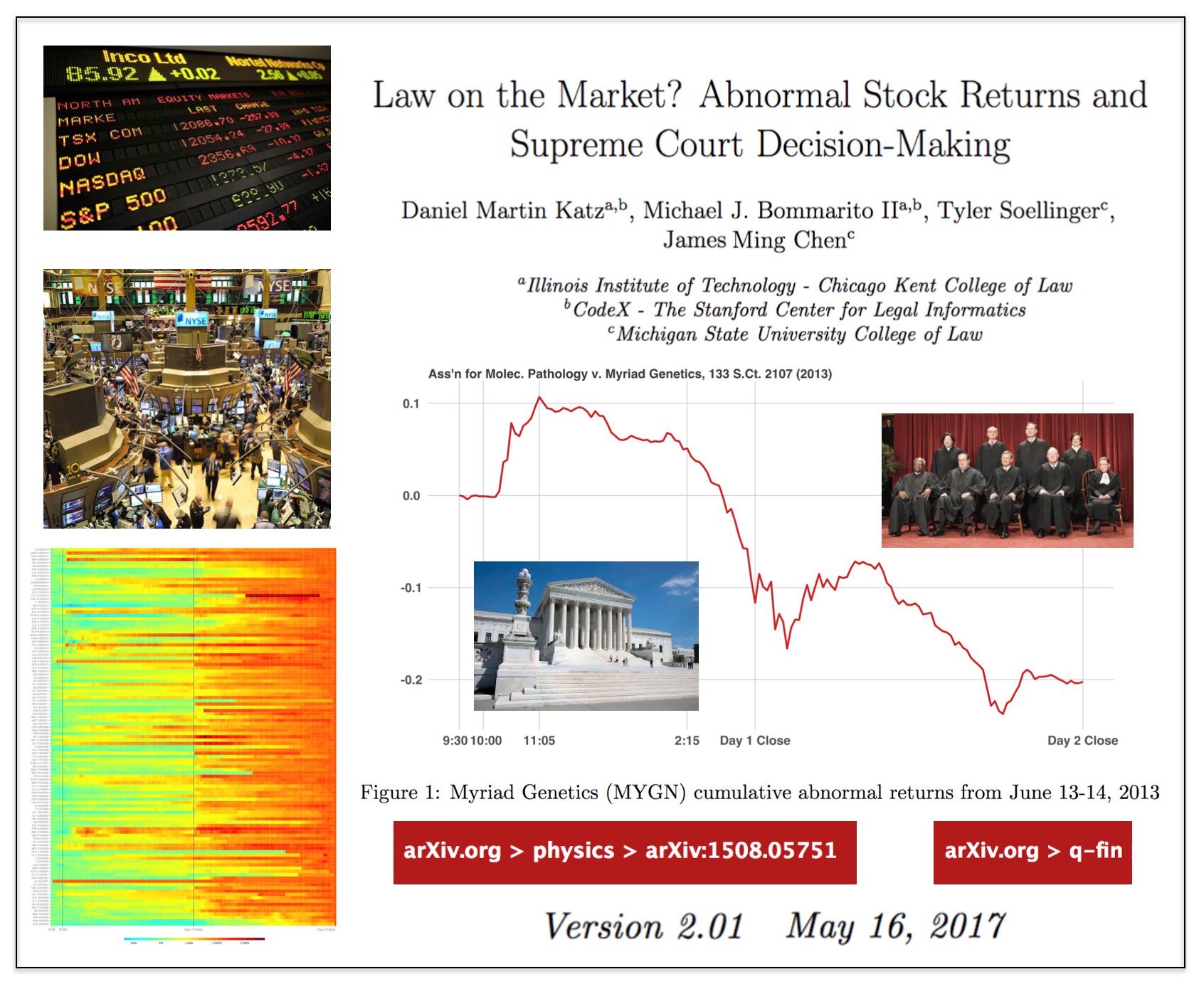
Long time coming for us but here is Version 2.01 of our #SCOTUS Paper …
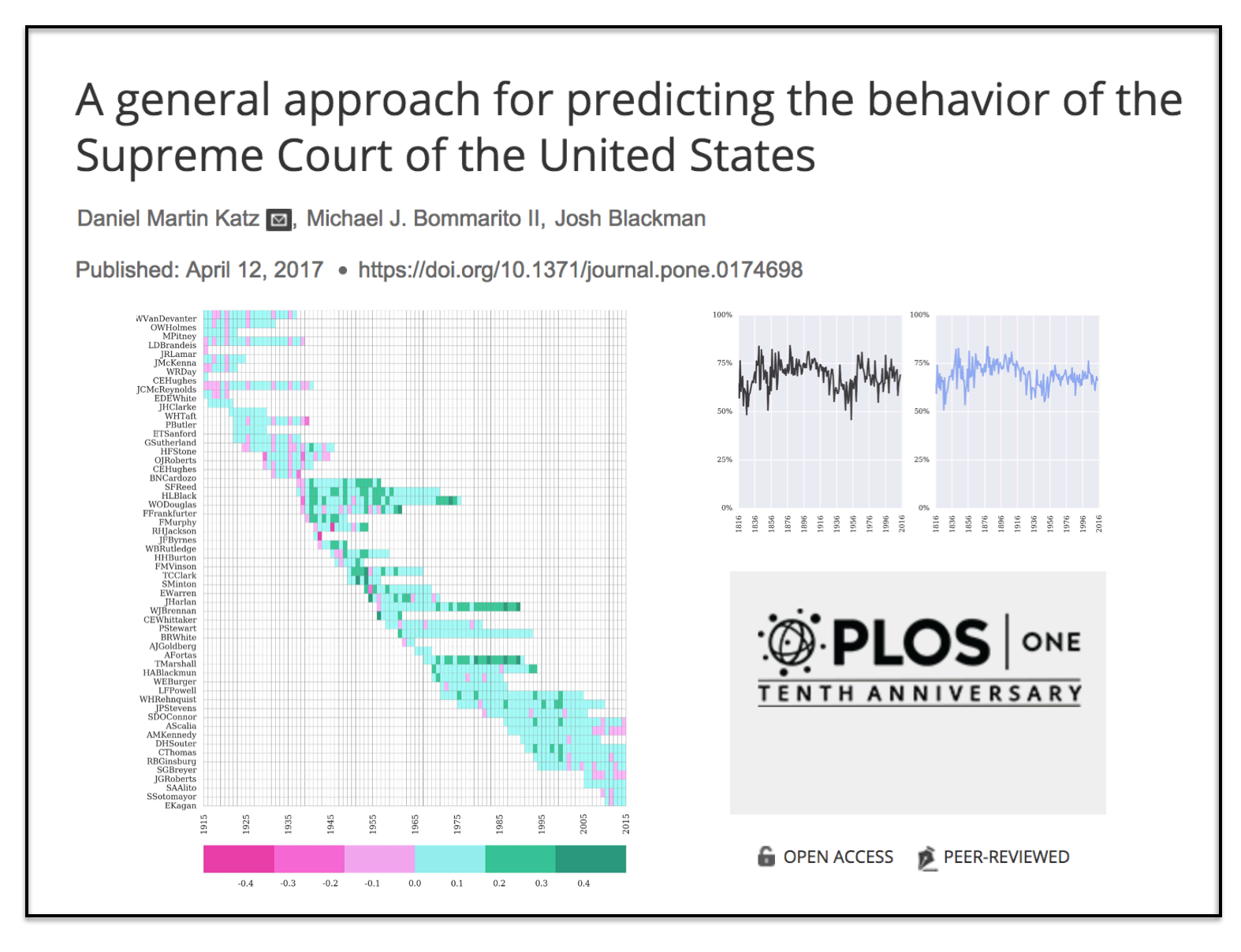
We have added three times the number years to the prediction model and now predict out-of-sample nearly two centuries of historical decisions (1816-2015). Then, we compare our results to three separate null models (including one which leverages in-sample information).
Here is the abstract: Building on developments in machine learning and prior work in the science of judicial prediction, we construct a model designed to predict the behavior of the Supreme Court of the United States in a generalized, out-of-sample context. Our model leverages the random forest method together with unique feature engineering to predict nearly two centuries of historical decisions (1816-2015). Using only data available prior to decision, our model outperforms null (baseline) models at both the justice and case level under both parametric and non-parametric tests. Over nearly two centuries, we achieve 70.2% accuracy at the case outcome level and 71.9% at the justice vote level. More recently, over the past century, we outperform an in-sample optimized null model by nearly 5%. Our performance is consistent with, and improves on the general level of prediction demonstrated by prior work; however, our model is distinctive because it can be applied out-of-sample to the entire past and future of the Court, not a single term. Our results represent an advance for the science of quantitative legal prediction and portend a range of other potential applications.

 Legal Technology and Innovation is global and I am proud to have the chance to teach in the LegalTech Masters Program at IE Law School in Madrid. This week, I will offer an online kickoff seminar on topics related to the program (sign up using the link) I look forward to meeting all of the students in the program next month in Madrid.
Legal Technology and Innovation is global and I am proud to have the chance to teach in the LegalTech Masters Program at IE Law School in Madrid. This week, I will offer an online kickoff seminar on topics related to the program (sign up using the link) I look forward to meeting all of the students in the program next month in Madrid.