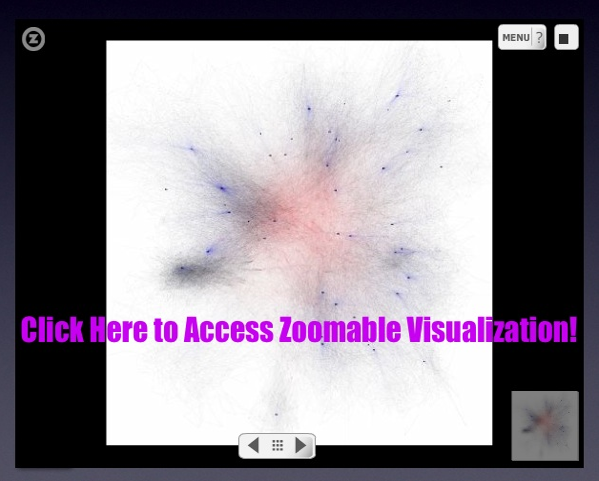
Based on the Farouk1986 Gawaher data posted earlier this week, we have analyzed the communication network of the alleged Christmas Day Bomber, Umar Farouk Abdulmutallab.
Using the handle “Farouk1986,” Abdulmutallab was a regular participant on the Islamic forum Gawaher.com. Several years prior to the Christmas Day incident, the alleged Christmas Day Bomber took part in a significant number of communications. Of course, these communications can be analyzed in a number of ways. For example, over at Zero Intelligence Agents, Drew Conway has already done some useful initial analysis. We sought to contribute our analysis of the time-evolving communication network contained within these posts. While more extensive documentation is available below, in reviewing the dynamic network visualization, consider the following observations:
Click on the Full Screen Button! (4 Arrow Symbol in the Vimeo Bottom Banner)
#1) “Farouk1986” Entered an Existing Network Which Appeared to Increase the Salience of Religion in His Life
Although individuals in society may feel isolated or appear to be loners, the internet offers like minded, potentially meaningful networks of people with whom to connect. These internet is full of communities of individuals who interests are wide ranging—including topics such as Blizzard’s World of Warcraft, sports, culinary interests or religion. With whatever prior beliefs he held, “Farouk1986” entered this subset of the broader Islamic online community in late 2004. While it is not possible for us to make definitive conclusions, it appears that the community with whom he connected increased the salience of religion in his life. In other words, through the internet “Farouk1986” experienced a reinforcing feedback and this likely primed him for further radicalization.
#2) The Network of “Farouk1986” Grows Increasingly Stable Once Established
“Farouk1986” increasingly communicated with the same set of individuals over the window in question. Thus, while communication continued to flow through the network … the network, once established, remains fairly stable. In other words, instead of being exposed to diverse sets of individuals, “Farouk1986” continued to communicate with the same individuals. In turn, those direct contacts also continued to communicate with the same individuals.
#3) Additional Streams of Data Would Enhance Analysis
The forum posts which serve as the data for this analysis are only a subset of the communication network experienced by Umar Farouk Abdulmutallab. Additional streams of relevant data would include phone records, emails, participation in other forums, etc. would likely enhance the granularity of our analysis. If you have access to such data and are legally authorized to share it-please feel free to contact us.
Background
For those not already familar with the case, Umar Farouk Abdulmutallab is charged with willful attempt to destroy an aircraft in connection with the December 25, 2009 Delta Flight 253 from Amsterdam to Detroit. Like many, we wondered precisely what path led the son of a wealthy banker to find himself as a would be suicide bomber. While these communications represent only a small portion of the broader picture, a number of illuminating analyses can still be conducted using this available information.
Using the handle “Farouk1986,” Umar Farouk Abdulmutallab was a regular participant on the popular Islamic forum Gawaher.com. Thus, as a small contribution to the broader analysis of the Christmas Day Incident, we have generated a basic visualization and analysis of the time-evolving structure of the Farouk1986 online communication network.
Filtration of the Gawaher.com Forum
As a major Islamic forum, Gawaher.com features a tremendous number of participants and a wide range of post on topics including Islamic culture, religion, international football, politics, etc.
Given our specific interest in the online behavior of Umar Farouk Abdulmutallab, we were most interested in analyzing the direct and indirect communication network associated with the handle “Farouk1986” (aka Umar Farouk Abdulmutallab). Therefore, it was necessary to filter the broader universe of communication on Gawaher.com to the relevant subset.
A portion of this information is contained in publically available NEFA dataset. While useful, we determined that this dataset alone did not include the information necessary for us to construct the Farouk1986 secondary/indirect communications network. In order to obtain a better understanding of this communication network, we retrieved every “topic” in which Farouk1986 participated at least once. Each “topic” is comprised of one or more “posts” from one or more users. Each “post” may be in response to another user’s “post.” The NEFA data contains only posts made by Farouk1986 – our data contains the entire context within which his posts existed.
Building the Time-Evolving Network of Direct and Indirect Communications
Building from this underlying data, we sought to both visualize and analyze the time evolving structure of the “Farouk1986” communication network. For those not familiar with network visualization and analytic techniques—networks consist of both nodes and edges.
In the animation offered above, each “node” is an author. The labels of all best the most central authors have been removed for visibility purposes. Each “edge” is a weighted connection between two authors, where the weight is the strength of connection between each individual. Thus, within the communication network, thicker edges represent more communications while thinner edges reflect fewer communications.
In the visualization, you will notice most nodes are colored black. For purposes of ocular differentiation, the Farouk1986 node is colored red. In addition, we color direct communications with Farouk1986 in red and communications not directly involving Farouk1986 in black.
Given each forum post is datestamped, we can order the network such that the animation reflects the changing composition of the Farouk1986 online communication network. The datestamp is reflected in the upper left corner of animation. Our analysis is limited to the 2004-2005 time period when Farouk1986 was a regular participant.
The network is visualized in each time step using the Kamada-Kawai Visualization Algorithm. Kamada-Kawai is spring embedded force directed placement algorithm commonly used to visualize networks similar to the one considered herein. In order to smooth the visual while not undercutting the qualitatively results, we apply linear interpolation between frames.
10 Most Central Participants in the Farouk1986 Network
The following are the ten most central participants in the network, as measured by weighted eigenvector centrality:
| Author |
Centrality |
| Crystal Eyes |
1 |
| property_of_allah |
0.84 |
| Farouk1986 |
0.81 |
| amani |
0.69 |
| Mansoor Ansari |
0.61 |
| sis Qassab |
0.55 |
| muslim mujahid |
0.49 |
| Arwa |
0.43 |
| sister in islam |
0.31 |
| Anj |
0.29 |
Directions for Additional Analysis
(a) Computational Linguistic Analysis of the Underlying Posts
Over what substantive dimensions did these networks of direct and indirect communication form?
(b) Recursive Growth of the Network
Friends-Friends-Friends and so on….
(c) Complete Analysis of the Gawaher.com Forum
Were the patterns of communications by Farouk1986 noticeably different from other forum participants?
(d) Linkage of Content and Structure
What is the nature of information diffusion across the Gawaher.com?
How did this differ by substantive topic?