

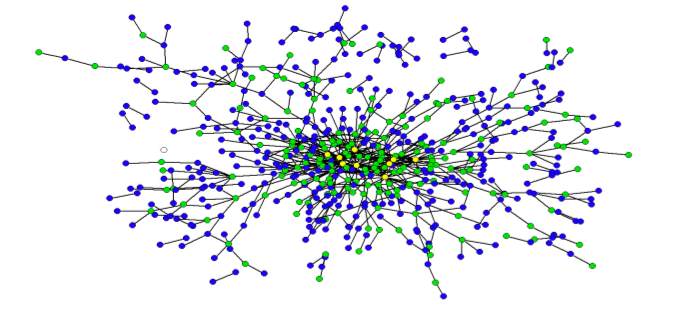
In addition to the facts we have presented on HR 3962, we wanted to offer a visualization for the structure of the Bill. Like many other bills, HR 3962, is divided into Divisions, Titles, Subtitles, Parts, Subparts, Sections, Subsections, Clauses, and Subclauses. These hierarchical splits represent the drafters’ conception of its organization, and thus the relative size of these categories may provide an indication of both the importance of each section of the Bill as well as the overall size of the document. By clicking through the image below, you can navigate a zoomable representation of the structure of HR 3962 using Microsoft’s Seadragon zoom interface. Many of the Divisions, Titles, Subtitles, Parts, and Subparts of the Bill are labeled. The balance are not labeled because they fell on an angle on the radial layout which rendered them impossible to read.
The graph is laid out in a radial manner with the center node labeled “H.R. 3962.” Legislation, the broader United States Code as well as many other classes of information are organized as hierarchical documents. H.R. 3962 is no different. For those less familiar with this type of documents, we thought it useful to provide a tutorial regarding (1) how to use this zoomable visualization (2) the correspondence between the visual and the Library of Congress version of H.R. 3962
How Do I Open/Navigate the Visualization?
(1) Open the Library of Congress version of H.R. 3962 in another browser window.
(2) Open the visualization by clicking on the large image above.
(3) Clicking on the image above will take you to the Seadragon platform. (Note: Load times will vary from machine to machine… so please be patient.)
(4) Seadragon allows for zoomable visualizations and for full screen viewing. Full screen is really the best way to go. If you run your mouse over the black box where the visual is located you will see four buttons in the southeast corner. The “full screen” button is the last one on the right. Click the button and you will be taken to full screen viewing!
(5) Click to zoom in and out, hold the mouse down and drag the entire visual, etc. Now, you are ready to traverse the graph using this visualization as your very own “H.R. 3962 Magic Decoder Wheel.”
How Do I Understand the Visualization?
To introduce the substance of the visualization, we have color coded two separate examples right into the visualization.
Example 1: Bills such as HR 3962 often feature a “short title” provision at the very begining of the legislation. For example, if you download the PDF copy of the bill, you can see the short title at the bottom of page 1 of the bill. You can also see this in the Library of Congress version of H.R. 3962.
SECTION 1. SHORT TITLE; TABLE OF DIVISIONS, TITLES, AND SUBTITLES.
(a) Short Title- This Act may be cited as the `Affordable Health Care for America Act’.
Zoom in close to start in the center where the large node labeled “HR 3962.” Notice the blue colorized path features the blue labels 1. and terminates with the label (a). The labels in the graph are the labels in the text above. While this is a simple example, the precise logic defines the entire graph.
Example 2: This is a bit more difficult as it requires the traversal of several provisions in order to reach a terminal node. In this case, the terminal node read as follows … “SEC. 401. INDIVIDUAL RESPONSIBILITY.For an individual’s responsibility to obtain acceptable coverage, see section 59B of the Internal Revenue Code of 1986 (as added by section 501 of this Act).”
DIVISION A–AFFORDABLE HEALTH CARE CHOICES
TITLE IV–SHARED RESPONSIBILITY
Subtitle A–Individual Responsibility
SEC. 401. INDIVIDUAL RESPONSIBILITY.
Again, zoom in close to start in the center--where the large node labeled “HR 3962.” Notice the blue colorized path features the blue labels A and terminates with the label 401. In between the start and finish, there are stops at IV and A, respectfully. Just as before, the labels in the graph are the labels in the text above. The end user can follow the precise journey but without the visual by using the Library of Congress version of H.R. 3962.








")





{kind=link}