ‘ad hoc’ data science and proper enterprise grade products / approaches (whether B2B or B2C). As part of the organizational maturity process, many organizations who decide that they must ‘get data driven’ start with an ad hoc approach to leveraging doing data science. Over time, it then becomes apparent that a more fundamental and robust undertaking is what is actually needed.
Similar dynamics also exist within the academy as well. Many of the code repos out there would not be considered proper production grade data science pipelines. Among other things, this makes deployment, replication and/or extension quite difficult.
Anyway, this blog post from Neptune.ai outlines just some of these issues.
ABSTRACT: While many informal factors influence how people interact, modern societies rely upon law as a primary mechanism to formally control human behaviour. How legal rules impact societal development depends on the interplay between two types of actors: the people who create the rules and the people to which the rules potentially apply. We hypothesise that an increasingly diverse and interconnected society might create increasingly diverse and interconnected rules, and assert that legal networks provide a useful lens through which to observe the interaction between law and society. To evaluate these propositions, we present a novel and generalizable model of statutory materials as multidimensional, time-evolving document networks. Applying this model to the federal legislation of the United States and Germany, we find impressive expansion in the size and complexity of laws over the past two and a half decades. We investigate the sources of this development using methods from network science and natural language processing. To allow for cross-country comparisons over time, based on the explicit cross-references between legal rules, we algorithmically reorganise the legislative materials of the United States and Germany into cluster families that reflect legal topics. This reorganisation reveals that the main driver behind the growth of the law in both jurisdictions is the expansion of the welfare state, backed by an expansion of the tax state. Hence, our findings highlight the power of document network analysis for understanding the evolution of law and its relationship with society.
It has been a real pleasure to work with my transatlantic colleagues Corinna Coupette (Max Planck Institute for Informatics), Janis Beckedorf (Heidelberg University) and Dirk Hartung (Bucerius Law School). We have other projects also in the works — so stay tuned!
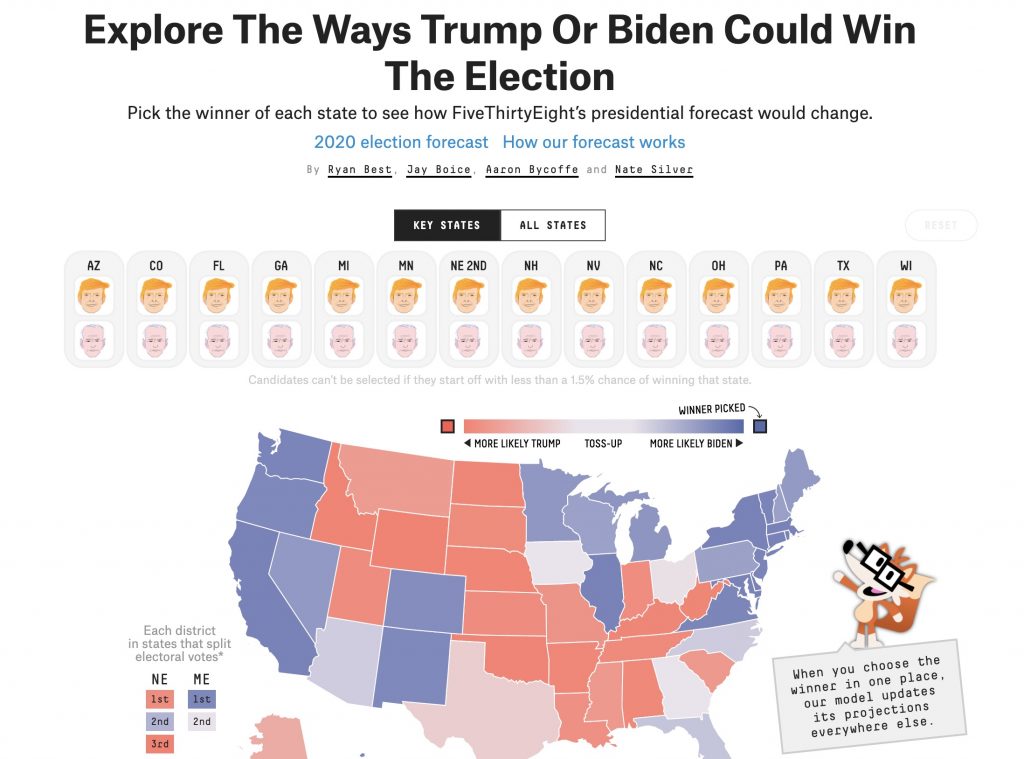
As it stands today, the Biden Campaign would appear quite likely but not guaranteed to win come November 3rd (or at some point thereafter). It could end early on November 3rd (if Florida appears to be trending toward Biden). Namely, it is hard to craft a scenario whereby Trump loses Florida and wins the White House. 538 has created an interactive where you can explore the inferential dynamics between the states (we learn about the likelihood in State B from the earlier results in State A). The interactive also highlights how results in early reporting states can reduce the remaining plausible paths to victory (there are only a few paths for Trump at this point).
