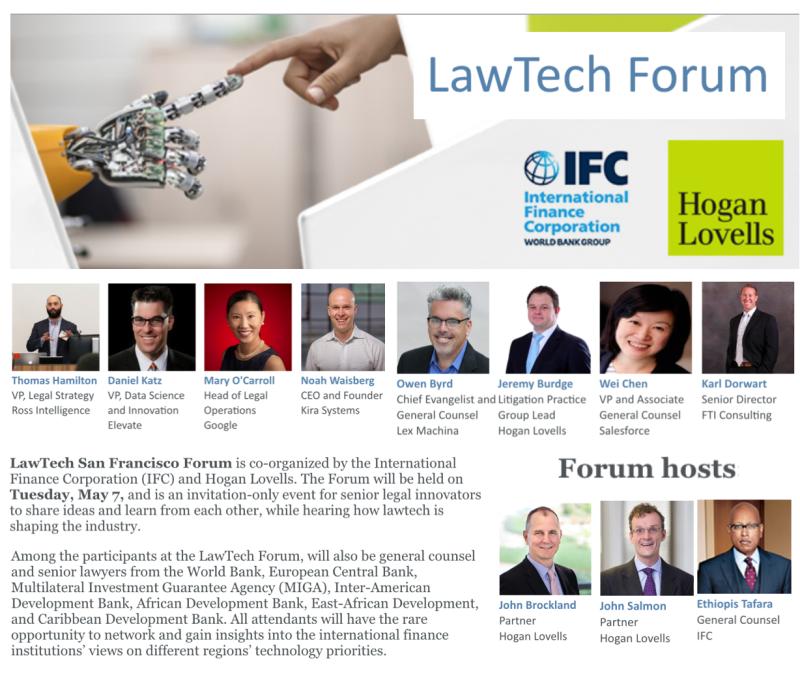
Today – I gave the Opening Keynote at LawTech San Francisco Forum – co-organized by the International Finance Corporation (World Bank Group) and Hogan Lovells.

Today – I gave the Opening Keynote at LawTech San Francisco Forum – co-organized by the International Finance Corporation (World Bank Group) and Hogan Lovells.

Today I am in Oslo giving the Keynote Address at the University of Oslo – Network Analysis and Machine Learning in Law Conference. Some very cool papers have been will be presented –https://www.jus.uio.no/
 My colleague Warren Agin from LexPredict — Predicts Chapter 13 Bankruptcy Cases Using Machine Learning – Learn More HERE – #AI #LegalAI #MachineLearning #LegalTech #LegalData
My colleague Warren Agin from LexPredict — Predicts Chapter 13 Bankruptcy Cases Using Machine Learning – Learn More HERE – #AI #LegalAI #MachineLearning #LegalTech #LegalData

We are very excited to welcome Warren E. Agin to the LexPredict team! Warren Agin joins LexPredict as Director of Professional Development and Senior Consultant. Warren is Founding Chair of the American Bar Association’s Legal Analytics Committee and serves Adjunct Professor at Boston College Law School where he teaches Legal Analytics. Warren is the author of a recent study which uses machine learning to predict outcomes in bankruptcy cases. Warren will bring nearly thirty years of legal practice experience to the LexPredict team.
#machinelearning #legaltech #legaldata #legalanalytics #legalinnovation
 Paper Abstract – LexNLP is an open source Python package focused on natural language processing and machine learning for legal and regulatory text. The package includes functionality to (i) segment documents, (ii) identify key text such as titles and section headings, (iii) extract over eighteen types of structured information like distances and dates, (iv) extract named entities such as companies and geopolitical entities, (v) transform text into features for model training, and (vi) build unsupervised and supervised models such as word embedding or tagging models. LexNLP includes pre-trained models based on thousands of unit tests drawn from real documents available from the SEC EDGAR database as well as various judicial and regulatory proceedings. LexNLP is designed for use in both academic research and industrial applications, and is distributed at https://github.com/LexPredict/lexpredict-lexnlp
Paper Abstract – LexNLP is an open source Python package focused on natural language processing and machine learning for legal and regulatory text. The package includes functionality to (i) segment documents, (ii) identify key text such as titles and section headings, (iii) extract over eighteen types of structured information like distances and dates, (iv) extract named entities such as companies and geopolitical entities, (v) transform text into features for model training, and (vi) build unsupervised and supervised models such as word embedding or tagging models. LexNLP includes pre-trained models based on thousands of unit tests drawn from real documents available from the SEC EDGAR database as well as various judicial and regulatory proceedings. LexNLP is designed for use in both academic research and industrial applications, and is distributed at https://github.com/LexPredict/lexpredict-lexnlp
 Yes – there is no easy button – but far more streamlining is coming and higher order work streams are on the march in data science …
Yes – there is no easy button – but far more streamlining is coming and higher order work streams are on the march in data science …

Academic Tour Continues – tomorrow I will be giving a talk at Bar Ilan University here in Tel Aviv at their Law & Big Data Workshop – it is looks like an good agenda with proper scientific papers with technical results / or discussions about methodology. #LegalScience #LegalData #LegalInformatics
 Tomorrow – it is my great pleasure to deliver the Keynote Address at one the first #LegalTech events in Lithuania. The event will be opened by the Mayor of Vilnius – Remigijus Šimašius and Lyra Jakulevičienė (Dean of the Mykolas Romeris University Law School). LegalTech is a global phenomenon!
Tomorrow – it is my great pleasure to deliver the Keynote Address at one the first #LegalTech events in Lithuania. The event will be opened by the Mayor of Vilnius – Remigijus Šimašius and Lyra Jakulevičienė (Dean of the Mykolas Romeris University Law School). LegalTech is a global phenomenon!
 It is my great pleasure to visit with Primerus and its associated law firms and deliver an address at its 2018 Annual PDI Convocation.
It is my great pleasure to visit with Primerus and its associated law firms and deliver an address at its 2018 Annual PDI Convocation.

CLOC Panel – Legal AI in Real Life — (Cisco, Liberty Mutual, Spotify) (I was filling in for Julian T. from Google) — I discussed the contract analytics project we are undertaking with Cisco / Elevate and other applied A.I. / Analytics Projects that the LexPredict Team is undertaking with corporate legal departments !