

Author: clsadmin
The rate at which US Companies cite regulations as an obstacle has quadrupled over the last 20 years (via Quartz)
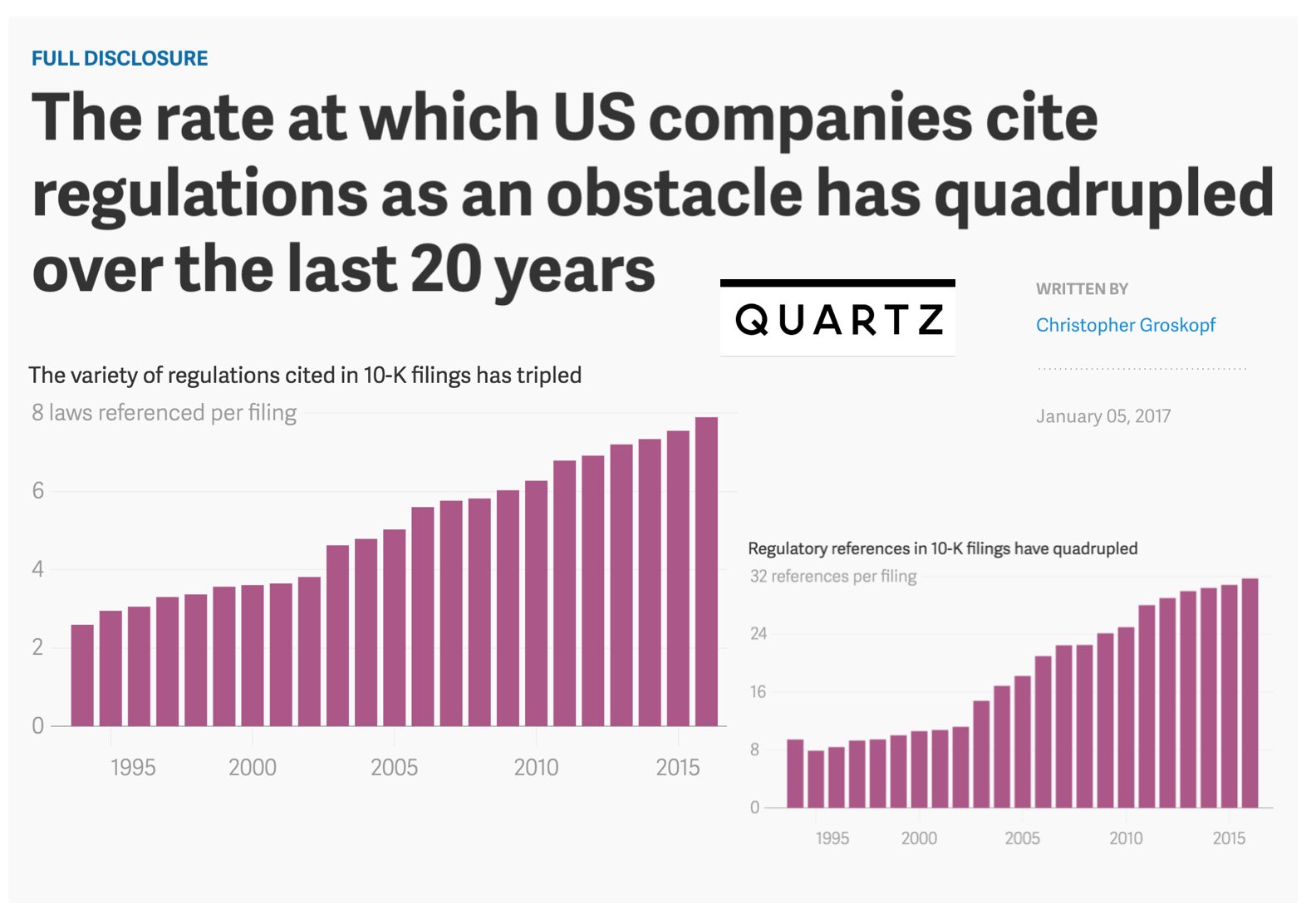 “Michael Bommarito II and Daniel Martin Katz, legal scholars at the Illinois Institute of Technology, have tried to measure the growth of regulation by analyzing more than 160,000 corporate annual reports, or 10-K filings, at the US Securities and Exchange Commission. In a pre-print paper released Dec. 29, the authors find that the average number of regulatory references in any one filing increased from fewer than eight in 1995 to almost 32 in 2016. The average number of different laws cited in each filing more than doubled over the same period.”