Of course, it should be stated that remaining events or other issues could (potentially) change the dynamics or undermine the ability to leverage polls to make a proper inference. Here are few possibilities —
(1) Another October Surprise could drop between now and Election Day (there have already been several). However, it should be noted that one implication of all of this early voting is that the impact of a late October surprise is diminished.
(3) Turnout dynamics associated with the cocktail of early voting (very large numbers so far), large scale absentee ballots (including rejection of ballots, delays in mail, etc.) or fear of turning up to the polls due to our latest COVID surge (the Trump campaign is counting on a Election Day surge). Any or all could impact the final outcome.
That said, if I had to bet I would bet on Biden to win (and give far better than even money).
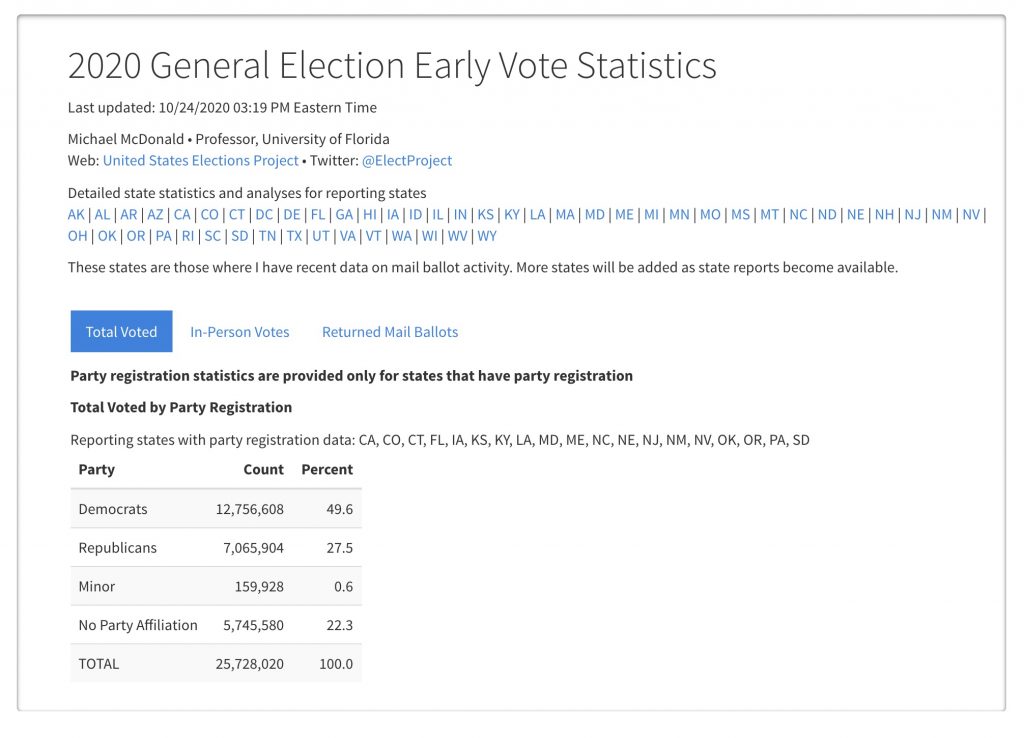
It is unprecedented turnout thus far. On its face this would purport to favor the Biden Campaign. However, the question remains whether this is merely a cannibalization of the normal Early In Person Voting and/or Election Day In Person Voting. In other words, how much will net turnout increase? Will it make a difference?
Taking Pennsylvania as a highly probable Tipping Point State, it will be interesting to see what percentage of mail in ballots are returned in the days to come. At the County level, there is significant variation in number of returned ballots thus far (even among those who have already requested a ballot).
Here is the PDF of DRAFT Agenda for our Online Academic Conference entitled “The Physics of Law” which will take place on November 12-13. We have 20 Accepted Paper Abstracts from Research Teams from Around the World. Access to the Conference is FREE – but Registration is Required. Sign Up Today at PhysicsOfLaw.com !
