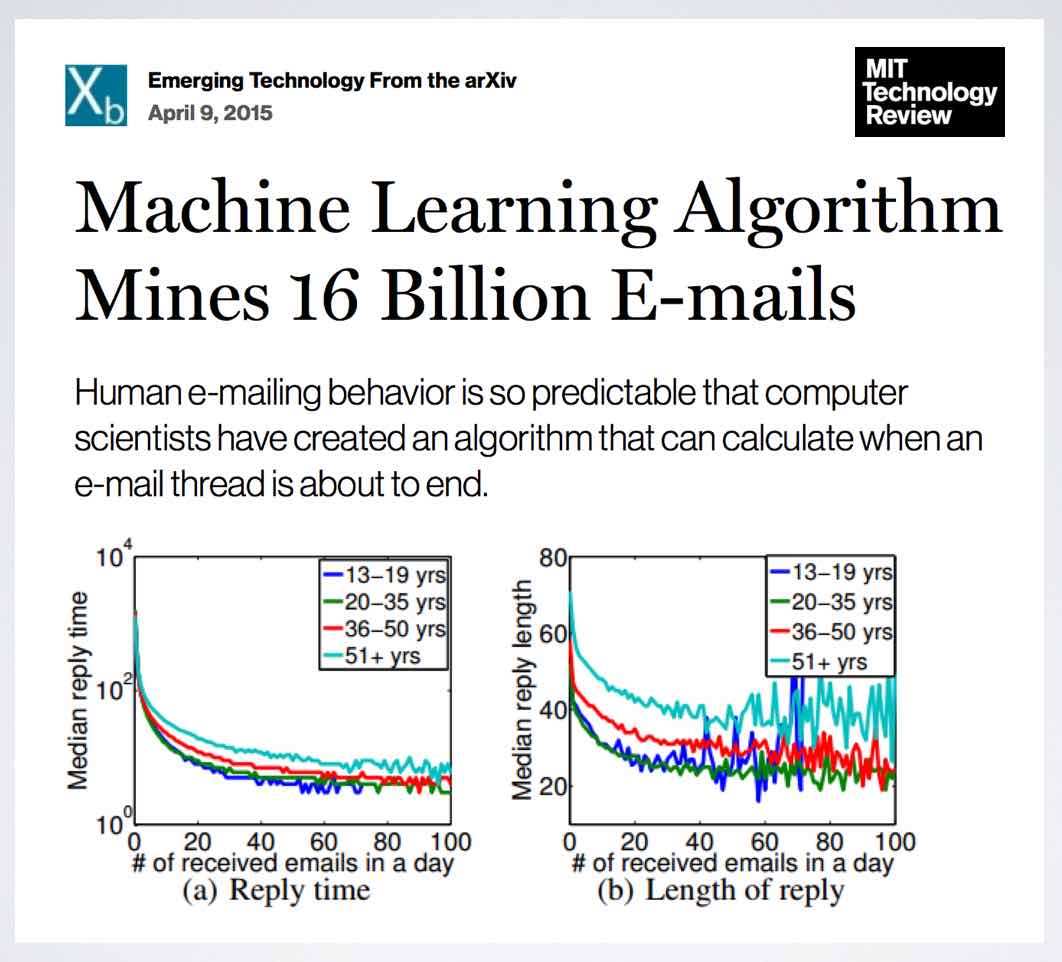
Tag: data mining

LexPredict – Empowering the Future of Legal Decision Making
LexPredict is an enterprise legal technology and consulting firm, specializing in the application of best-in-class processes and technologies from the technology, financial services, and logistics industries to the practice of law, compliance, insurance, and risk management.
We focus on the goals of prediction, optimization, and risk management to enable holistic organizational changes that empower legal decision-making. These changes span people and processes, software and data, and execution and education.
Law Firm COO & CFO Forum Pre-Conference Workshop on Big Data / Legal Analytics / Legal Informatics
 Yesterday I had the pleasure of participating in the Thomson Reuters Law Firm COO & CFO Forum Pre-Conference Workshop on Big Data. The half day workshop explored various way that law firms and outside counsel can use data to be better lawyers and run better businesses.
Yesterday I had the pleasure of participating in the Thomson Reuters Law Firm COO & CFO Forum Pre-Conference Workshop on Big Data. The half day workshop explored various way that law firms and outside counsel can use data to be better lawyers and run better businesses.
Here is the information for my panel (below) and the full program is located here.
Few business trends are as simultaneously revered, derided, appreciated or ignored as that of big data. Used (somewhat flippantly) to describe large, complex data sets that resist traditional data processing applications, big data represents both a beginning and end for many professional industries ill- prepared to harness big data’s myriad benefits and value. This opening conversation lays the framework for our program by addressing four key questions and concerns:
- What is big data?
- Why should we use it?
- Where does it lie within a business organization?
- How do we identify ROI and value in big data investment?
Moderator:
John Fernandez – US Chief Innovation Officer and Partner Dentons; Global Chair, NextLaw Labs
Panelists:
Justin Ergler – Director, Alternative Fee Intelligence and Analytics, GlaxoSmithKline
Daniel Martin Katz – Associate Professor of Law, Illinois Institute of Technology Chicago-Kent College of Law; Chief Strategy Officer, LexPredict
Michael S. Klastava – Vice President, Global Head of Legal Data & Analytics, American International Group, Inc.
