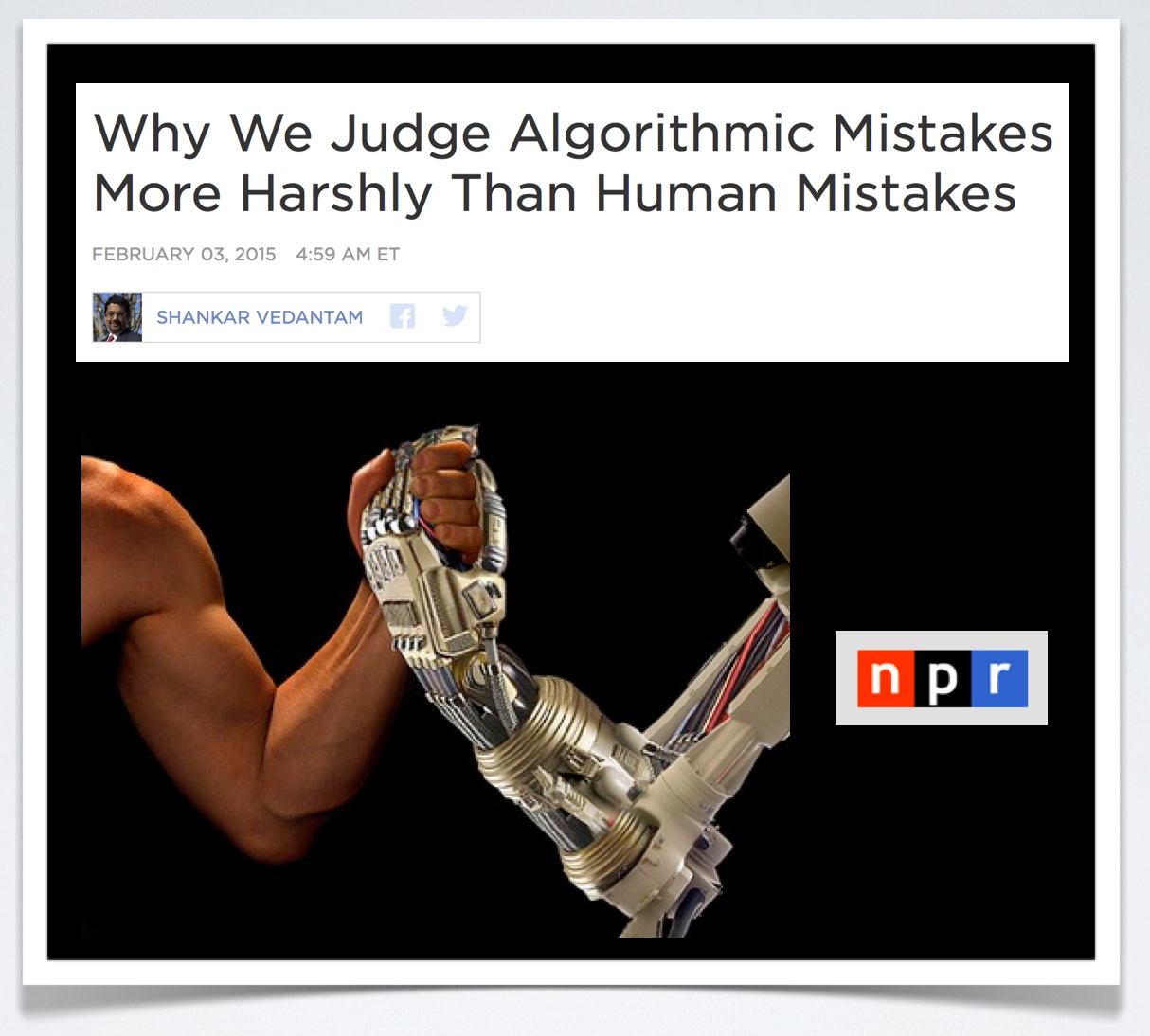
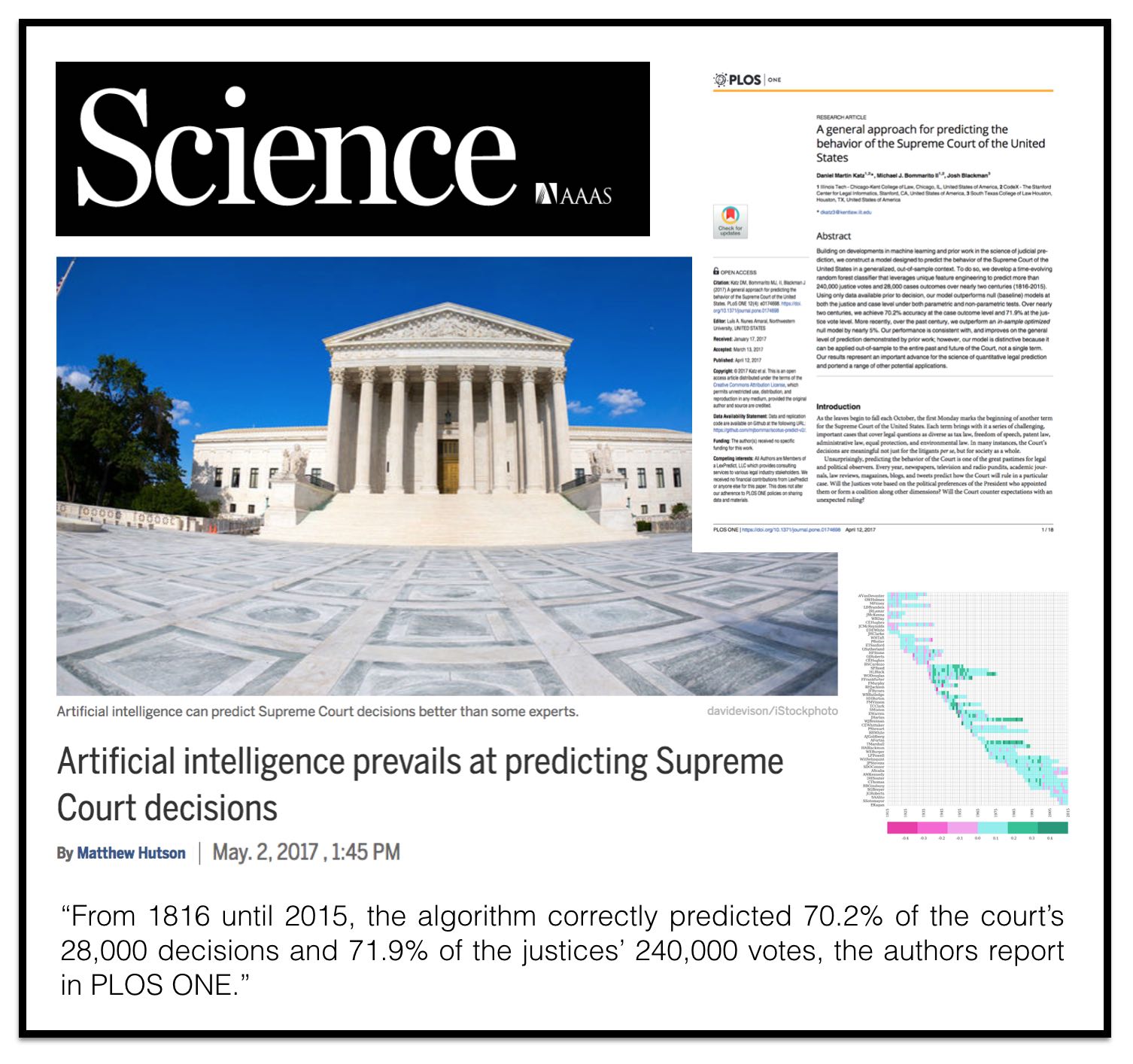
 Excited to see coverage of our Plos One #SCOTUS Prediction paper in Science Magazine (via Science News).
Excited to see coverage of our Plos One #SCOTUS Prediction paper in Science Magazine (via Science News).
