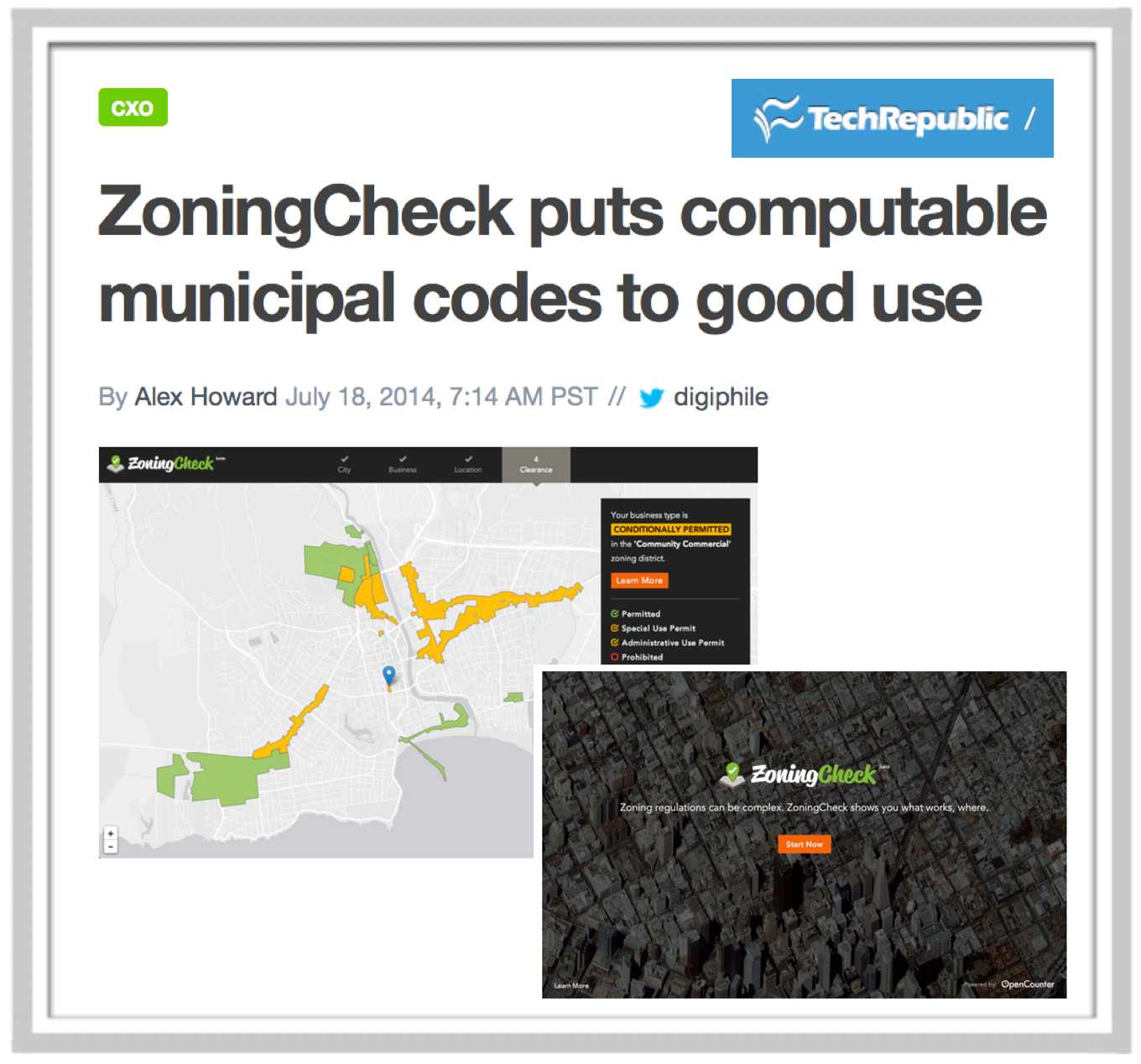
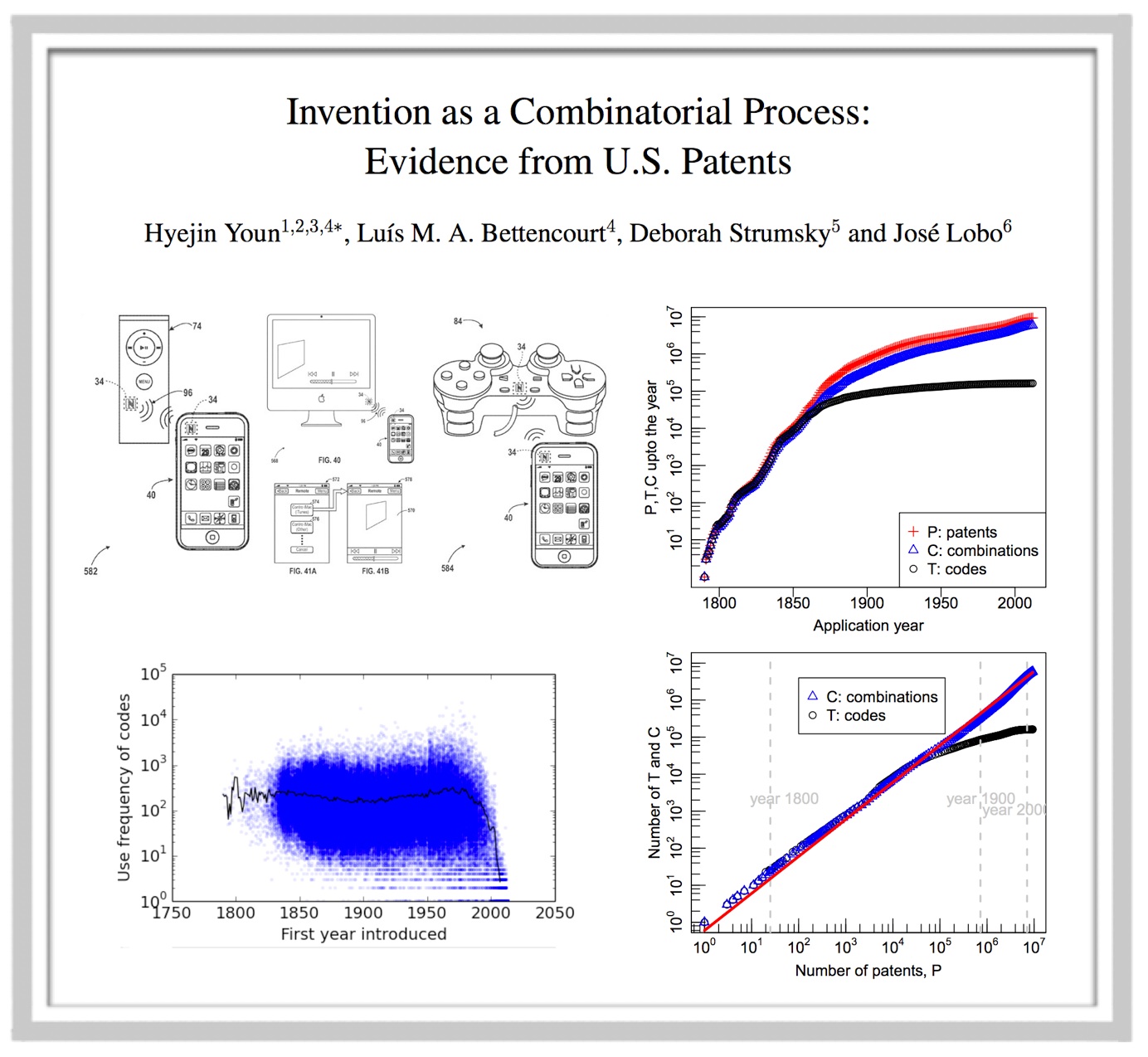
This intro class is designed to train students to efficiently manage, collect, explore, analyze, and communicate in a legal profession that is increasingly being driven by data.
This intro class is designed to train students to efficiently manage, collect, explore, analyze, and communicate in a legal profession that is increasingly being driven by data.
Our goal is to imbue our students with the capability to understand the process of extracting actionable knowledge from data, to distinguish themselves in legal proceedings involving data or analysis, and assist in firm and in-house management, including billing, case forecasting, process improvement, resource management, and financial operations.
This course assumes prior knowledge of statistics, such as might be obtained in Quantitative Methods for Lawyers or through advanced undergraduate curricula. This class is not for everyone; for many, it will prove to be challenging. With that warning, we encourage you to consider your interest and career aspirations against the unique experience and value of this class. To our knowledge, this is the only existing class that teaches these quantitative skills to lawyers and law students.
Still in beta – we will be adding much more to this site as we move forward!