Papers presented at this Conference are part of a Special Track for Frontiers in Physics and will appear in 2021 (after undergoing the Peer Review Process). Note although this is a technical conference — papers will reflect a range of methodological approaches (i.e. may be either Theoretical or Empirical).
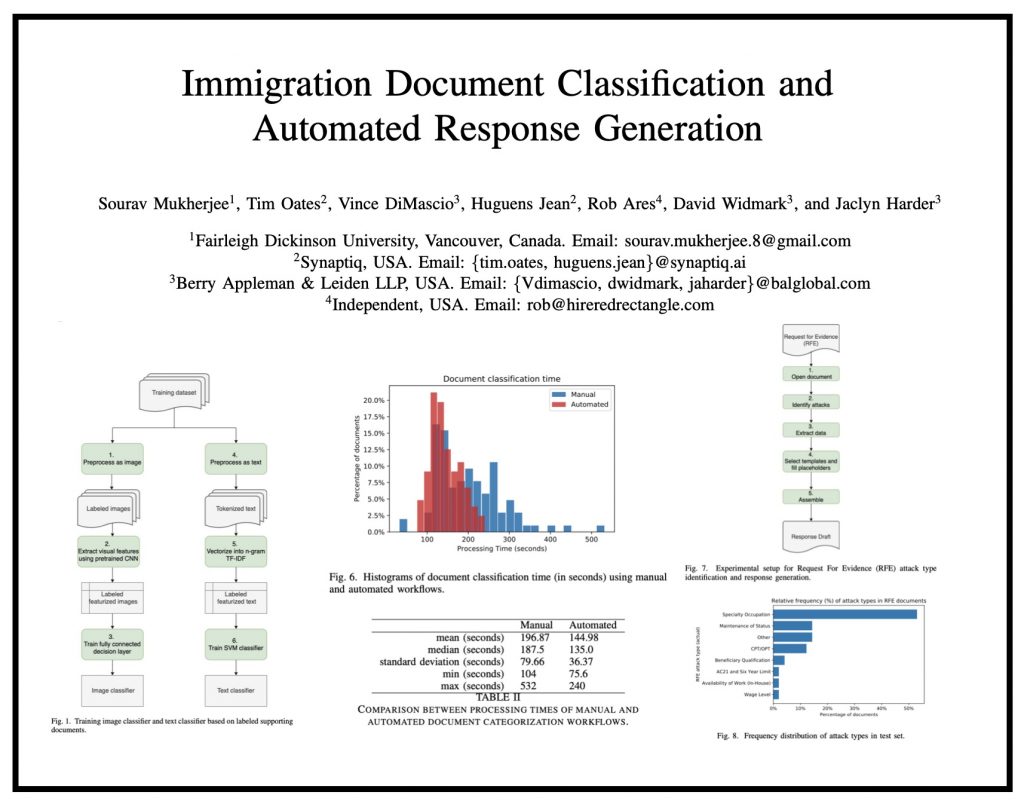
ABSTRACT: “In this paper, we consider the problem of organizing supporting documents vital to U.S. work visa petitions, as well as responding to Requests For Evidence (RFE) issued by the U.S.~Citizenship and Immigration Services (USCIS). Typically, both processes require a significant amount of repetitive manual effort. To reduce the burden of mechanical work, we apply machine learning methods to automate these processes, with humans in the loop to review and edit output for submission. In particular, we use an ensemble of image and text classifiers to categorize supporting documents. We also use a text classifier to automatically identify the types of evidence being requested in an RFE, and used the identified types in conjunction with response templates and extracted fields to assemble draft responses. Empirical results suggest that our approach achieves considerable accuracy while significantly reducing processing time.” Access Via arXiv — To Appear in ICDM 2020 workshop: MLLD-2020
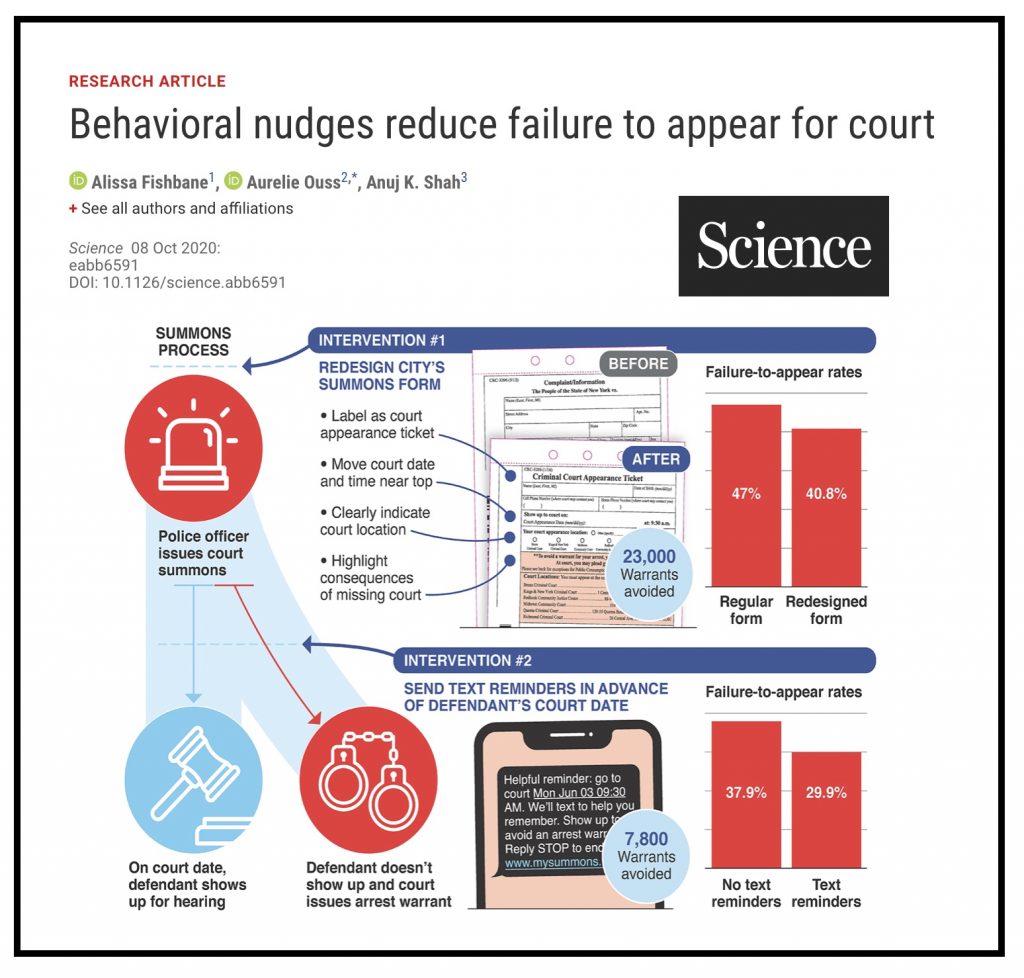
ABSTRACT: “Each year, millions of Americans fail to appear in court for low-level offenses, and warrants are then issued for their arrest. In two field studies in New York City, we make critical information salient by redesigning the summons form and providing text message reminders. These interventions reduce failures to appear by 13-21% and lead to 30,000 fewer arrest warrants over a 3-year period. In lab experiments, we find that while criminal justice professionals see failures to appear as relatively unintentional, laypeople believe they are more intentional. These lay beliefs reduce support for policies that make court information salient and increase support for punishment. Our findings suggest that criminal justice policies can be made more effective and humane by anticipating human error in unintentional offenses.” Access Full Article.
