Perhaps some hyperbolic language in here but the basic idea is still intact … for law+economics / empirical legal studies – the causal inference versus machine learning point is expressed in detail in this paper called “Quantitative Legal Prediction.” Mike Bommarito and I have made this point in these slides, these slides, these slides, etc. Mike and I also make this point on Day 1 of our Legal Analytics Class (which really could be called “machine learning for lawyers”).
Perhaps some hyperbolic language in here but the basic idea is still intact … for law+economics / empirical legal studies – the causal inference versus machine learning point is expressed in detail in this paper called “Quantitative Legal Prediction.” Mike Bommarito and I have made this point in these slides, these slides, these slides, etc. Mike and I also make this point on Day 1 of our Legal Analytics Class (which really could be called “machine learning for lawyers”).
Tag: big data

15th International Conference on Artificial Intelligence & Law — San Diego (Final Day for Priority Registration)
 As a member of the local organizing committee, I just wanted to mention that today is the final day for priority registration for the International Conference on Artificial Intelligence & Law in San Diego.
As a member of the local organizing committee, I just wanted to mention that today is the final day for priority registration for the International Conference on Artificial Intelligence & Law in San Diego.
Amazon Introduces a Cloud Service for Machine Learning (via Venture Beat)
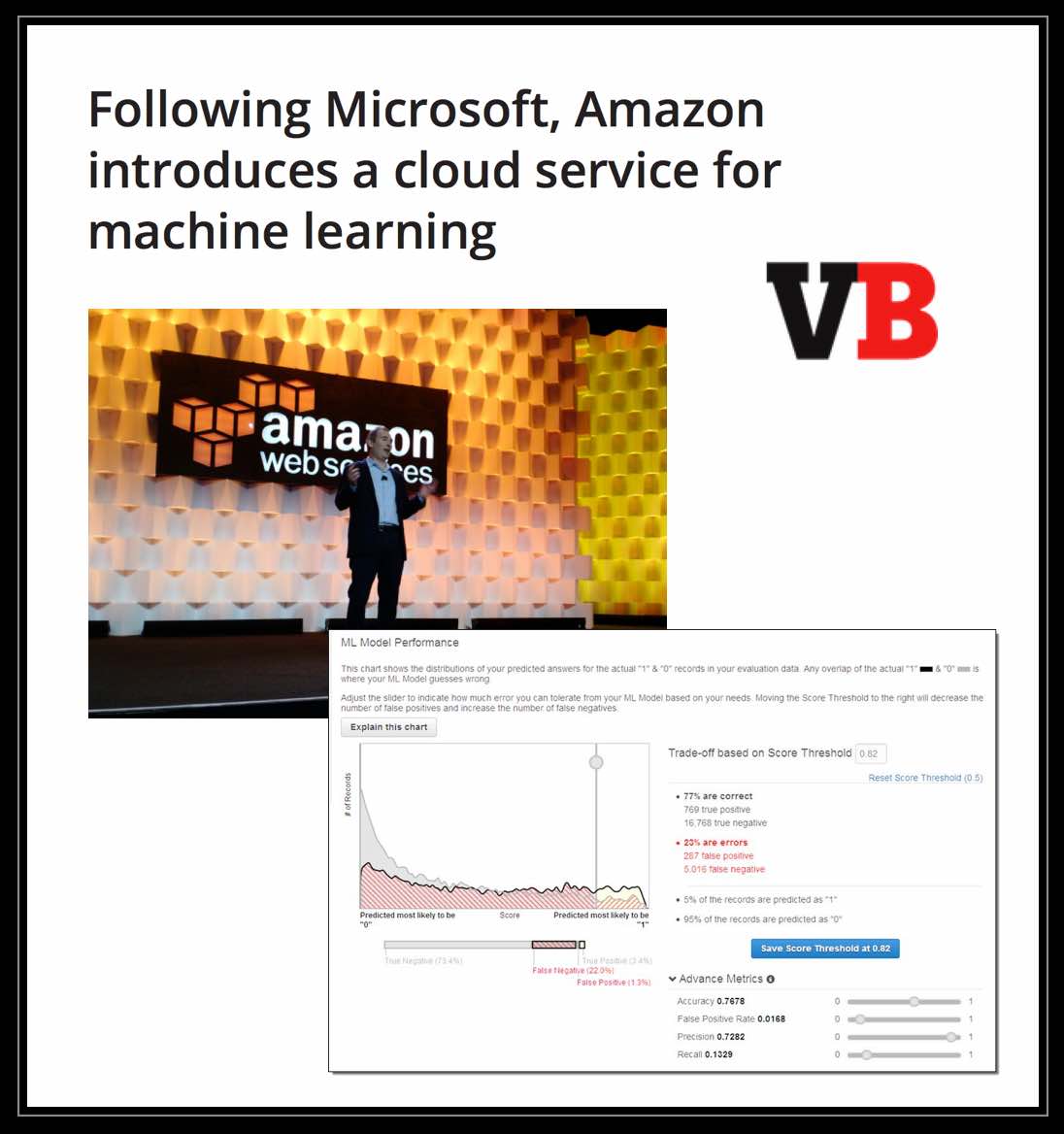
Suffice to say – this platform and competing platforms are going to collectively lower barriers to entry … and that is likely to have some implications (some good and some bad)

Legal Analytics – Introduction to the Course – Professors Daniel Martin Katz + Michael J Bommarito
Here is an introductory slide deck from “Legal Analytics” which is a course that Mike Bommarito and I are teaching this semester. Relevant legal applications include predictive coding in e-discovery (i.e. classification), early case assessment and overall case prediction, pricing and staff forecasting, prediction of judicial behavior, etc.