Christopher Zorn – Liberal Arts Research Professor of Political Science and Sociology, The Pennsylvania State University; Principal, Quantitative Analysis, Lawyer Metrics
Econometrics (hereinafter Causal Inference) versus Machine Learning
 Perhaps some hyperbolic language in here but the basic idea is still intact … for law+economics / empirical legal studies – the causal inference versus machine learning point is expressed in detail in this paper called “Quantitative Legal Prediction.” Mike Bommarito and I have made this point in these slides, these slides, these slides, etc. Mike and I also make this point on Day 1 of our Legal Analytics Class (which really could be called “machine learning for lawyers”).
Perhaps some hyperbolic language in here but the basic idea is still intact … for law+economics / empirical legal studies – the causal inference versus machine learning point is expressed in detail in this paper called “Quantitative Legal Prediction.” Mike Bommarito and I have made this point in these slides, these slides, these slides, etc. Mike and I also make this point on Day 1 of our Legal Analytics Class (which really could be called “machine learning for lawyers”).


15th International Conference on Artificial Intelligence & Law — San Diego (Final Day for Priority Registration)
 As a member of the local organizing committee, I just wanted to mention that today is the final day for priority registration for the International Conference on Artificial Intelligence & Law in San Diego.
As a member of the local organizing committee, I just wanted to mention that today is the final day for priority registration for the International Conference on Artificial Intelligence & Law in San Diego.
Amazon Introduces a Cloud Service for Machine Learning (via Venture Beat)
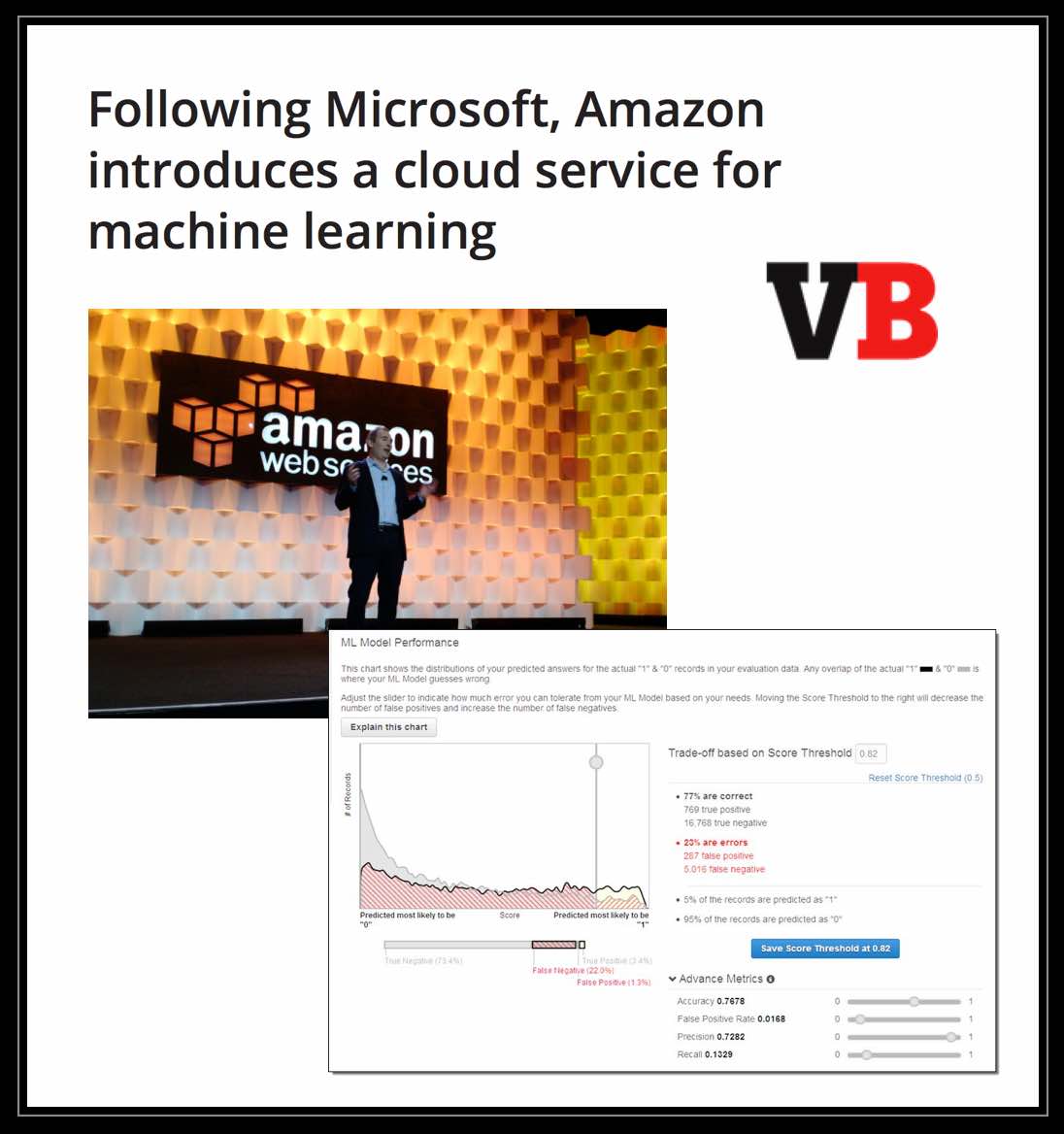
Suffice to say – this platform and competing platforms are going to collectively lower barriers to entry … and that is likely to have some implications (some good and some bad)