

Tag: Quantitative Finance
Law on the Market? Evaluating the Securities Market Impact Of Supreme Court Decisions (Katz, Bommarito, Soellinger & Chen)
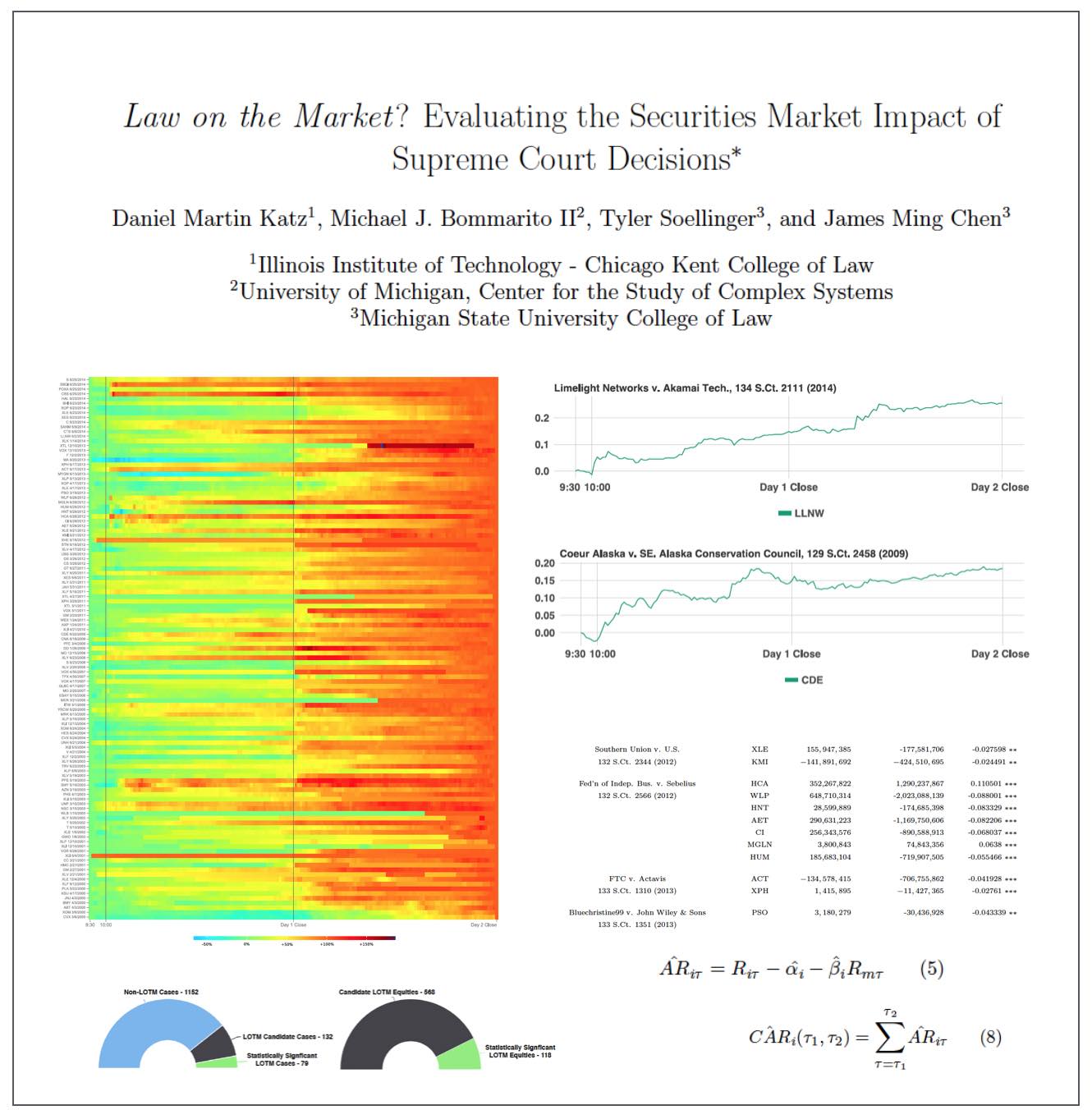
ABSTRACT: Do judicial decisions affect the securities markets in discernible and perhaps predictable ways? In other words, is there “law on the market” (LOTM)? This is a question that has been raised by commentators, but answered by very few in a systematic and financially rigorous manner. Using intraday data and a multiday event window, this large scale event study seeks to determine the existence, frequency and magnitude of equity market impacts flowing from Supreme Court decisions.
