

Tag: legal analytics


MD Anderson Drops IBM Watson – A Setback For Artificial Intelligence In Medicine ?
 Not sure this is actually a “set back for AI in Medicine.” Rather, long story short — it ain’t 2014 anymore … as we discuss in our talk – Machine Learning as a Service : #MLaaS, Open Source and the Future of Legal Analytics – what started with Watson has turned into significant competition among major technology industry players. Throw in a some open source and you have some really strong economic forces which are upending even business models which were sound just three years ago …
Not sure this is actually a “set back for AI in Medicine.” Rather, long story short — it ain’t 2014 anymore … as we discuss in our talk – Machine Learning as a Service : #MLaaS, Open Source and the Future of Legal Analytics – what started with Watson has turned into significant competition among major technology industry players. Throw in a some open source and you have some really strong economic forces which are upending even business models which were sound just three years ago …
From the story — “The partnership between IBM and one of the world’s top cancer research institutions is falling apart. The project is on hold, MD Anderson confirms, and has been since late last year. MD Anderson is actively requesting bids from other contractors who might replace IBM in future efforts. And a scathing report from auditors at the University of Texas says the project cost MD Anderson more than $62 million and yet did not meet its goals. The report, however, states: ‘Results stated herein should not be interpreted as an opinion on the scientific basis or functional capabilities of the system in its current state’….”

Why Artificial Intelligence Might Replace Your Lawyer (via OYZ)
 “It’s the alignment of tech and economics that is allowing all this stuff to start moving … The real roll-up of all this isn’t robot lawyers, its financialization, with law becoming an applied branch of finance and insurance” says Daniel Martin Katz, professor at Illinois Tech’s Chicago Kent College of Law.
“It’s the alignment of tech and economics that is allowing all this stuff to start moving … The real roll-up of all this isn’t robot lawyers, its financialization, with law becoming an applied branch of finance and insurance” says Daniel Martin Katz, professor at Illinois Tech’s Chicago Kent College of Law.
The rate at which US Companies cite regulations as an obstacle has quadrupled over the last 20 years (via Quartz)
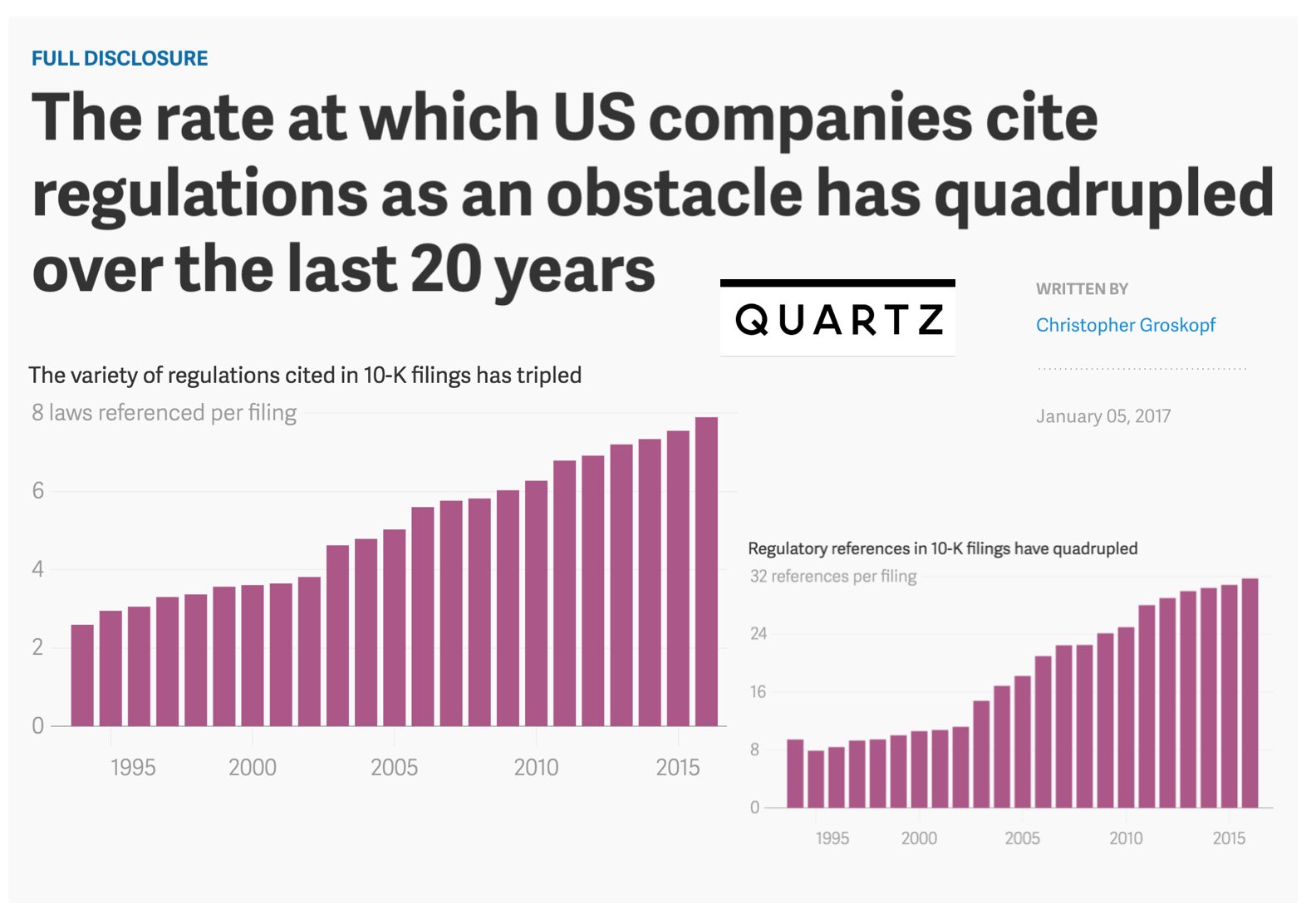 “Michael Bommarito II and Daniel Martin Katz, legal scholars at the Illinois Institute of Technology, have tried to measure the growth of regulation by analyzing more than 160,000 corporate annual reports, or 10-K filings, at the US Securities and Exchange Commission. In a pre-print paper released Dec. 29, the authors find that the average number of regulatory references in any one filing increased from fewer than eight in 1995 to almost 32 in 2016. The average number of different laws cited in each filing more than doubled over the same period.”
“Michael Bommarito II and Daniel Martin Katz, legal scholars at the Illinois Institute of Technology, have tried to measure the growth of regulation by analyzing more than 160,000 corporate annual reports, or 10-K filings, at the US Securities and Exchange Commission. In a pre-print paper released Dec. 29, the authors find that the average number of regulatory references in any one filing increased from fewer than eight in 1995 to almost 32 in 2016. The average number of different laws cited in each filing more than doubled over the same period.”
A General Approach for Predicting the Behavior of the Supreme Court of the United States (Paper Version 2.01) (Katz, Bommarito & Blackman)