Tag: algorithms
Artificial Intelligence and Law : A Six Part Primer – Professor Daniel Martin Katz (Updated Version 03.17.17)
An Updated Version of Artificial Intelligence and Law : A Six Part Primer

Announcing The Fin (Legal) Tech Conference – @ Illinois Tech – Chicago Kent College of Law November 4, 2016 (Sign up Today for a Free Ticket)

#FinTech embraces two major themes – characterizing / pricing increasingly exotic forms of risk and removing unnecessary frictions from friction laden financial processes. #Fin(Legal)Tech is the application of those ideas and technology to a wide range of law related spheres including litigation, transactional work and compliance.
The Law Lab at Illinois Tech – Chicago-Kent College of Law presents its first #Fin(Legal)Tech Conference on November 4, 2016. Continuing its legacy as an academic leader in legal technology and innovation, Chicago-Kent College of Law will bring together a wide-ranging and diverse group of industry leaders for a truly unique conference experience.
Attendees will be able to see rapid-fire and deeply engaging presentations on the following subjects:
Legal Risk, Legal Underwriting & Legal Insurance
Blockchain and Computable Contracts
MicroLaw / Long Tail Legal Markets
New Legal Information Infrastructure
Quantitative Legal Prediction & Legal Analytics
The Frictionless Delivery of Legal Services
Artificial Intelligence and Law
We will be soon announcing the speaker list but tickets are now open so if you want to attend please register for a FREE ticket today!




Law Firm COO & CFO Forum Pre-Conference Workshop on Big Data / Legal Analytics / Legal Informatics
 Yesterday I had the pleasure of participating in the Thomson Reuters Law Firm COO & CFO Forum Pre-Conference Workshop on Big Data. The half day workshop explored various way that law firms and outside counsel can use data to be better lawyers and run better businesses.
Yesterday I had the pleasure of participating in the Thomson Reuters Law Firm COO & CFO Forum Pre-Conference Workshop on Big Data. The half day workshop explored various way that law firms and outside counsel can use data to be better lawyers and run better businesses.
Here is the information for my panel (below) and the full program is located here.
Few business trends are as simultaneously revered, derided, appreciated or ignored as that of big data. Used (somewhat flippantly) to describe large, complex data sets that resist traditional data processing applications, big data represents both a beginning and end for many professional industries ill- prepared to harness big data’s myriad benefits and value. This opening conversation lays the framework for our program by addressing four key questions and concerns:
- What is big data?
- Why should we use it?
- Where does it lie within a business organization?
- How do we identify ROI and value in big data investment?
Moderator:
John Fernandez – US Chief Innovation Officer and Partner Dentons; Global Chair, NextLaw Labs
Panelists:
Justin Ergler – Director, Alternative Fee Intelligence and Analytics, GlaxoSmithKline
Daniel Martin Katz – Associate Professor of Law, Illinois Institute of Technology Chicago-Kent College of Law; Chief Strategy Officer, LexPredict
Michael S. Klastava – Vice President, Global Head of Legal Data & Analytics, American International Group, Inc.