“Michael Bommarito II and Daniel Martin Katz, legal scholars at the Illinois Institute of Technology, have tried to measure the growth of regulation by analyzing more than 160,000 corporate annual reports, or 10-K filings, at the US Securities and Exchange Commission. In a pre-print paper released Dec. 29, the authors find that the average number of regulatory references in any one filing increased from fewer than eight in 1995 to almost 32 in 2016. The average number of different laws cited in each filing more than doubled over the same period.”
Measuring the Temperature and Diversity of the U.S. Regulatory Ecosystem (Preprint on arXiv + SSRN)
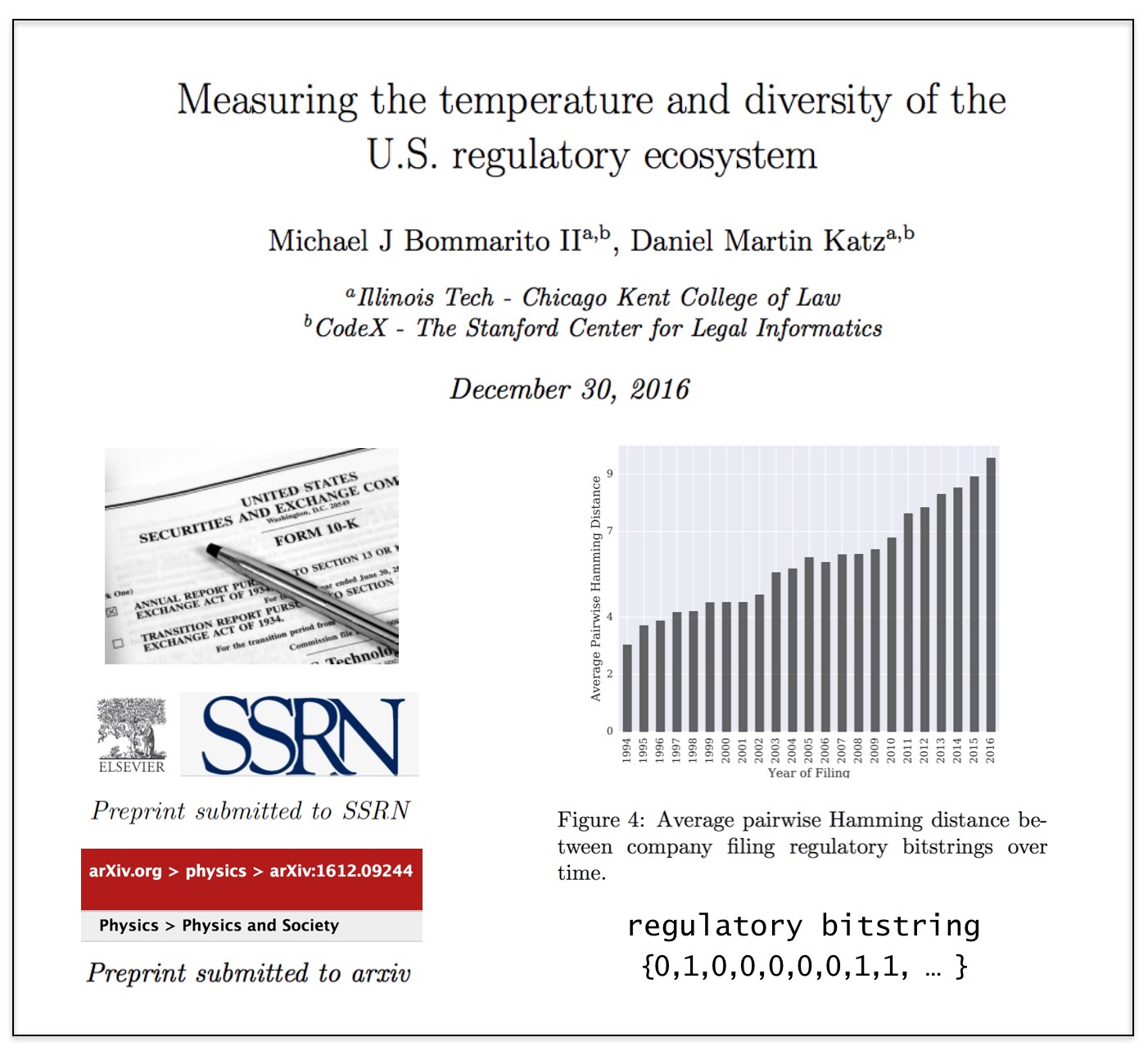
From the Abstract: Over the last 23 years, the U.S. Securities and Exchange Commission has required over 34,000 companies to file over 165,000 annual reports. These reports, the so-called “Form 10-Ks,” contain a characterization of a company’s financial performance and its risks, including the regulatory environment in which a company operates. In this paper, we analyze over 4.5 million references to U.S. Federal Acts and Agencies contained within these reports to build a mean-field measurement of temperature and diversity in this regulatory ecosystem. While individuals across the political, economic, and academic world frequently refer to trends in this regulatory ecosystem, there has been far less attention paid to supporting such claims with large-scale, longitudinal data. In this paper, we document an increase in the regulatory energy per filing, i.e., a warming “temperature.” We also find that the diversity of the regulatory ecosystem has been increasing over the past two decades, as measured by the dimensionality of the regulatory space and distance between the “regulatory bitstrings” of companies. This measurement framework and its ongoing application contribute an important step towards improving academic and policy discussions around legal complexity and the regulation of large-scale human techno-social systems.
