

Google Wave — A Promising Platform for Real-Time Collaboration

Also from the good folks at Google Scholar comes caselaw and patents together with metadata, page tags and a nice “how cited” feature. Here is the announcement from the GoogleBlog. Useful analysis available at Legal Informatics Blog, Just in Case and Internet for Lawyers. Enjoy!
Visualizing the Linkage Structure of the Law Blogosphere

So this is Version 1.0 of our series regarding the linkage structure of the Law Blogosphere. We are currently working on a Version 2.0 that will feature documentation and a larger set of law blogs. Check back soon for more!
“Sink Method” Poster for Conference on Empirical Legal Studies (CELS 2009 @ USC)

 As we mentioned in previous posts, Seadragon is a really cool product. Please note load times may vary depending upon your specific machine configuration as well as the strength of your internet connection. For those not familiar with how to operate it please see below. In our view, the Full Screen is best the way to go ….
As we mentioned in previous posts, Seadragon is a really cool product. Please note load times may vary depending upon your specific machine configuration as well as the strength of your internet connection. For those not familiar with how to operate it please see below. In our view, the Full Screen is best the way to go ….
Conference on Empirical Legal Studies @ USC Law School

Mike and I are in route to the 2009 Conference on Empirical Legal Studies (CELS) at USC Law School. This post is actually coming to you from 32,000 feet on GoGo Wireless. I still cannot get over the idea of being on wireless from a moving airplane. We live in extraordinary times!
Law Professoriate Poster for Conference on Empirical Legal Studies (CELS 2009 @ USC)

 As we mentioned in previous posts, Seadragon is a really cool product. Please note load times may vary depending upon your specific machine configuration as well as the strength of your internet connection. For those not familiar with how to operate it please see below. In our view, the Full Screen is best the way to go ….
As we mentioned in previous posts, Seadragon is a really cool product. Please note load times may vary depending upon your specific machine configuration as well as the strength of your internet connection. For those not familiar with how to operate it please see below. In our view, the Full Screen is best the way to go ….

Statistical Time Machines

So, I was a bit late on this … However, it is a really cool idea and thus I want to flag it for those who might have missed it. As covered over at SCOTUS Blog and ELS Blog, the November 12th Wall Street Journal features a story entitled “Statistical Time Travel Helps to Answer What-Ifs.” Of interest to legal scholars, Professors Andrew Martin and Kevin Quinn discuss a series of what-ifs including how today’s Supreme Court would have voted on Roe v. Wade … Check it out!
Programming Dynamic Models in Python-Part 3: Outbreak on a Network
In this post, we will continue building on the basic models we discussed in the first and second tutorials. If you haven’t had a chance to take a look at them yet, definitely go back and at least skim them, since the ideas and code there form the backbone of what we’ll be doing here.
In this tutorial, we will build a model that can simulate outbreaks of disease on a small-world network (although the code can support arbitrary networks). This tutorial represents a shift away from both:
a) the mass-action mixing of the first two and and
b) the assumption of social homogeneity across individuals that allowed us to take some shortcuts to simplify model code and speed execution. Put another way, we’re moving more in the direction of individual-based modeling.
When we’re done, your model should be producing plots that look like this:

Red nodes are individuals who have been infected before the end of the run, blue nodes are never-infected individuals and green ones are the index cases who are infectious at the beginning of the run.
And your model will be putting out interesting and unpredictable results such as these:

In order to do this one, though, you’re going to need to download and install have igraph for Python on your system.
Individual-Based Networks
It is important to make the subtle distinction between individual and agent based models very clear here. Although the terms are often used interchangeably, referring to our nodes, who have no agency, per se, but are instead fairly static receivers and diffusers of infection, as agents, seems like overreaching. Were they to exhibit some kind of adaptive behavior, i.e., avoiding infectious agents or removing themselves from the population during the infective period, they then become more agent-like.
This is not to under- or over-emphasize the importance or utility of either approach, but just to keep the distinction in mind to avoid the “when all you have is a hammer, everything looks like a nail” problem.
In short, adaptive agents are great, but they’re overkill if you don’t need them for your specific problem.
Small World Networks
The guiding idea behind small-world networks is that they capture some of the structure seen in more realistic contact networks: most contacts are regular in the sense that they are fairly predicable, but there are some contacts that span tightly clustered social groups and bring them together.
In the basic small-world model, an individual is connected to some (small, typically <=8) number of his or her immediate neighbors. Some fraction of these network connections are then randomly re-wired, so that some individuals who were previously distant in network terms – i.e., connected by a large number of jumps – are now adjacent to each other. This also has the effect of shortening the distance between their neighbors and individuals on the other side of the graph. Another way of putting this is that we have shortened the average path length and increased the average reachability of all nodes.
These random connections are sometimes referred to as “weak ties”, as there are fewer of these ties that bridge clusters than there are within clusters. When these networks are considered from a sociological perspective, we often expect to find that the relationship represented by a weak tie is one in which the actors on either end have less in common with each other than they do with their ‘closer’ network neighbors.
Random networks also have the property of having short average path lengths, but they lack the clustering that gives the small-world model that pleasant smell of quasi-realism that makes them an interesting but largely tractable, testing ground for theories about the impact of social structure on dynamic processes.
Installation and Implementation Issues
If you have all the pre-requisites installed on your system, you should be able to just copy and paste this code into a new file and run it with your friendly, local Python interpreter. When you run the model, you should first see a plot of the network, and when you close this, you should see a plot of the number of infections as a function of time shortly thereafter.
Aside from the addition of the network, the major conceptual difference is that the model operates on discrete individuals instead of a homogeneous population of agents. In this case, the only heterogeneity is in the number and identity of each individual’s contacts, but there’s no reason we can’t (and many do) incorporate more heterogeneity (biological, etc.) into a very similar model framework.
With Python, this change in orientation to homogeneous nodes to discrete individuals seems almost trivial, but in other languages it can be somewhat painful. For instance, in C/++, a similar implementation would involve defining a struct with fields for recovery time and individual ID, and defining a custom comparison operator for these structs. Although this is admittedly not a super-high bar to pass, it adds enough complexity that it can scare off novices and frustrate more experienced modelers.
Perhaps more importantly, it often has the effect of convincing programmers that a more heavily object-oriented approach is the way to go, so that each individual is a discrete object. When our individuals are as inert as they are in this model, this ends up being a waste of resources and makes for significantly more cluttered code. The end result can often be a model written in a language that is ostensibly faster than Python, such as C++ or Java, that runs slower than a saner (and more readable) Python implementation.
For those of you who are playing along at home, here are some things to think about and try with this model:
- Change the kind of network topology the model uses (you can find all of the different networks available in igraph here).
- Incorporate another level of agent heterogeneity: Allow agents to have differing levels of infectivity (Easier); Give agents different recovery time distributions (Harder, but not super difficult).
- Make two network models – you can think of them as separate towns – and allow them to weakly influence each other’s outbreaks. (Try to use the object-oriented framework here with minimal changes to the basic model.)
That’s it for tutorial #3, (other than reviewing the comment code which is below) but definitely check back for more on network models!
In future posts, we’ll be thinking about more dynamic networks (i.e., ones where the links can change over time), agents with a little more agency, and tools for generating dynamic visualizations (i.e., movies!) of stochastic processes on networks.
That really covers the bulk of the major conceptual issues. Now let’s work through the implementation.
Click Below to Review the Implementation and Commented Code!
Continue reading “Programming Dynamic Models in Python-Part 3: Outbreak on a Network”
New Paper: Properties of the United States Code Citation Network
We have been working on a larger paper applying many concepts from structural analysis and complexity science to the study of bodies of statutory law such as the United States Code. To preview the broader paper, we’ve published to SSRN and arXiv a shorter, more technical analysis of the properties of the United States Code’s network of citations.
Click here to Download the Paper!
Abstract: The United States Code is a body of documents that collectively comprises the statutory law of the United States. In this short paper, we investigate the properties of the network of citations contained within the Code, most notably its degree distribution. Acknowledging the text contained within each of the Code’s section nodes, we adjust our interpretation of the nodes to control for section length. Though we find a number of interesting properties in these degree distributions, the power law distribution is not an appropriate model for this system.