As I have written in my recent article in Emory Law Journal – we are moving into an era of data driven law practice. This course is a direct response to demands from relevant industry stakeholders. For a large number of prediction tasks … humans + machines > humans or machines working alone.
We believe this is the first ever Machine Learning Course offered to law students and it our goal to help develop the first wave of human capital trained to thrive as this this new data driven era takes hold. Richard Susskind likes to highlight this famous quote from Wayne Gretzky … “A good hockey player plays where the puck is. A great hockey player plays where the puck is going to be.”
Using R for Quantitative Methods for Lawyers and Legal Analytics Courses (Professors Katz + Bommarito)
 While its performance is sometimes problematic for some extremely large data problems, R (with R studio frontend) is the data science language du jour for many small to medium data problems. Among other things, R is great because it is open source, hyper customizable with thousands of packages available to be loaded for a specific problem.
While its performance is sometimes problematic for some extremely large data problems, R (with R studio frontend) is the data science language du jour for many small to medium data problems. Among other things, R is great because it is open source, hyper customizable with thousands of packages available to be loaded for a specific problem.
While Python and SQL are also important parts of the overall data science toolkit, we use R as our preferred language in both Quantitative Methods for Lawyers (3 credits) as well as in our Legal Analytics course (2 credits). We have found that students who are diligent can make amazing strides in a relatively short amount of time. For example, see this final project by Pat Ellis from last year’s course.
Here are some introductory resources that we have developed to get folks started: Loading R and R Studio
R Boot Camp – Part 1 – Loading Datasets and Basic Data Exploration
Data Cleaning and Additional Resources
R Boot Camp – Part 2 – Statistical Tests Using R
Basic Data Visualization in R
Scatter Plots, Covariance, Correlation Using R
Intro to Regression Analysis Using R
Over the balance of the 2014-2015 academic year, Mike and I will be introducing a variety of new things to the quantitative sequence including dplyR, etc. … more to come …
Five Observations Regarding Technology and the Legal Industry – My Keynote Presentation at Legal Week Global Corporate Counsel Forum – NYC 2014
It has been an exciting few days here in NYC as I was able to speak at the Legal Week Global Corporate Counsel Forum and also attend part of the IBM Watson launch at 51 Astor Place in NYC.
Law Under the Data Deluge
Examples Law + Society as well as the Future of the Legal Profession including work by {Dazza Greenword @ MIT Media Lab, Us (i.e. Mike Bommarito and Dan Katz)} as well as many others …

This Computer Program Can Predict 7 out of 10 Supreme Court Decisions (via Vox.com)
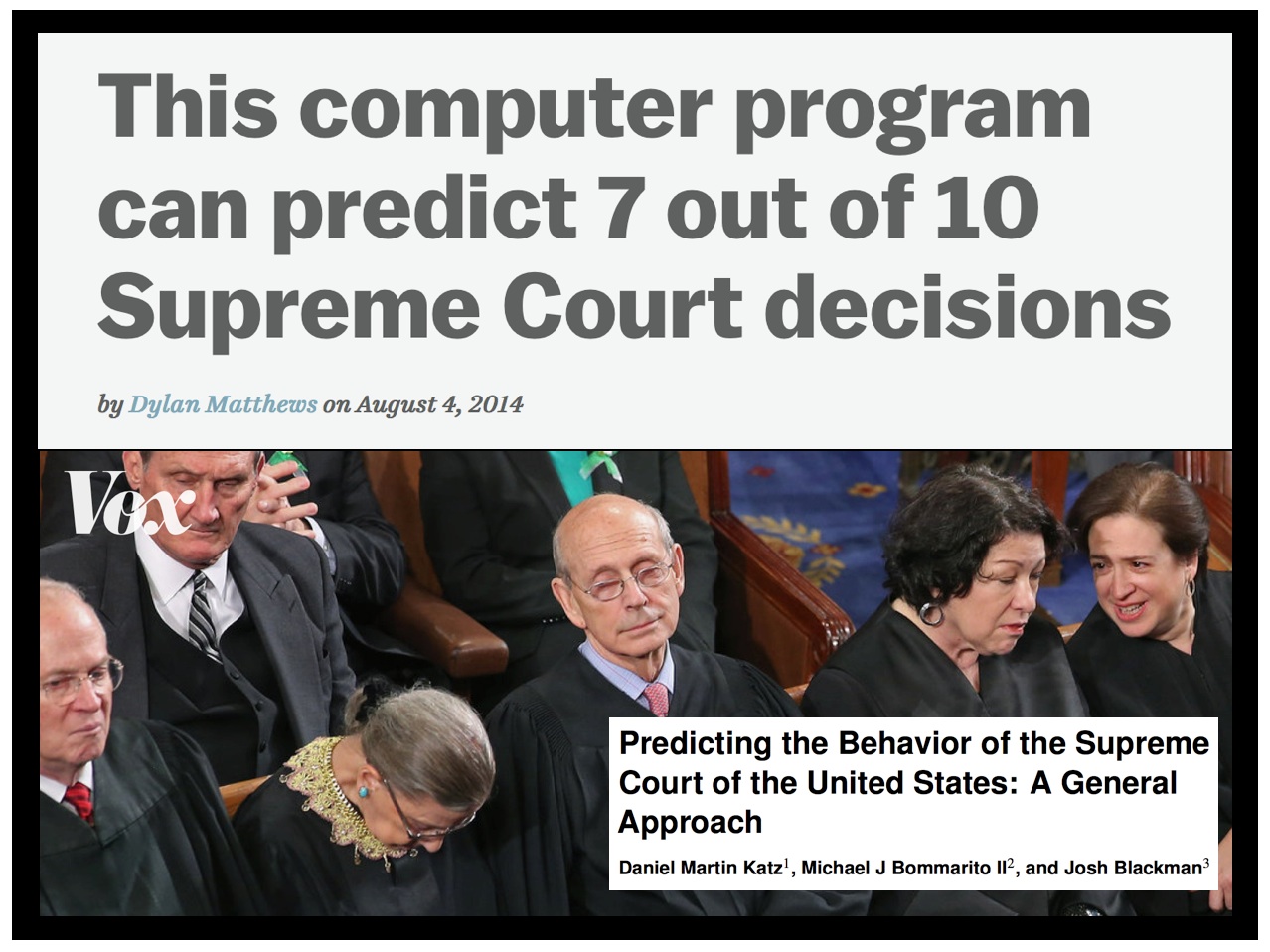 The story is here. Full form interview with Mike + Josh is here. (I unfortunately could not participate because I was teaching my ICPSR class). Our paper is available on SSRN and on the physics arXiv.
The story is here. Full form interview with Mike + Josh is here. (I unfortunately could not participate because I was teaching my ICPSR class). Our paper is available on SSRN and on the physics arXiv.