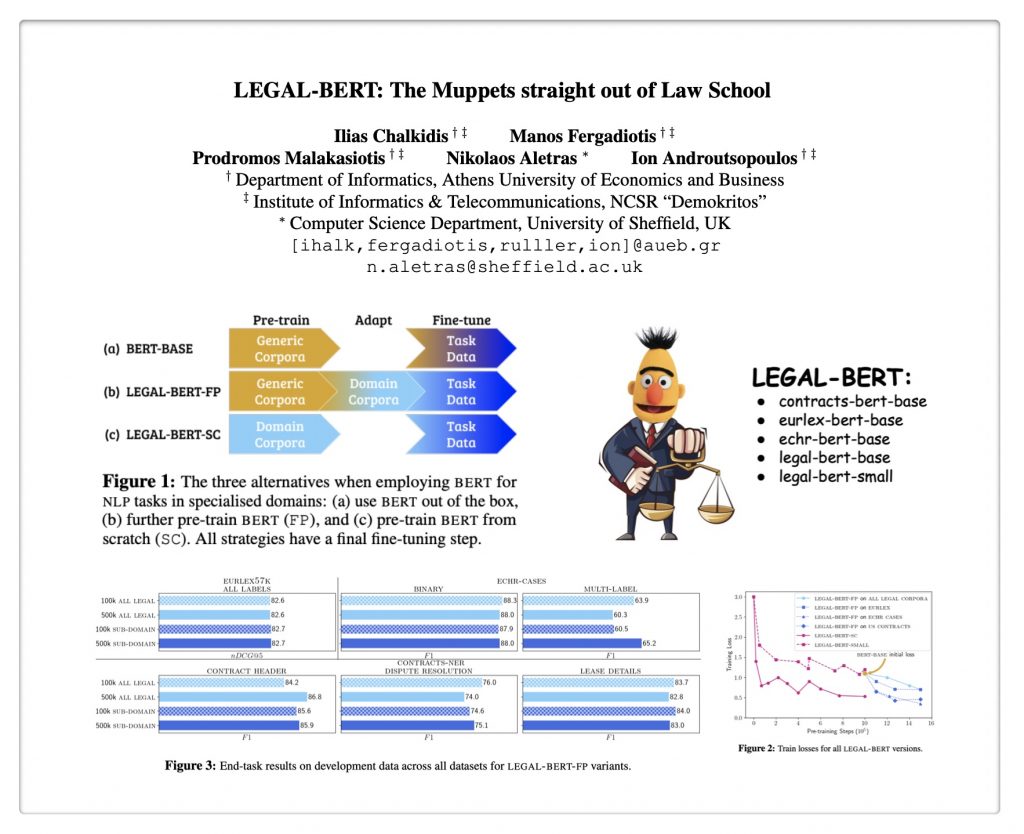
ABSTRACT: “BERT has achieved impressive performance in several NLP tasks. However, there has been limited investigation on its adaptation guidelines in specialised domains. Here we focus on the legal domain, where we explore several approaches for applying BERT models to downstream legal tasks, evaluating on multiple datasets. Our findings indicate that the previous guidelines for pre-training and fine-tuning, often blindly followed, do not always generalize well in the legal domain. Thus we propose a systematic investigation of the available strategies when applying BERT in specialised domains. These are: (a) use the original BERT out of the box, (b) adapt BERT by additional pre-training on domain-specific corpora, and (c) pre-train BERT from scratch on domain-specific corpora. We also propose a broader hyper-parameter search space when fine-tuning for downstream tasks and we release LEGAL-BERT, a family of BERT models intended to assist legal NLP research, computational law, and legal technology applications.”
In the legal scientific community, we are witnessing increasing efforts to connect general purpose NLP Advances to domain specific applications within law. First, we saw Word Embeddings (i.e. word2Vec, etc.) now Transformers (i.e BERT, etc.). (And dont forget about GPT-3, etc.) Indeed, the development of LexNLP is centered around the idea that in order to have better performing Legal AI – we will need to connect broader NLP developments to the domain specific needs within law. Stay tuned!
Papers presented at this Conference are part of a Special Track for Frontiers in Physics and will appear in 2021 (after undergoing the Peer Review Process).