- Citation In-Degree
Katz & Bommarito in the New York Times Discussing H.R. 3962

If you click through on the link above you will be directed to the New York Times Rx Blog. The full version of the article appears online while a shorter version appeared in today’s print edition. For those viewing the print edition, the story is located on page A20. This website is mentioned in both versions of the story!
Visualizing the Structure of H.R. 3962 — The Health Care Bill

In addition to the facts we have presented on HR 3962, we wanted to offer a visualization for the structure of the Bill. Like many other bills, HR 3962, is divided into Divisions, Titles, Subtitles, Parts, Subparts, Sections, Subsections, Clauses, and Subclauses. These hierarchical splits represent the drafters’ conception of its organization, and thus the relative size of these categories may provide an indication of both the importance of each section of the Bill as well as the overall size of the document. By clicking through the image below, you can navigate a zoomable representation of the structure of HR 3962 using Microsoft’s Seadragon zoom interface. Many of the Divisions, Titles, Subtitles, Parts, and Subparts of the Bill are labeled. The balance are not labeled because they fell on an angle on the radial layout which rendered them impossible to read.
The graph is laid out in a radial manner with the center node labeled “H.R. 3962.” Legislation, the broader United States Code as well as many other classes of information are organized as hierarchical documents. H.R. 3962 is no different. For those less familiar with this type of documents, we thought it useful to provide a tutorial regarding (1) how to use this zoomable visualization (2) the correspondence between the visual and the Library of Congress version of H.R. 3962
How Do I Open/Navigate the Visualization?
(1) Open the Library of Congress version of H.R. 3962 in another browser window.
(2) Open the visualization by clicking on the large image above.
(3) Clicking on the image above will take you to the Seadragon platform. (Note: Load times will vary from machine to machine… so please be patient.)
(4) Seadragon allows for zoomable visualizations and for full screen viewing. Full screen is really the best way to go. If you run your mouse over the black box where the visual is located you will see four buttons in the southeast corner. The “full screen” button is the last one on the right. Click the button and you will be taken to full screen viewing!
(5) Click to zoom in and out, hold the mouse down and drag the entire visual, etc. Now, you are ready to traverse the graph using this visualization as your very own “H.R. 3962 Magic Decoder Wheel.”
How Do I Understand the Visualization?
To introduce the substance of the visualization, we have color coded two separate examples right into the visualization.
Example 1: Bills such as HR 3962 often feature a “short title” provision at the very begining of the legislation. For example, if you download the PDF copy of the bill, you can see the short title at the bottom of page 1 of the bill. You can also see this in the Library of Congress version of H.R. 3962.
SECTION 1. SHORT TITLE; TABLE OF DIVISIONS, TITLES, AND SUBTITLES.
(a) Short Title- This Act may be cited as the `Affordable Health Care for America Act’.
Zoom in close to start in the center where the large node labeled “HR 3962.” Notice the blue colorized path features the blue labels 1. and terminates with the label (a). The labels in the graph are the labels in the text above. While this is a simple example, the precise logic defines the entire graph.
Example 2: This is a bit more difficult as it requires the traversal of several provisions in order to reach a terminal node. In this case, the terminal node read as follows … “SEC. 401. INDIVIDUAL RESPONSIBILITY.For an individual’s responsibility to obtain acceptable coverage, see section 59B of the Internal Revenue Code of 1986 (as added by section 501 of this Act).”
DIVISION A–AFFORDABLE HEALTH CARE CHOICES
TITLE IV–SHARED RESPONSIBILITY
Subtitle A–Individual Responsibility
SEC. 401. INDIVIDUAL RESPONSIBILITY.
Again, zoom in close to start in the center--where the large node labeled “HR 3962.” Notice the blue colorized path features the blue labels A and terminates with the label 401. In between the start and finish, there are stops at IV and A, respectfully. Just as before, the labels in the graph are the labels in the text above. The end user can follow the precise journey but without the visual by using the Library of Congress version of H.R. 3962.
Facts About the Length of H.R. 3962, the Affordable Health Care for America Act (AHCAA)