Available in PrePrint on SSRN and on the Physics arXiv.


A General Approach for Predicting the Behavior of the Supreme Court of the United States (Paper Version 2.01) (Katz, Bommarito & Blackman)

Long time coming for us but here is Version 2.01 of our #SCOTUS Paper …
We have added three times the number years to the prediction model and now predict out-of-sample nearly two centuries of historical decisions (1816-2015). Then, we compare our results to three separate null models (including one which leverages in-sample information).
Here is the abstract: Building on developments in machine learning and prior work in the science of judicial prediction, we construct a model designed to predict the behavior of the Supreme Court of the United States in a generalized, out-of-sample context. Our model leverages the random forest method together with unique feature engineering to predict nearly two centuries of historical decisions (1816-2015). Using only data available prior to decision, our model outperforms null (baseline) models at both the justice and case level under both parametric and non-parametric tests. Over nearly two centuries, we achieve 70.2% accuracy at the case outcome level and 71.9% at the justice vote level. More recently, over the past century, we outperform an in-sample optimized null model by nearly 5%. Our performance is consistent with, and improves on the general level of prediction demonstrated by prior work; however, our model is distinctive because it can be applied out-of-sample to the entire past and future of the Court, not a single term. Our results represent an advance for the science of quantitative legal prediction and portend a range of other potential applications.
The Future of Law + Legal Technology @ Aviva Stadium – Dublin, Ireland

Enjoyed delivering the Keynote Address at the #FutureOfLaw Conference here at Aviva Stadium in Dublin, Ireland.
Thanks to Leman Solicitors and all of the sponsors for this wonderful event!