Long time coming for us but here is Version 2.01 of our #SCOTUS Paper …
We have added three times the number years to the prediction model and now predict out-of-sample nearly two centuries of historical decisions (1816-2015). Then, we compare our results to three separate null models (including one which leverages in-sample information).
Here is the abstract: Building on developments in machine learning and prior work in the science of judicial prediction, we construct a model designed to predict the behavior of the Supreme Court of the United States in a generalized, out-of-sample context. Our model leverages the random forest method together with unique feature engineering to predict nearly two centuries of historical decisions (1816-2015). Using only data available prior to decision, our model outperforms null (baseline) models at both the justice and case level under both parametric and non-parametric tests. Over nearly two centuries, we achieve 70.2% accuracy at the case outcome level and 71.9% at the justice vote level. More recently, over the past century, we outperform an in-sample optimized null model by nearly 5%. Our performance is consistent with, and improves on the general level of prediction demonstrated by prior work; however, our model is distinctive because it can be applied out-of-sample to the entire past and future of the Court, not a single term. Our results represent an advance for the science of quantitative legal prediction and portend a range of other potential applications.
LexSemble – A Crowd Sourcing Platform Designed to Help Lawyers Make Better Decisions

When it comes to prediction – law would benefit from better applying the tools of STEM / Finance / Insurance and so in that spirit — our company recently launched LexSemble and it allows for near frictionless crowd sourcing of predictions in law (and beyond). Many potential applications in law including early (and ongoing) case assessment in litigation, forecasting various sorts of transactional outcomes and predicting the actions of regulators, etc. It also has a range of machine learning capabilities which allow for crowd segmentation, expert weighting, natural language processing on relevant documents, etc.
Learn More: https://lexsemble.com/features.html