Christopher Zorn – Liberal Arts Research Professor of Political Science and Sociology, The Pennsylvania State University; Principal, Quantitative Analysis, Lawyer Metrics

Amazon Introduces a Cloud Service for Machine Learning (via Venture Beat)
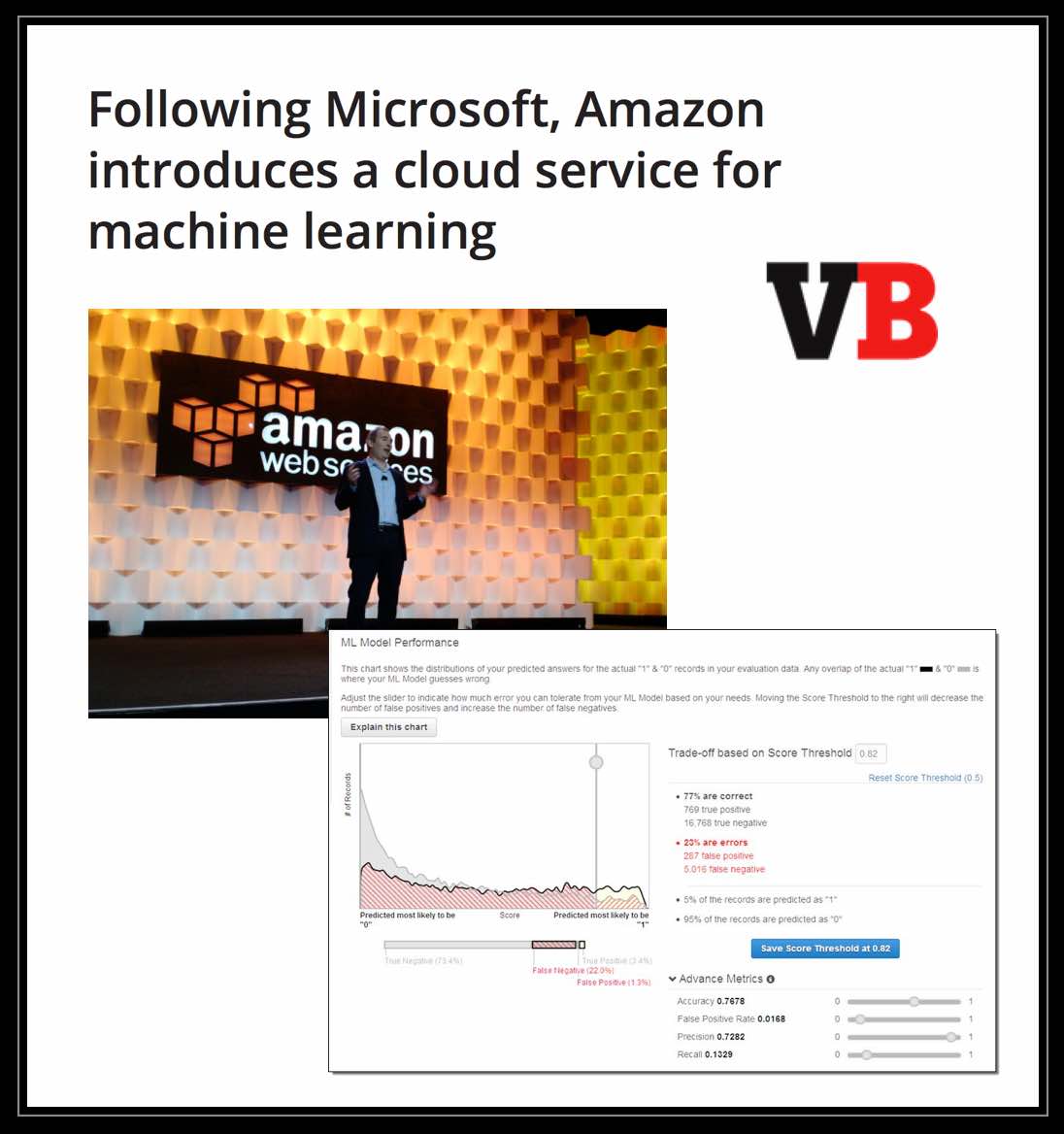
Suffice to say – this platform and competing platforms are going to collectively lower barriers to entry … and that is likely to have some implications (some good and some bad)
Even The Algorithms Think Obamacare’s Survival Is A Tossup (via 538.com)
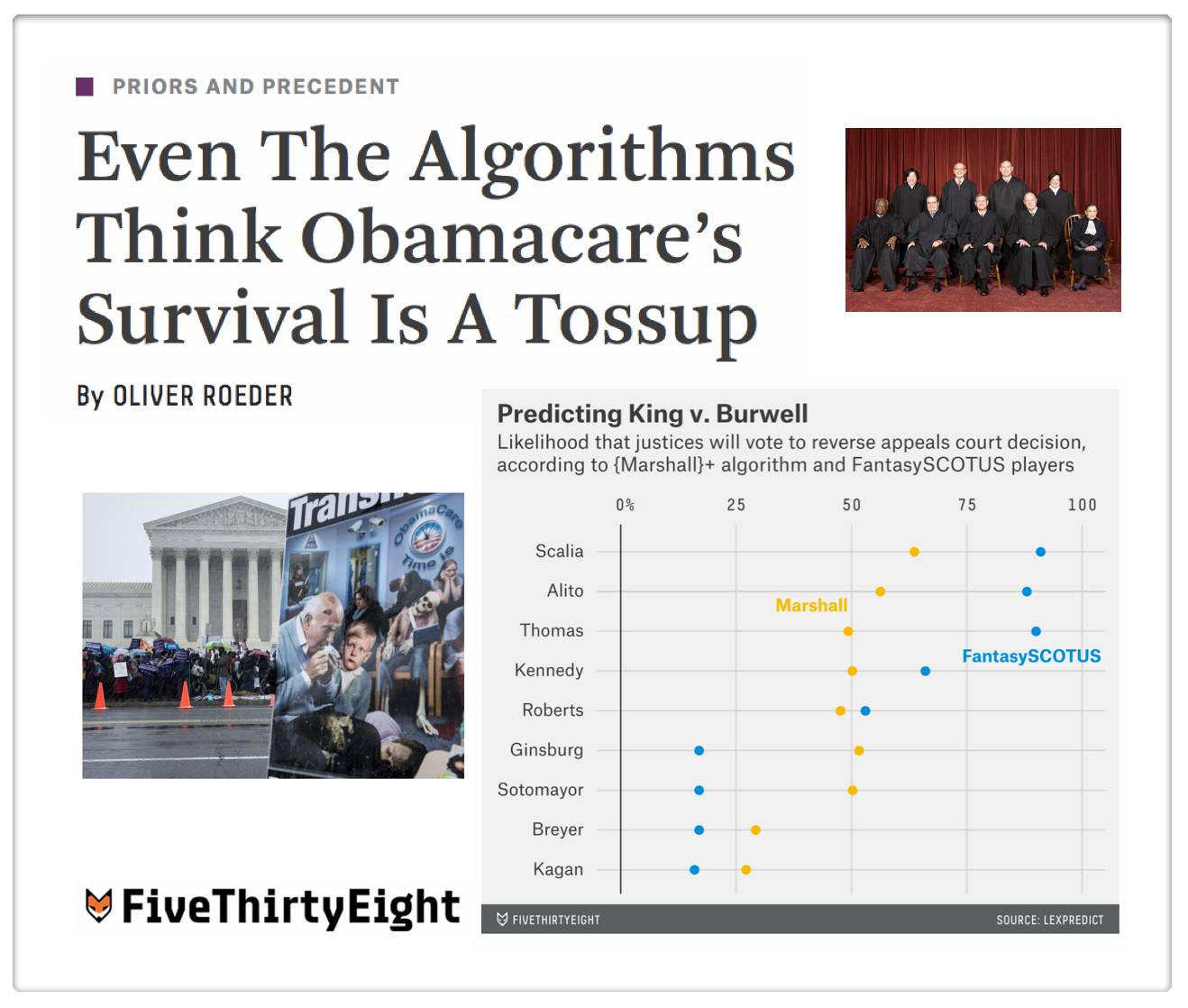
Readers will probably observe that {Marshall+} is still a work in progress (for example – my colleague noted {Marshall+} believes that Justice Ginsburg would appear to be slightly more likely to vote to overturn the ACA than Justice Thomas). While this probably will not prove to be correct in King v. Burwell, our method is rigorously backtested and designed to minimize errors across all predictions (not just in this specific case). This optimization question is tricky for the model and it will be the source of future model improvements. I have preached the whole mantra Humans + Machines > Humans or Machines and this problem is a good example. The problem with exclusive reliance upon human experts is they have cognitive biases, info processing issues, etc. The problem with models is that they generate errors that humans would not.
Anyway, the good thing about having a base model such as {Marshall+} is that we can begin to incorporate a range of additional information in an effort to create a {Marshall++} and beyond. And on that front there is more to come …