Economists are Prone to Fads, and the Latest is Machine Learning (via The Economist)
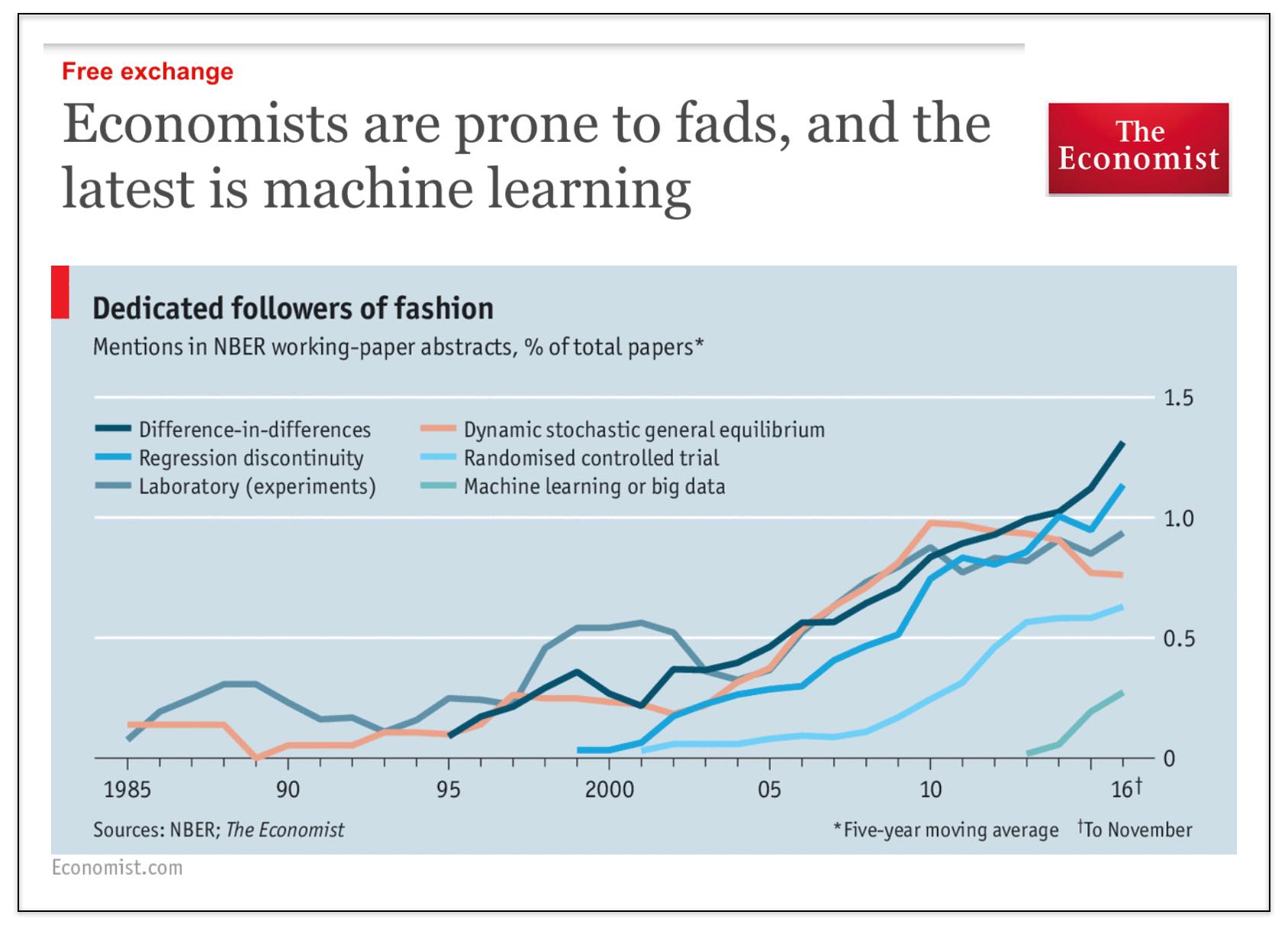
We started this blog (7 years ago) because we thought that there was insufficient attention to computational methods in law (NLP, ML, NetSci, etc.) Over the years this blog has evolved to become mostly a blog about the business of law (and business more generally) and the world is being impacted by automation, artificial intelligence and more broadly by information technology.
However, returning to our roots here — it is pretty interesting to see that the Economist has identified that #MachineLearning is finally coming to economics (pol sci + law as well).