In light of last night’s vote on H.R. 3962, the Affordable Health Care for America Act, we decided to calculate a few numbers on the current bill. Based on the Library of Congress’s XML representation of the bill (which can be obtained here), we have calculated a number of linguistic and citation properties of the Bill. The House of Representative approved HR 3962 by a 220-215 margin. The New York Times features a useful analysis of the vote including a breakout by party and region here.
On the Sunday morning talk shows as well as in other outlets, there has been significant discussion regarding the size of H.R. 3962. Specifically, many critics have decried the length of the bill citing its 1990 pages. The bill is indeed 1990 pages as you can see if you choose to download a PDF copy of the bill.
The purpose of this post is to provide a perspective regarding the length of H.R. 3962. Those versed in the typesetting practices of the United States Congress know that the printed version of a bill contains a significant amount of whitespace including non-trivial space between lines, large headers and margins, an embedded table of contents, and large font. For example, consider page 12 of the printed version of H.R. 3962. This page contains fewer than 150 substantive words.
We believe a simple page count vastly overstates the actual length of bill. Rather than use page counts, we counted the number of words contained in the bill and compared these counts to the number of words in the existing United States Code. In addition, we consider the number of text blocks in the bill– where a text block is a unit of text under a section, subsection, clause, or sub-clause.
Basic Information about the Length of H.R. 3962
Number of words in H.R. 3962 impacting substantive law:
- 234,812 words (w/ generous calculation)
Number of total words in H.R. 3962: 363,086 words (w/ titles, tables of contents …)
Number of text blocks: 7,961
Average number of words per text block: 24.18
Average words per section: 267.03
Is this a Large or Small Number? Comparison to Harry Potter
Number of substantive words in H.R. 3962: 234,812 words
Harry Potter and the Order of the Phoenix – 257,000 words
Harry Potter and the Goblet of Fire – 190,000 words
Harry Potter and the Deathly Hallows – 198,000 words
Is this a Large or Small Number? Comparison to Other Legislation
Number of substantive words in Energy Bill of 2007: 157,835 words
Number of substantive words in Defense Authorization Act for 2010: 119,960 Words
H.R. 3962 is roughly 2x the Size of Medicare Rx Bill of 2003 (Given there is no public XML version of the bill, the Exact “Substantive Words” Number is not available)
Is this a Large or Small Number? Comparison to the Full U.S. Code
Size of the United States Code: 42+ Million Words
Relative Size of H.R. 3962: H.R. 3962 is roughly 1/2 of one percent of the size of the United States Code
Longest Sections in H.R. 3962
- Sec 341. Availability Through Health Insurance Exchange
- Sec 1222. Demonstration to promote access for Medicare beneficiaries with limited English proficiency by providing reimbursement for culturally and linguistically appropriate services.
- Sec 1160: Implementation, and Congressional review, of proposal to revise Medicare payments to promote high value health care
- Sec 305: Funding for the construction, expansion, and modernization of small ambulatory care facilities
- Sec 1417: Nationwide program for national and State background checks on direct patient access employees of long-term care facilities and providers
Modifications of the Existing U.S. Code By H.R. 3962
Number of Strikeouts: 332
Number of Inserts: 390
Number of Re-designations: 65
Acts Most Cited By H.R. 3962
Social Security Act: 622 times
Public Health Service Act: 134 times
Affordable Health Care for America Act: 60 times
Indian Health Care Improvement Act: 56 times
Indian Self-Determination and Education Assistance Act: 45 times
Employee Retirement Income Security Act: 39 times
Medicare Prescription Drug, Improvement, and Modernization Act: 11 times
American Recovery and Reinvestment Act: 7
Sections of the U.S. Code Cited (Properly) Most By H.R. 3962
25 U.S.C. §450. Congressional statement of findings: 38
25 U.S.C. §13. Expenditure of appropriations by Bureau: 13
42 U.S.C. §1396a(a). State plans for medical assistance: 10
42 U.S.C. §1396d(a). Definitions: 7
42 U.S.C. §2004a. Sanitation facilities: 7
Hustle and Flow: A Social Network Analysis of the American Federal Judiciary [Repost from 3/25]