Predicting the Behavior of the Supreme Court of the United States: A General Approach (Katz, Bommarito & Blackman)

Abstract: “Building upon developments in theoretical and applied machine learning, as well as the efforts of various scholars including Guimera and Sales-Pardo (2011), Ruger et al. (2004), and Martin et al. (2004), we construct a model designed to predict the voting behavior of the Supreme Court of the United States. Using the extremely randomized tree method first proposed in Geurts, et al. (2006), a method similar to the random forest approach developed in Breiman (2001), as well as novel feature engineering, we predict more than sixty years of decisions by the Supreme Court of the United States (1953-2013). Using only data available prior to the date of decision, our model correctly identifies 69.7% of the Court’s overall affirm and reverse decisions and correctly forecasts 70.9% of the votes of individual justices across 7,700 cases and more than 68,000 justice votes. Our performance is consistent with the general level of prediction offered by prior scholars. However, our model is distinctive as it is the first robust, generalized, and fully predictive model of Supreme Court voting behavior offered to date. Our model predicts six decades of behavior of thirty Justices appointed by thirteen Presidents. With a more sound methodological foundation, our results represent a major advance for the science of quantitative legal prediction and portend a range of other potential applications, such as those described in Katz (2013).”
You can access the current draft of the paper via SSRN or via the physics arXiv. Full code is publicly available on Github. See also the LexPredict site. More on this to come soon …
Teaching the Complex Systems Course @ University of Michigan ICPSR Summer Program in Quantitative Methods
 This upcoming week and next week I have the pleasure of teaching “Complex Systems Models in the Social Sciences” here at the University of Michigan ICPSR Summer Program in Quantitative Methods. The field of complex systems is very diverse and it is difficult to do complete justice to the range of scholarship conducted under this umbrella in a short survey course. However, we strive to cover the canonical topics such as computational game theory and computational modeling, network science, natural language processing, randomness vs. determinism, diffusion, cascades, emergence, empirical approaches to study complexity (including measurement), social epidemiology, non-linear dynamics, etc. Click here or on the image above to access my course materials!
This upcoming week and next week I have the pleasure of teaching “Complex Systems Models in the Social Sciences” here at the University of Michigan ICPSR Summer Program in Quantitative Methods. The field of complex systems is very diverse and it is difficult to do complete justice to the range of scholarship conducted under this umbrella in a short survey course. However, we strive to cover the canonical topics such as computational game theory and computational modeling, network science, natural language processing, randomness vs. determinism, diffusion, cascades, emergence, empirical approaches to study complexity (including measurement), social epidemiology, non-linear dynamics, etc. Click here or on the image above to access my course materials!