We demonstrate that, while certainly not present in every case, “law on the market” events are fairly common. Across all cases decided by the Supreme Court of the United States between the 1999-2013 terms, we identify 79 cases where the share price of one or more publicly traded company moved in direct response to a Supreme Court decision. In the aggregate, over fifteen years, Supreme Court decisions were responsible for more than 140 billion dollars in absolute changes in wealth. Our analysis not only contributes to our understanding of the political economy of judicial decision making, but also links to the broader set of research exploring the performance in financial markets using event study methods.
We conclude by exploring the informational efficiency of law as a market by highlighting the speed at which information from Supreme Court decisions is assimilated by the market. Relatively speaking, LOTM events have historically exhibited slow rates of information incorporation for affected securities. This implies a market ripe for arbitrage where an event-based trading strategy could be successful.
Available on SSRN and arXiv

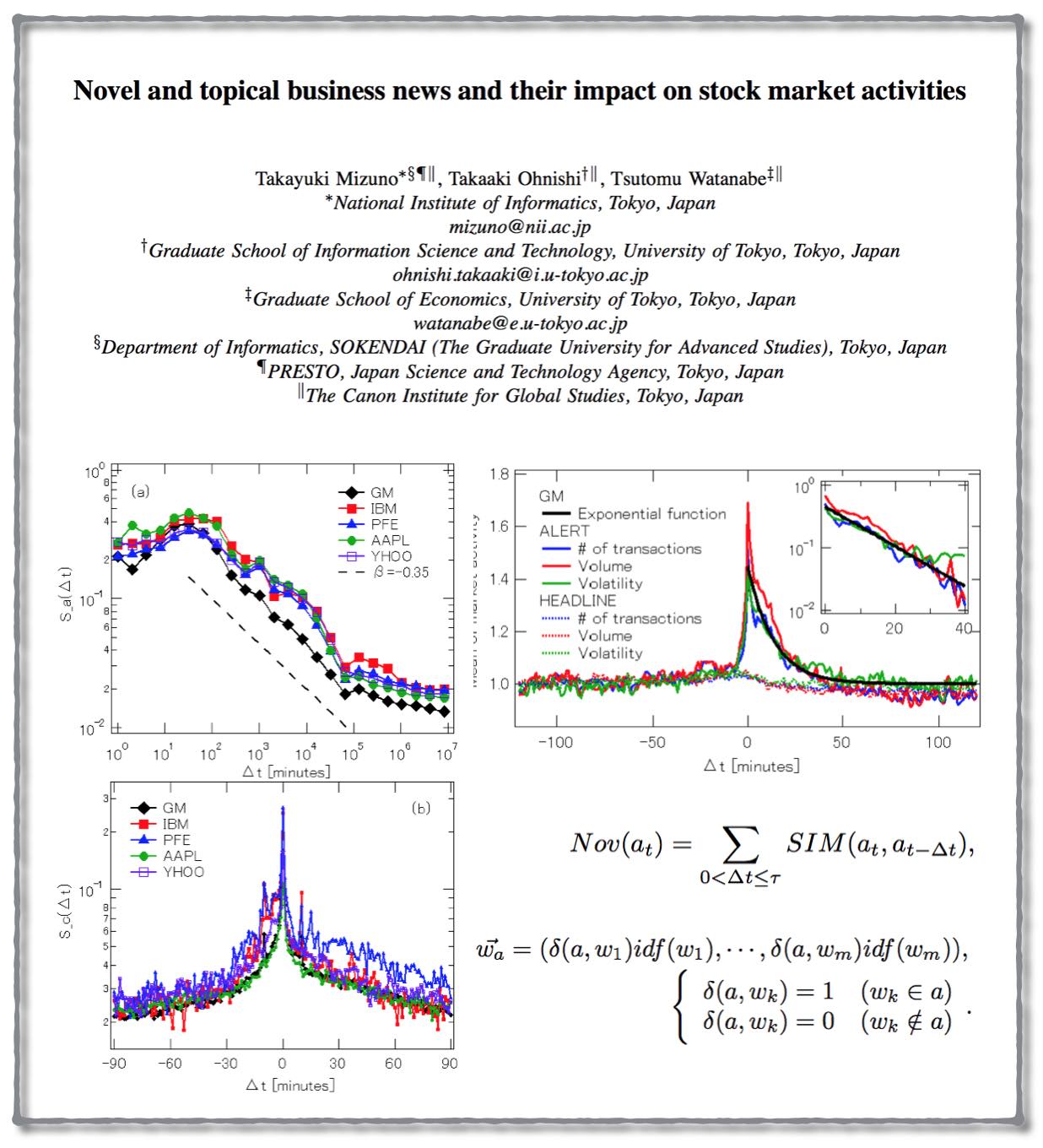
Twitter Mood Predicts the Stock Market

From the physics arXiv comes the interesting paper entitled Twitter mood predicts the stock market. Mike has additional information on the paper over at ETF Central. However — for those who might be interested — here is the abstract:
“Behavioral economics tells us that emotions can profoundly affect individual behavior and decision-making. Does this also apply to societies at large, i.e., can societies experience mood states that affect their collective decision making? By extension is the public mood correlated or even predictive of economic indicators? Here we investigate whether measurements of collective mood states derived from large-scale Twitter feeds are correlated to the value of the Dow Jones Industrial Average (DJIA) over time. We analyze the text content of daily Twitter feeds by two mood tracking tools, namely OpinionFinder that measures positive vs. negative mood and Google-Profile of Mood States (GPOMS) that measures mood in terms of 6 dimensions (Calm, Alert, Sure, Vital, Kind, and Happy). We cross-validate the resulting mood time series by comparing their ability to detect the public’s response to the presidential election and Thanksgiving day in 2008. A Granger causality analysis and a Self-Organizing Fuzzy Neural Network are then used to investigate the hypothesis that public mood states, as measured by the OpinionFinder and GPOMS mood time series, are predictive of changes in DJIA closing values. Our results indicate that the accuracy of DJIA predictions can be significantly improved by the inclusion of specific public mood dimensions but not others. We find an accuracy of 87.6% in predicting the daily up and down changes in the closing values of the DJIA and a reduction of the Mean Average Percentage Error by more than 6%.”
