
Very happy to see this favorable ruling! Coverage in Bloomberg Law. I was one of 36 signatories to one of the Amicus Briefs in the case.

Very happy to see this favorable ruling! Coverage in Bloomberg Law. I was one of 36 signatories to one of the Amicus Briefs in the case.

It was my pleasure to deliver the opening keynote address at London CLOC 2020 ! #LegalTech #LegalData #LegalInnovation #LegalOps

Exciting day here at MIT Media Lab … thanks to Dazza Greenwood for hosting me … looking forward to future collaborations including the MIT Computational Law Report! It was particularly cool as I did author a paper called “The MIT School of Law” …
#ComputationalLaw #AI #Engineering #Computation #Science #Governance

Today is the day that SCOTUS considers Georgia v. Public.Resource.Org, Inc. (18-1150) — https://www.oyez.org/cases/2019/18-1150

Cryptoassets and Smart Contracts are Valid in English law (via The Law Society Gazette)

I am one of the 36 Scholars who have published Computational Law Papers and who are signatories to an Amicus Brief in State of Georgia vs Public.Resource.Org (case in front of the Supreme Court of the United States this term). The Link to the Amicus Brief is here. The Link to the Full List of Signatories is here.

Tomorrow it is the Block (Legal) Tech Conference at Illinois Tech – Chicago Kent College of Law … nearly 600+ registered to attend (overflow room will be available) … 20+ Speakers on One Stage discussing all things {Crypto + Law} from CryptoInfrastructure to CryptoLawyering to the Regulation of Distributed Ledger Technologies …. blocklegaltech.com
Thanks as always to our Sponsors for supporting our conference!
#LegalInnovation #LegalTech #FinLegalTech #Crypto #Cryptoeconomy #CryptoLawyering #CryptoInfrastructure

On the final leg of my European Visit, I was honored to participate in kickoff event for the new Maastricht Law & Tech Lab here at the St. Jan Church – today I talked about the {Past, Present & Future of NLP & Law} here at Maastricht University. Thanks to Gijs van Dijck Catalina Goanta Constanta Rosca and others from Maastricht for organizing the event! legaltech #legalinnovation #legaldata #AlforLaw
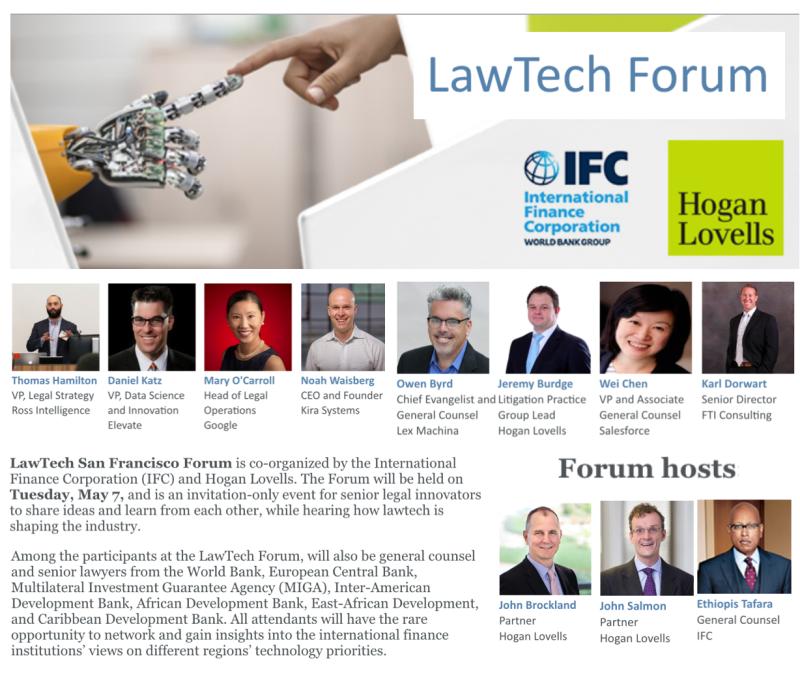
Today – I gave the Opening Keynote at LawTech San Francisco Forum – co-organized by the International Finance Corporation (World Bank Group) and Hogan Lovells.

Today I taught the Legal Prediction Module in the Legal Informatics Course at Stanford CodeX. Thanks to Roland Vogl, Michael Genesereth, Susan Salkind, Jameson Dempsey and the students for having me! #LegalInformatics #LegalTech #LegalData #LegalPrediction

It was a very nice day here at the 2019 Stanford CodeX Future Law Conference – connected with some old friends and new friends — Dirk Hartung Dazza Greenwood Pablo Arredondo Brian W Tang Jerrold Soh and many others !
 Today is the Computational Legal Studies Conference here at University of Hong Kong – a global gathering which seemed impossible when Mike Bommarito and I started our Comp Law Blog nearly 10 years ago …
Today is the Computational Legal Studies Conference here at University of Hong Kong – a global gathering which seemed impossible when Mike Bommarito and I started our Comp Law Blog nearly 10 years ago …
 Paper Abstract – LexNLP is an open source Python package focused on natural language processing and machine learning for legal and regulatory text. The package includes functionality to (i) segment documents, (ii) identify key text such as titles and section headings, (iii) extract over eighteen types of structured information like distances and dates, (iv) extract named entities such as companies and geopolitical entities, (v) transform text into features for model training, and (vi) build unsupervised and supervised models such as word embedding or tagging models. LexNLP includes pre-trained models based on thousands of unit tests drawn from real documents available from the SEC EDGAR database as well as various judicial and regulatory proceedings. LexNLP is designed for use in both academic research and industrial applications, and is distributed at https://github.com/LexPredict/lexpredict-lexnlp
Paper Abstract – LexNLP is an open source Python package focused on natural language processing and machine learning for legal and regulatory text. The package includes functionality to (i) segment documents, (ii) identify key text such as titles and section headings, (iii) extract over eighteen types of structured information like distances and dates, (iv) extract named entities such as companies and geopolitical entities, (v) transform text into features for model training, and (vi) build unsupervised and supervised models such as word embedding or tagging models. LexNLP includes pre-trained models based on thousands of unit tests drawn from real documents available from the SEC EDGAR database as well as various judicial and regulatory proceedings. LexNLP is designed for use in both academic research and industrial applications, and is distributed at https://github.com/LexPredict/lexpredict-lexnlp