After our Call for Papers — we have 20 Accepted Paper Abstracts for Papers which will presented at the Online Conference on November 12-13, 2020.
Note although this is a technical conference — papers will reflect a range of methodological approaches (i.e. may be either Theoretical or Empirical).
Access to the Conference is FREE – but Registration is Required. Sign Up Today at PhysicsOfLaw.com
Transformers (such as BERT, etc.) have suffered quadratic complexity in the number of tokens in the input sequence … which makes training incredibly laborious / expensive… so this is an important paper by researchers from Google, Cambridge and DeepMind …
ABSTRACT: “We introduce Performers, Transformer architectures which can estimate regular (softmax) full-rank-attention Transformers with provable accuracy, but using only linear (as opposed to quadratic) space and time complexity, without relying on any priors such as sparsity or low-rankness. To approximate softmax attention-kernels, Performers use a novel Fast Attention Via positive Orthogonal Random features approach (FAVOR+), which may be of independent interest for scalable kernel methods. FAVOR+ can be also used to efficiently model kernelizable attention mechanisms beyond softmax. This representational power is crucial to accurately compare softmax with other kernels for the first time on large-scale tasks, beyond the reach of regular Transformers, and investigate optimal attention-kernels. Performers are linear architectures fully compatible with regular Transformers and with strong theoretical guarantees: unbiased or nearly-unbiased estimation of the attention matrix, uniform convergence and low estimation variance. We tested Performers on a rich set of tasks stretching from pixel-prediction through text models to protein sequence modeling. We demonstrate competitive results with other examined efficient sparse and dense attention methods, showcasing effectiveness of the novel attention-learning paradigm leveraged by Performers.” ACCESS THE PAPER from arXiv.