Social science generally (and law as a late follower of developments in social science) it is still obsessed with causal inference (i.e. diff in diff, regression discontinuity, etc.). This is perfectly reasonable as it pertains to questions of evaluating certain aspects of public policy, etc.
However, there are many other problems in the universe that can be evaluated using tools from computer science, machine learning, etc. (and for which the tools of causal inference are not particularly useful).
In terms of the set of econ papers using ML, my bet is that a significant fraction of those papers are actually from finance (where people are more interested in actually predicting stuff).
In my 2013 article in Emory Law Journal called Quantitative Legal Prediction – I outline this distinction between causal inference and prediction and identify just a small set of the potential uses of predictive analytics in law. In some ways, my paper is already somewhat dated as the set of use cases has only grown. That said, the core points outlined therein remains fully intact …

What A Difference 2 Percentage Points Makes and Nate Silver vs Huff Po Revisited

There is likely to be lots of recriminations in the pollster space but I think one thing is pretty clear — there was not enough uncertainty in the various methods of poll aggregation.
I will highlight the Huffington Post (Huff Po) model because they had such hubris about their approach. Indeed, Ryan Grimm wrote an attempted attack piece on the 538 model which stated “Silver is making a mockery of the very forecasting industry that he popularized.” (Turns out his organization was the one making the mockery)
Nate Silver responded quite correctly that this Huff Po article is “so fucking idiotic and irresponsible.” And it was indeed.
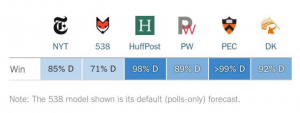
Even after the election Huff Po is out there trying to characterize it as a black swan event. It is *not* a black swan event. Far from it … and among the major poll aggregators Five Thirty Eight was the closest because they had more uncertainty (which turns out was quite appropriate). Specifically, the uncertainty that cascaded through 538’s model was truthful … and just because it resulted in big bounds didn’t mean that it was a bad model, because the reality is that the system in question was intrinsically unpredictable / stochastic.
From the 538 article cited above “Our finding, consistently, was that it was not very robust because of the challenges Clinton faced in the Electoral College, especially in the Midwest, and therefore our model gave a much better chance to Trump than other forecasts did.”
Take a look again at the justification (explanation) from the Huffington Post: “The model structure wasn’t the problem. The problem was that the data going into the model turned out to be wrong in several key places.”
Actually the model structure was the problem in so much as any aggregation model should try to characterize (in many ways) the level of uncertainty associated with a particular set of information that it is leveraging.
Poll aggregation (or any sort of crowd sourcing exercise) is susceptible to systemic bias. Without sufficient diversity of inputs, boosting and related methodological approaches are *not* able to remove systematic bias. However, one can build a meta-meta model whereby one attempts to address the systemic bias after undertaking the pure aggregation exercise.
So what is the chance that a set of polls have systematic error such that the true preferences of a group of voters is not reflected? Could their be a Bradley type effect? How much uncertainty should that possibility impose on our predictions? These were the questions that needed better evaluation pre-election.
It is worth noting that folks were aware of the issue in theory but most of them discounted it to nearly zero. Remember this piece in Vanity Fair which purported to debunk the Myth of the Secret Trump Voter (which is the exact systematic bias that appeared to undermine most polls)?
Let us look back to the dynamics of this election. There was really no social stigma associated with voting for Hillary Clinton (in most social circles) and quite a bit (at least in certain social circles) with voting for Trump.
So while this is a set back for political science, I am hoping what comes from all of this is better science in this area (not a return to data free speculation (aka pure punditry)).
P.S. Here is one more gem from the pre-election coverage – Election Data Hero Isn’t Nate Silver. It’s Sam Wang (the Princeton Professor had HRC at more than a 99% chance of winning). Turns out this was probably the worst performing model because it has basically zero model meta-uncertainty.
Daniel Katz Launches Fin [Legal] Tech (via Above The Law) #FinLegalTech
For more information on Fin (Legal) Tech — see here!