See coverage of our paper in MIT Technology Review and access paper on arXiv or SSRN

See coverage of our paper in MIT Technology Review and access paper on arXiv or SSRN
WENDY RUBAS (VILLAGEMD)
FROM ANECDOTE TO ANALYTICS: WAYFINDING AS A MODERN GENERAL COUNSEL
JILLIAN BOMMARITO (LEXPREDICT)
IT’S 10 PM – DO YOU KNOW WHERE YOUR LEGAL RESERVES ARE?
DENNIS KENNEDY (MASTERCARD)
AGILE LAWYERING IN THE PLATFORM ERA
EDDIE HARTMAN (LEGALZOOM)
THE PRICE IS THE PROOF
NICOLE SHANAHAN (STANFORD CODEX)
TRANSACTION COSTS AND LEGAL AI: FROM COASE’S THEOREM TO IBM WATSON, AND EVERYTHING IN BETWEEN
ED WALTERS (FASTCASE)
LAW’S FUTURE FROM FINANCE’S PAST: WHAT COULD POSSIBLY GO WRONG?
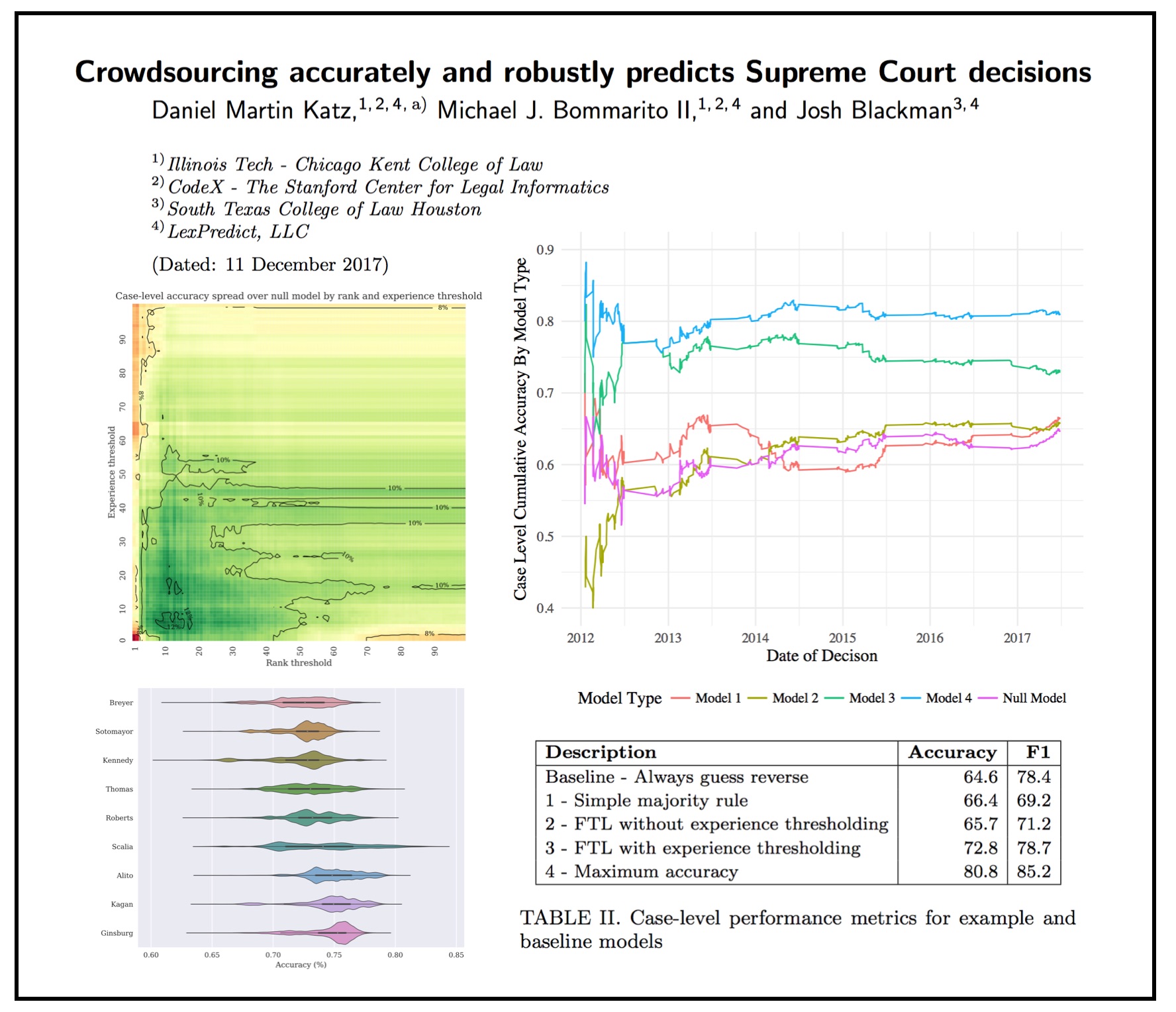
ABSTRACT: Scholars have increasingly investigated “crowdsourcing” as an alternative to expert-based judgment or purely data-driven approaches to predicting the future. Under certain conditions, scholars have found that crowd-sourcing can outperform these other approaches. However, despite interest in the topic and a series of successful use cases, relatively few studies have applied empirical model thinking to evaluate the accuracy and robustness of crowdsourcing in real-world contexts. In this paper, we offer three novel contributions. First, we explore a dataset of over 600,000 predictions from over 7,000 participants in a multi-year tournament to predict the decisions of the Supreme Court of the United States. Second, we develop a comprehensive crowd construction framework that allows for the formal description and application of crowdsourcing to real-world data. Third, we apply this framework to our data to construct more than 275,000 crowd models. We find that in out-of-sample historical simulations, crowdsourcing robustly outperforms the commonly-accepted null model, yielding the highest-known