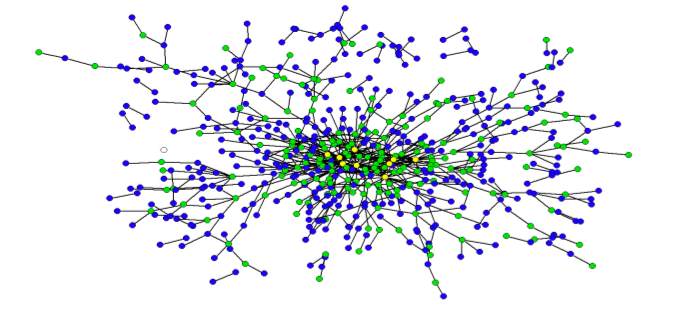
Together with Derek Stafford from the University of Michigan Department of Political Science, Hustle and Flow: A Social Network Analysis of the American Federal Judiciary represents our initial foray into Computational Legal Studies. The full paper contains a number of interesting visualizations where we draw various federal judges together on the basis of their shared law clerks (1995-2004). The screen print above is a zoom very center of the center of the network. Yellow Nodes represent Supreme Court Justices, Green Nodes represent Circuit Court Justices, Blue Nodes represent District Court Justices.
There exist many high quality formal models of judicial decision making including those considering decisions rendered by judges in judicial hierarchy, whistle blowing, etc. One component which might meaningfully contribute to the extent literature is the rigorous consideration of the social and professional relationships between jurists and the impacts (if any) these relationships impose upon outcomes. Indeed, from a modeling standpoint, we believe the “judicial game” is a game on a graph–one where an individual strategic jurist must take stock of time evolving social topology upon which he or she is operating. Even among judges of equal institutional rank, we observe jurists with widely variant levels social authority (specifically social authority follows a power law distribution).
So what does all of this mean? Take whistle blowing — the power law distribution implies that if the average judge has a whistle, the “super-judges” we identify within the paper could be said to have an air horn. With the goal of enriching positive political theory / formal modeling of the courts, we believe the development of a positive theory of judicial social structure can enrich our understanding of the dynamics of prestige and influence. In addition, we believe, at least in part, “judicial peer effects” can help legal doctrine socially spread across the network. In that vein, here is a view of our operationalization of the social landscape … a wide shot of the broader network visualized using the Kamada-Kawai visualization algorithm:
Here is the current abstract for the paper: Scholars have long asserted that social structure is an important feature of a variety of societal institutions. As part of a larger effort to develop a fully integrated model of judicial decision making, we argue that social structure-operationalized as the professional and social connections between judicial actors-partially directs outcomes in the hierarchical federal judiciary. Since different social structures impose dissimilar consequences upon outputs, the precursor to evaluating the doctrinal consequences that a given social structure imposes is a descriptive effort to characterize its properties. Given the difficulty associated with obtaining appropriate data for federal judges, it is necessary to rely upon a proxy measure to paint a picture of the social landscape. In the aggregate, we believe the flow of law clerks reflects a reasonable proxy for social and professional linkages between jurists. Having collected available information for all federal judicial law clerks employed by an Article III judge during the “natural” Rehnquist Court (1995-2004), we use these roughly 19,000 clerk events to craft a series of network based visualizations. Using network analysis, our visualizations and subsequent analytics provide insight into the path of peer effects in the federal judiciary. For example, we find the distribution of “degrees” is highly skewed implying the social structure is dictated by a small number of socially prominent actors. Using a variety of centrality measures, we identify these socially prominent jurists. Next, we draw from the extant complexity literature and offer a possible generative process responsible for producing such inequality in social authority. While the complete adjudication of a generative process is beyond the scope of this article, our results contribute to a growing literature documenting the highly-skewed distribution of authority across the common law and its constitutive institutions.
Can You Hear Me Now? AT&T Sues Verizon over Visualization Coverage Map

A post over at Information Aesthetics highlights a recent dispute between AT&T and Verizon over the visualization shown above. To see the full ad click here and to read more click here!