New Paper Available on SSRN: A Profitable Trading and Risk Management Strategy Despite Transaction Cost
Readers might be interested in an article that A. Duran and I have coming out in Quantitative Finance this year entitled A Profitable Trading and Risk Management Strategy Despite Transaction Cost. In the article, we develop a strategy which outperforms the “market” in rigorous out-of-sample testing. We’ve made sure to check the robustness of the results by performing Monte Carlo simulations on both the S&P 500 and Russell 2000 while varying the subsets of stocks and time periods used in the simulation.
The strategy is interesting in that it is based on behavioral patterns. Unlike many other algorithmic trading models, our strategy is modeled after a human trader with quarterly memory who categorizes the market return distribution and market risk into low, medium, and high categories. Technically, it accomplishes this by non-parametrically categorizing windowed estimates of the first four moments of the return distribution and the normalized leading eigenvalue of the windowed correlation matrix. Based on the assessment of these low/medium/high categories and past experience in similar states, the strategy then decides whether to invest in the market index, invest in the risk-free asset, or short the market. The strategy soundly outperforms the market index in multiple markets over random windows and on random subsets of stocks.
While you’re waiting for its publication in Quantitative Finance, you might check out a copy over at SSRN. Here’s the abstract and a figure below comparing the log-return of our strategy with the market over one realization:
We present a new profitable trading and risk management strategy with transaction cost for an adaptive equally weighted portfolio. Moreover, we implement a rule-based expert system for the daily financial decision making process by using the power of spectral analysis. We use several key components such as principal component analysis, partitioning, memory in stock markets, percentile for relative standing, the first four normalized central moments, learning algorithm, switching among several investments positions consisting of short stock market, long stock market and money market with real risk-free rates. We find that it is possible to beat the proxy for equity market without short selling for S&P 500-listed 168 stocks during the 1998-2008 period and Russell 2000-listed 213 stocks during the 1995-2007 period. Our Monte Carlo simulation over both the various set of stocks and the interval of time confirms our findings.

Is It Real, or Is It Randomized?: A Financial Turing Test
 From the abstract … “We construct a financial “Turing test” to determine whether human subjects can differentiate between actual vs. randomized financial returns. The experiment consists of an online video-game where players are challenged to distinguish actual financial market returns from random temporal permutations of those returns. We find overwhelming statistical evidence (p-values no greater than 0.5%) that subjects can consistently distinguish between the two types of time series, thereby refuting the widespread belief that financial markets “look random.” A key feature of the experiment is that subjects are given immediate feedback regarding the validity of their choices, allowing them to learn and adapt. We suggest that such novel interfaces can harness human capabilities to process and extract information from financial data in ways that computers cannot.”
From the abstract … “We construct a financial “Turing test” to determine whether human subjects can differentiate between actual vs. randomized financial returns. The experiment consists of an online video-game where players are challenged to distinguish actual financial market returns from random temporal permutations of those returns. We find overwhelming statistical evidence (p-values no greater than 0.5%) that subjects can consistently distinguish between the two types of time series, thereby refuting the widespread belief that financial markets “look random.” A key feature of the experiment is that subjects are given immediate feedback regarding the validity of their choices, allowing them to learn and adapt. We suggest that such novel interfaces can harness human capabilities to process and extract information from financial data in ways that computers cannot.”