performance for this context at 80.8% case level accuracy. To our knowledge, this dataset and analysis represent one of the largest explorations of recurring human prediction to date, and our results provide additional empirical support for the use of crowdsourcing as a prediction method. (via SSRN)
 ABSTRACT: In this paper, we investigate the application of text classication methods to support law professionals. We present several experiments applying machine learning techniques to predict with high accuracy the ruling of the French Supreme Court and the law area to which a case belongs to. We also investigate the inuence of the time period in which a ruling was made on the form of the case description and the extent to which we need to mask information in a full case ruling to automatically obtain training and test data that resembles case descriptions. We developed a mean probability ensemble system combining the output of multiple SVM classiers. We report results of 98% average F1 score in predicting a case ruling, 96% F1 score for predicting the law area of a case, and 87.07% F1 score on estimating the date of a ruling
ABSTRACT: In this paper, we investigate the application of text classication methods to support law professionals. We present several experiments applying machine learning techniques to predict with high accuracy the ruling of the French Supreme Court and the law area to which a case belongs to. We also investigate the inuence of the time period in which a ruling was made on the form of the case description and the extent to which we need to mask information in a full case ruling to automatically obtain training and test data that resembles case descriptions. We developed a mean probability ensemble system combining the output of multiple SVM classiers. We report results of 98% average F1 score in predicting a case ruling, 96% F1 score for predicting the law area of a case, and 87.07% F1 score on estimating the date of a ruling
