
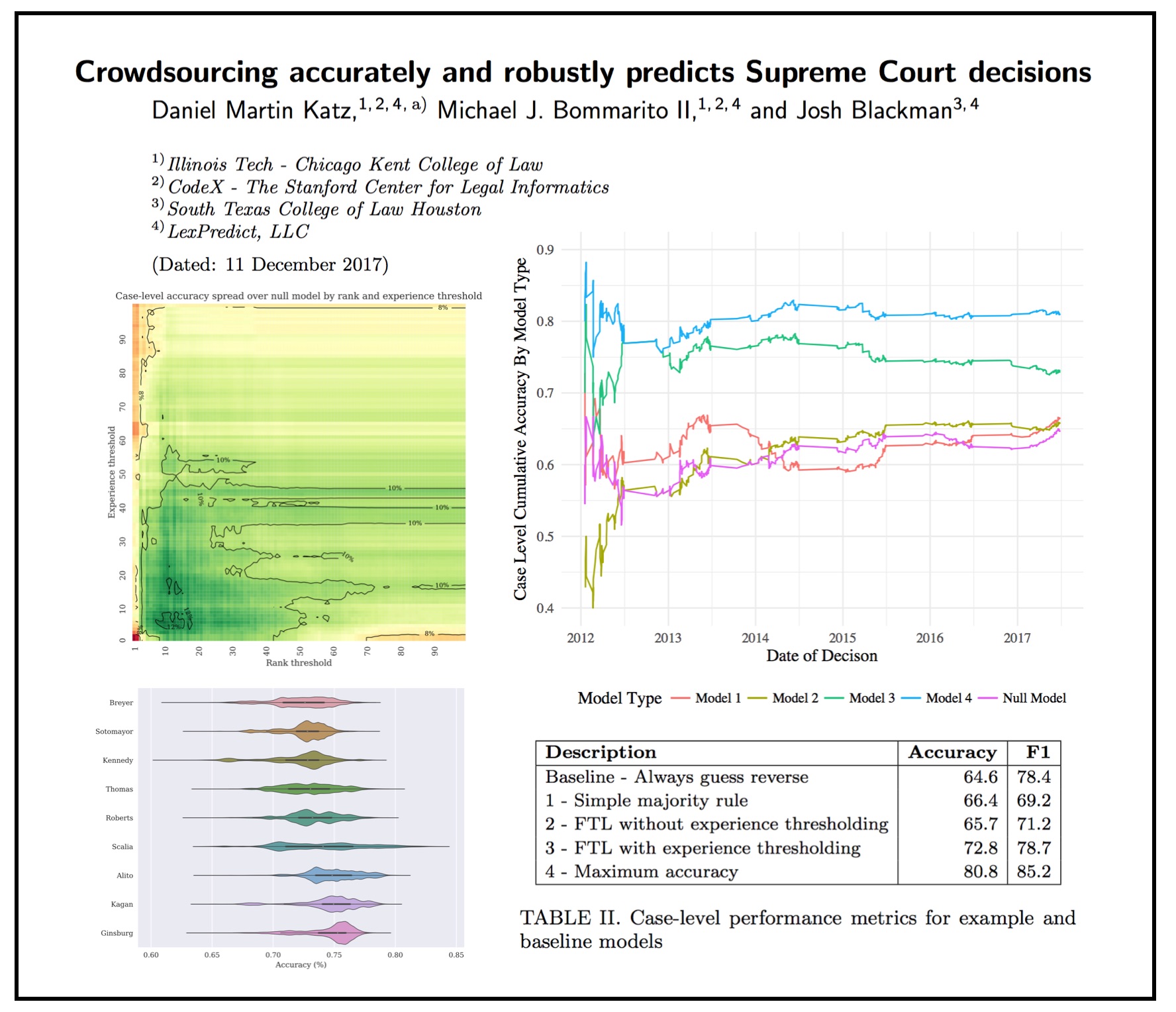
ABSTRACT: Scholars have increasingly investigated “crowdsourcing” as an alternative to expert-based judgment or purely data-driven approaches to predicting the future. Under certain conditions, scholars have found that crowd-sourcing can outperform these other approaches. However, despite interest in the topic and a series of successful use cases, relatively few studies have applied empirical model thinking to evaluate the accuracy and robustness of crowdsourcing in real-world contexts. In this paper, we offer three novel contributions. First, we explore a dataset of over 600,000 predictions from over 7,000 participants in a multi-year tournament to predict the decisions of the Supreme Court of the United States. Second, we develop a comprehensive crowd construction framework that allows for the formal description and application of crowdsourcing to real-world data. Third, we apply this framework to our data to construct more than 275,000 crowd models. We find that in out-of-sample historical simulations, crowdsourcing robustly outperforms the commonly-accepted null model, yielding the highest-known performance for this context at 80.8% case level accuracy. To our knowledge, this dataset and analysis represent one of the largest explorations of recurring human prediction to date, and our results provide additional empirical support for the use of crowdsourcing as a prediction method. (via SSRN)