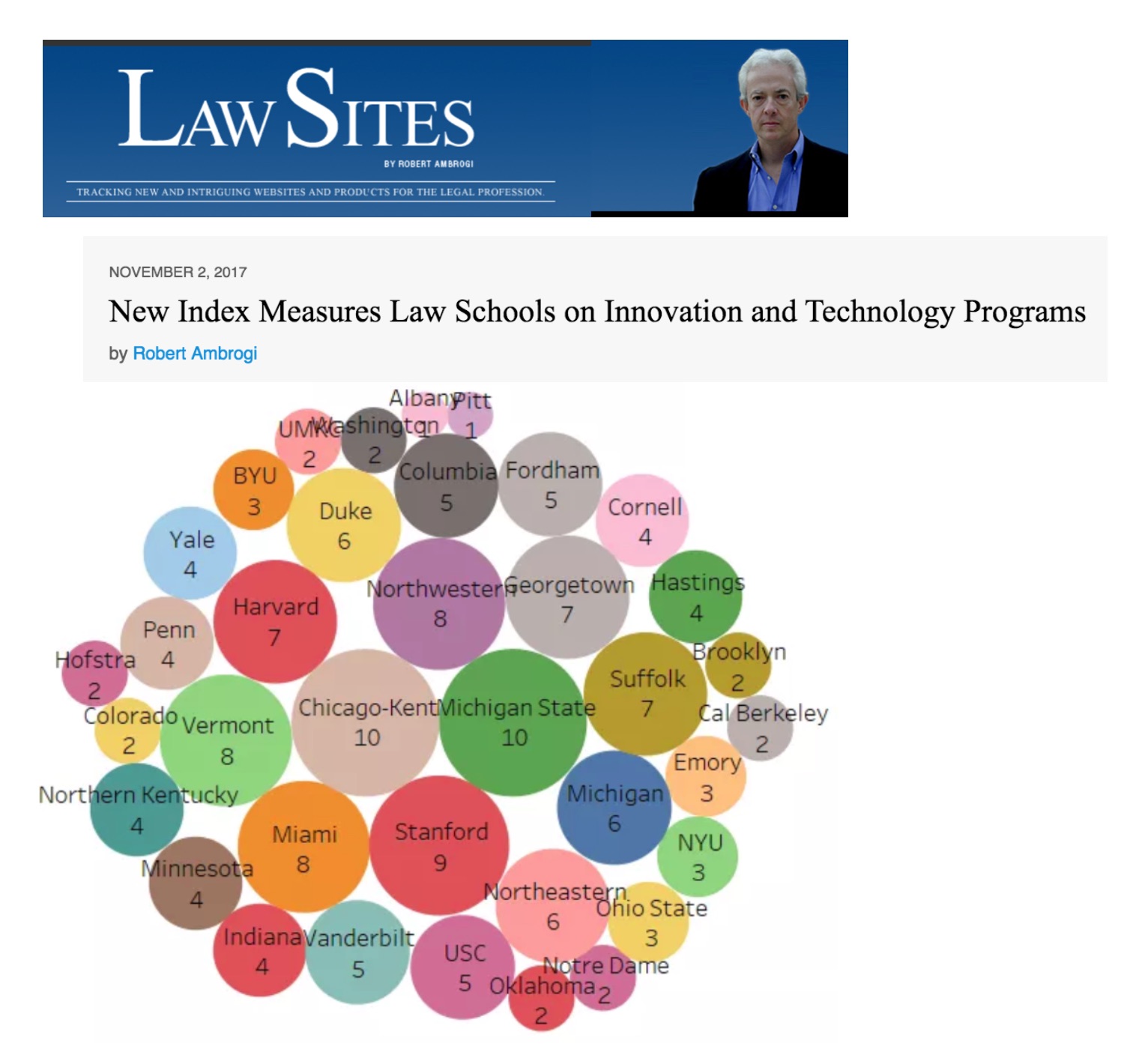
Access article here — whether or not this is precisely accurate – any measure that says The Law Lab @ Chicago Kent is #1 in Legal Innovation has to be correct 🙂

Very excited to be here for the Futures Conference of the College of Law Practice Management. Tonight I will be induced as as Fellow of the College (along with a range of other inductees).

Honored to deliver the keynote at yesterday’s NALP Summit on Emerging Careers for Law Grads

From the release: “At their core, many academic and commercial applications of natural language processing and machine learning can benefit from a controlled lexicon of expert-selected terms (i.e., a dictionary). This is especially true of highly technical language, such as legal text. However, after a search of the existing landscape, we were unable to find a high-quality open source or freely-available legal dictionary. Instead, the best existing versions, when available, exist under some form of restrictive licensing conditions.”
“Thus, in furtherance of both the legal profession as well as a range of legal technology providers and solutions, we are announcing another step in our broader open source plan that we outlined earlier this month. Namely, we are making available on Github the 1910 Version of Black’s Law (i.e., Black’s Law 2nd Edition) as a structured data object. This early version of arguably the premier legal dictionary is made available under the open source GPL license 3.0 which should allow both researchers and commercial providers to operate with limited restrictions.”
Click here to access the GitHub Repo.
This is an interesting development – click here to access story!